Joint Embedding of Words and Labels for Text Classification(ACL 2018)
论文原文:
https://arxiv.org/abs/1805.04174
代码链接:
https://github.com/guoyinwang/LEAM
论文动机:
标签嵌入(Label embedding )已被证明在多个领域和任务中是有效的。在CV中,已经有大量关于利用标签嵌入进行图片分类、图像和文本间的多模态学习、图像中的文本识别的研究。
有大量关于词嵌入的研究,但是关于标签嵌入的研究很少。标签对分类性能起着重要的作用,但在之前的工作中标签仅起监督作用。对标签嵌入设计高效注意模型的有效性研究很少,如何将单词与标签联合嵌入,充分利用标签信息进行文本分类还未见研究。
该论文将文本分类看作一个标签-单词的联合嵌入问题:每个标签与单词向量嵌入在同一个空间,提出了一个attention框架,它度量文本序列和标签嵌入之间的兼容性。attention是在一组带标签的训练样本上学习的,以确保给定一个文本序列,相关单词的权重高于不相关单词。该方法保持了单词嵌入的可解释性,并具有利用输入文本序列之外的其他信息的能力。我们的注意模型直接建立在单词和标签的联合嵌入空间中,上下文由标签嵌入指定。
典型的文本分类流程:
- 用词嵌入矩阵P*L(每一列为一个词向量)表示文本序列,P为词向量维度,L为文本的长度。
- 通过神经网络等方法将词嵌入矩阵P*L变为定长的向量表示z。
- 将定长向量z传入分类器(常用softmax),获得分类概率分布向量。
之前的工作只要集中在如何表示单词嵌入和句子嵌入,即1和2两个步骤。很多工作都证明了预训练词向量的有效性,因此通常使用在大型语料库上离线训练得到词向量,然后在模型训练时进行特定于任务的微调。
注意力机制可以更加灵活的表征文本特征,训练该模型可以捕捉到对目标任务具有重要贡献的依赖关系,而不用考虑序列中元素之间的距离,这样可以为具有距离依赖的模型(CNN,RNN)提供补充信息,因此Attention机制经常用于步骤2,但注意力机制在提高表征能力的同时使得模型的复杂度也随之增加。
LEAM架构:

在典型的文本分类流程中,仅在最后一步将标签作为监督信息学习,标签在前面两步的作用被直接忽略。LEAM在每个步骤中均使用标签信息:
- 除了使用词嵌入矩阵外,也将标签信息嵌入到同一空间,作为类别的“锚点”精细化词嵌入。
- 使用神经网络将单词嵌入到向量z中,并根据标签和单词之间的兼容性进行加权。
- 将定长向量z传入分类器(常用softmax),获得分类概率分布向量。
标签嵌入注意力模型的具体描述:
1、词和标签的联合嵌入
将词和嵌入到同一空间,句子的词嵌入矩阵使用预训练词向量初始化(300d Glove)。对于有描述的类标签(类标签是词)使用每个标签对应的预先训练好的单词嵌入(300d Glove)作为标签嵌入的初始化。对于没有代表性类描述(标签为数字等情况)的数据集,可以将标签嵌入初始化为从标准高斯分布中抽取的随机样本。
2、利用标签信息对词嵌入矩阵进行加权
首先计算![]() ,其中
,其中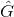 为大小为K×L的归一化矩阵,每个元素为第c个标签嵌入和第L个单词嵌入的
为大小为K×L的归一化矩阵,每个元素为第c个标签嵌入和第L个单词嵌入的 norms的乘积:
norms的乘积:![]() 。然后利用G计算权重向量
。然后利用G计算权重向量 ,计算过程如下:
,计算过程如下:
![]()
其中,![]() ,
,![]() 均为需要学习的参数,
均为需要学习的参数,![]() 为以词l为中心的片段,求得的
为以词l为中心的片段,求得的![]() 。
。
![]()
m是一个长度为L的向量,文本序列的attention score 为:
![]()
文本表示通过基于标签的attention score加权词嵌入获得:
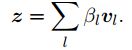
实验结果&分析:
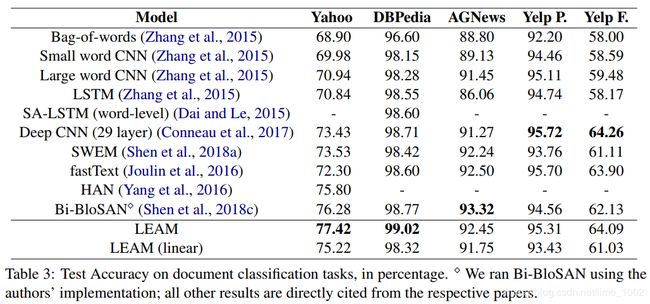
1、简单的合成方法确实可以获得与复杂的深度CNN/RNN模型相当的性能。(fastText)
2、深层次的注意模型可以对纯CNN/RNN模型进行改进。最近提出的自注意网络一般比以前的方法具有更高的精度.
3、LEAM在两个最大的数据集上(雅虎和DBPedia)性能最优。在其他数据集,LEAM在精度上排名第二或第三,与top 1方法相似。
在AGNews、Yelp P.、Yelp F.上性能并非最优的原因分析:1、AGNews、Yelp P.、Yelp F.数据集中类的数量少。2、在学习过程中,标签嵌入初始化没有显式的对应词嵌入。

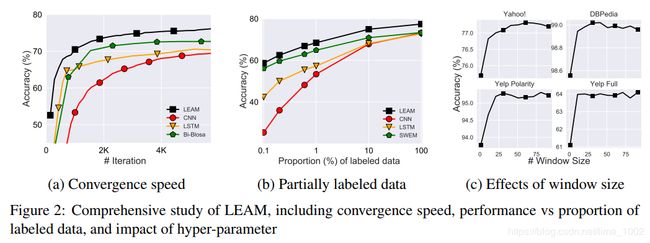
通过比较模型大小和时间成本以及收敛速度,我们认为LEAM有利于文本分类。与其他模型相比,LEAM使用更少的模型参数,并且收敛速度快,LEAM保持了SWEM的简单性和低成本。论文还比较了仅标记部分数据集时的性能,结果如图2(b)所示。在不同比例的标记数据下,LEAM始终优于其他方法。

为了深入了解学习表示的意义,基于Yahoo d数据集可视化了标签嵌入和文档嵌入之间的关系。(a)为每类全部文本表示的平均值和标签嵌入的余弦相似度矩阵。行是每个类的平均文档嵌入,列是标签嵌入。对角线元素衡量标签嵌入描述其自己的类的代表性,非对角线元素反映标签嵌入与其他类的不同。对角线元素数值高,非对角线元素数值低,表明了LEAM学习标签嵌入的能力。
此外,由于文档和标签嵌入都存在于相同的高维度中,使用t-SNE在2D地图上可视化对其进行了可视化,结果如图Figure 3(b)所示。
LEAM总结:
- Label-attention的文本表示对于下游分类任务是有信息的,因为它直接从共享的联合空间学习。
- 学习过程只涉及一系列基本的代数运算,因此它保留了简单模型的可解释性,特别是当标签描述可用时。
- 与相关方法相比,本文的注意力机制具有更少的参数和更少的计算,因此与复杂的深度注意力模型相比,我们的训练和测试成本都要低得多。
- 对几个文本分类任务进行了广泛的实验,证明了LEAM的有效性。
- 将LEAM应用于临床文本,attentive 模型可以突出预测的信息关键字,这在实践中可以减少医生阅读临床笔记的负担。