inception-v3模型神经网络图片识别系统搭建详细流程(1)
阅读前提示:代码复制过来时带有行号,运行本文程序需要自行删除行号并检查是否存在缩进错误。本文整理了该模型的运行经验,经过验证可行。
本文详细介绍了基于inception-v3模型的神经网络图片识别系统搭建过程。
1. 系统搭建
进行系统搭建前,需要配置文件夹,如图1,介绍了工程的文件架构。
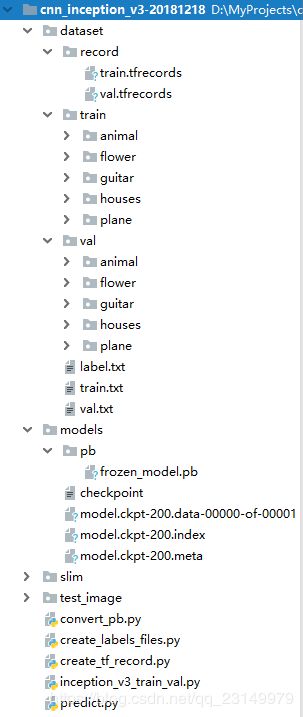
工程名称为cnn_inception_v3-20181218。
说明如下:
|-dataset #存放数据集
|-record #存放record文件
train.tfrecords #train的record文件
val.tfrecords #val的record文件
|-train #存放用于训练的图片,按类存取,共5类。
|-animal #存放若干张动物的图片
|-flower
|-guitar
|-houses
|-plane
|-val #存放用于评价的图片,按类存取,共5类。
|-animal
|-flower
|-guitar
|-houses
|-plane
label.txt #存放5个标签名称
train.txt #存放训练数据集标签
val.txt #存放评价数据集标签
|-models #存放模型
|-pb #存放pb模型
frozen_model.pb #训练获取的pb模型
checkpoint #检查点文件,文件保存了一个目录下所有的模型文件列表。
model.ckpt-200.data-00000-of-00001 #保存模型中每个变量的取值
model.ckpt-200.index
model.ckpt-200.meta #文件保存了TensorFlow计算图的结构,可以理解为神经网络
#的网络结构,该文件可以被 tf.train.import_meta_graph 加载
#到当前默认的图来使用。
|-slim #存放slim函数库
|-test_image #存放测试的文件
convert_pb.py #将ckpt模型转化为pb模型
create_labels_files.py #将数据创建标签
create_tf_record.py #将数据转化为record格式
inception_v3_train_val.py #训练数据
predict.py #测试模型
1.1 创建数据标签
在dataset/train和dataset/val文件下存放图片数据集,共有五类图片,分别是:flower、guitar、animal、houses和plane,每组数据集大概有800张左右。create_labels_files.py可以直接生成训练train和验证val的数据集txt文件。
create_labels_files.py代码如下:
1. #调入库
2. import os
3. # os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
4. import os.path
5.
6. def write_txt(content, filename, mode='w'):
7. """保存txt数据
8. :param content:需要保存的数据,type->list
9. :param filename:文件名
10. :param mode:读写模式:'w' or 'a'
11. :return: void
12. """
13. with open(filename, mode) as f:
14. for line in content:
15. str_line = ""
16. for col, data in enumerate(line):
17. if not col == len(line) - 1:
18. # 以空格作为分隔符
19. str_line = str_line + str(data) + " "
20. else:
21. # 每行最后一个数据用换行符“\n”
22. str_line = str_line + str(data) + "\n"
23. f.write(str_line)
24.
25.
26. def get_files_list(dir):
27. '''
28. 实现遍历dir目录下,所有文件(包含子文件夹的文件)
29. :param dir:指定文件夹目录
30. :return:包含所有文件的列表->list
31. '''
32. # parent:父目录, filenames:该目录下所有文件夹,filenames:该目录下的文件名
33. files_list = []
34. for parent, dirnames, filenames in os.walk(dir):
35. for filename in filenames:
36. # print("parent is: " + parent)
37. # print("filename is: " + filename)
38. # print(os.path.join(parent, filename)) # 输出rootdir路径下所有文件(包含子文件)信息
39. curr_file = parent.split(os.sep)[-1]
40. if curr_file == 'flower':
41. labels = 0
42. elif curr_file == 'guitar':
43. labels = 1
44. elif curr_file == 'animal':
45. labels = 2
46. elif curr_file == 'houses':
47. labels = 3
48. elif curr_file == 'plane':
49. labels = 4
50. files_list.append([os.path.join(curr_file, filename), labels])
51. return files_list
52.
53.
54. if __name__ == '__main__':
55. train_dir = 'dataset/train'
56. train_txt = 'dataset/train.txt'
57. train_data = get_files_list(train_dir)
58. write_txt(train_data, train_txt, mode='w')
59.
60. val_dir = 'dataset/val'
61. val_txt = 'dataset/val.txt'
62. val_data = get_files_list(val_dir)
63. write_txt(val_data, val_txt, mode='w')
1.2 制作tfrecords数据格式
有了 train.txt和val.txt数据集,我们就可以制作train.tfrecords和val.tfrecords文件了,create_tf_record.py如下。
1. #图片转向量函数
2. # -*-coding: utf-8 -*-
3. """
4. @Project: create_tfrecord
5. @File : create_tfrecord.py
6. @Author : panjq
7. @E-mail : pan_jinquan@163.com
8. @Date : 2018-07-27 17:19:54
9. @desc : 将图片数据保存为单个tfrecord文件
10. """
11.
12. ##########################################################################
13.
14. import tensorflow as tf
15. import numpy as np
16. import os
17. import cv2
18. import matplotlib.pyplot as plt
19. import random
20. from PIL import Image
21.
22.
23. ##########################################################################
24. def _int64_feature(value):
25. return tf.train.Feature(int64_list=tf.train.Int64List(value=[value]))
26. # 生成字符串型的属性
27. def _bytes_feature(value):
28. return tf.train.Feature(bytes_list=tf.train.BytesList(value=[value]))
29. # 生成实数型的属性
30. def float_list_feature(value):
31. return tf.train.Feature(float_list=tf.train.FloatList(value=value))
32.
33. def get_example_nums(tf_records_filenames):
34. '''
35. 统计tf_records图像的个数(example)个数
36. :param tf_records_filenames: tf_records文件路径
37. :return:
38. '''
39. nums= 0
40. for record in tf.python_io.tf_record_iterator(tf_records_filenames):
41. nums += 1
42. return nums
43.
44. def show_image(title,image):
45. '''
46. 显示图片
47. :param title: 图像标题
48. :param image: 图像的数据
49. :return:
50. '''
51. # plt.figure("show_image")
52. # print(image.dtype)
53. plt.imshow(image)
54. plt.axis('on') # 关掉坐标轴为 off
55. plt.title(title) # 图像题目
56. plt.show()
57.
58. def load_labels_file(filename,labels_num=1,shuffle=False):
59. '''
60. 载图txt文件,文件中每行为一个图片信息,且以空格隔开:图像路径 标签1 标签2,如:test_image/1.jpg 0 2
61. :param filename:
62. :param labels_num :labels个数
63. :param shuffle :是否打乱顺序
64. :return:images type->list
65. :return:labels type->list
66. '''
67. images=[]
68. labels=[]
69. with open(filename) as f:
70. lines_list=f.readlines()
71. if shuffle:
72. random.shuffle(lines_list)
73.
74. for lines in lines_list:
75. line=lines.rstrip().split(' ')
76. label=[]
77. for i in range(labels_num):
78. label.append(int(line[i+1]))
79. images.append(line[0])
80. labels.append(label)
81. return images,labels
82.
83. def read_image(filename, resize_height, resize_width,normalization=False):
84. '''
85. 读取图片数据,默认返回的是uint8,[0,255]
86. :param filename:
87. :param resize_height:
88. :param resize_width:
89. :param normalization:是否归一化到[0.,1.0]
90. :return: 返回的图片数据
91. '''
92.
93. bgr_image = cv2.imread(filename)
94. if len(bgr_image.shape)==2:#若是灰度图则转为三通道
95. print("Warning:gray image",filename)
96. bgr_image = cv2.cvtColor(bgr_image, cv2.COLOR_GRAY2BGR)
97.
98. rgb_image = cv2.cvtColor(bgr_image, cv2.COLOR_BGR2RGB)#将BGR转为RGB
99. # show_image(filename,rgb_image)
100. # rgb_image=Image.open(filename)
101. if resize_height>0 and resize_width>0:
102. rgb_image=cv2.resize(rgb_image,(resize_width,resize_height))
103. rgb_image=np.asanyarray(rgb_image)
104. if normalization:
105. # 不能写成:rgb_image=rgb_image/255
106. rgb_image=rgb_image/255.0
107. # show_image("src resize image",image)
108. return rgb_image
109.
110.
111. def get_batch_images(images,labels,batch_size,labels_nums,one_hot=False,shuffle=False,num_threads=1):
112. '''
113. :param images:图像
114. :param labels:标签
115. :param batch_size:
116. :param labels_nums:标签个数
117. :param one_hot:是否将labels转为one_hot的形式
118. :param shuffle:是否打乱顺序,一般train时shuffle=True,验证时shuffle=False
119. :return:返回batch的images和labels
120. '''
121. min_after_dequeue = 200
122. capacity = min_after_dequeue + 3 * batch_size # 保证capacity必须大于min_after_dequeue参数值
123. if shuffle:
124. images_batch, labels_batch = tf.train.shuffle_batch([images,labels],
125. batch_size=batch_size,
126. capacity=capacity,
127. min_after_dequeue=min_after_dequeue,
128. num_threads=num_threads)
129. else:
130. images_batch, labels_batch = tf.train.batch([images,labels],
131. batch_size=batch_size,
132. capacity=capacity,
133. num_threads=num_threads)
134. if one_hot:
135. labels_batch = tf.one_hot(labels_batch, labels_nums, 1, 0)
136. return images_batch,labels_batch
137.
138. def read_records(filename,resize_height, resize_width,type=None):
139. '''
140. 解析record文件:源文件的图像数据是RGB,uint8,[0,255],一般作为训练数据时,需要归一化到[0,1]
141. :param filename:
142. :param resize_height:
143. :param resize_width:
144. :param type:选择图像数据的返回类型
145. None:默认将uint8-[0,255]转为float32-[0,255]
146. normalization:归一化float32-[0,1]
147. centralization:归一化float32-[0,1],再减均值中心化
148. :return:
149. '''
150. # 创建文件队列,不限读取的数量
151. filename_queue = tf.train.string_input_producer([filename])
152. # create a reader from file queue
153. reader = tf.TFRecordReader()
154. # reader从文件队列中读入一个序列化的样本
155. _, serialized_example = reader.read(filename_queue)
156. # get feature from serialized example
157. # 解析符号化的样本
158. features = tf.parse_single_example(
159. serialized_example,
160. features={
161. 'image_raw': tf.FixedLenFeature([], tf.string),
162. 'height': tf.FixedLenFeature([], tf.int64),
163. 'width': tf.FixedLenFeature([], tf.int64),
164. 'depth': tf.FixedLenFeature([], tf.int64),
165. 'label': tf.FixedLenFeature([], tf.int64)
166. }
167. )
168. tf_image = tf.decode_raw(features['image_raw'], tf.uint8)#获得图像原始的数据
169.
170. tf_height = features['height']
171. tf_width = features['width']
172. tf_depth = features['depth']
173. tf_label = tf.cast(features['label'], tf.int32)
174. # PS:恢复原始图像数据,reshape的大小必须与保存之前的图像shape一致,否则出错
175. # tf_image=tf.reshape(tf_image, [-1]) # 转换为行向量
176. tf_image=tf.reshape(tf_image, [resize_height, resize_width, 3]) # 设置图像的维度
177.
178. # 恢复数据后,才可以对图像进行resize_images:输入uint->输出float32
179. # tf_image=tf.image.resize_images(tf_image,[224, 224])
180.
181. # 存储的图像类型为uint8,tensorflow训练时数据必须是tf.float32
182. if type is None:
183. tf_image = tf.cast(tf_image, tf.float32)
184. elif type=='normalization':# [1]若需要归一化请使用:
185. # 仅当输入数据是uint8,才会归一化[0,255]
186. # tf_image = tf.image.convert_image_dtype(tf_image, tf.float32)
187. tf_image = tf.cast(tf_image, tf.float32) * (1. / 255.0) # 归一化
188. elif type=='centralization':
189. # 若需要归一化,且中心化,假设均值为0.5,请使用:
190. tf_image = tf.cast(tf_image, tf.float32) * (1. / 255) - 0.5 #中心化
191.
192. # 这里仅仅返回图像和标签
193. # return tf_image, tf_height,tf_width,tf_depth,tf_label
194. return tf_image,tf_label
195.
196.
197. def create_records(image_dir,file, output_record_dir, resize_height, resize_width,shuffle,log=5):
198. '''
199. 实现将图像原始数据,label,长,宽等信息保存为record文件
200. 注意:读取的图像数据默认是uint8,再转为tf的字符串型BytesList保存,解析请需要根据需要转换类型
201. :param image_dir:原始图像的目录
202. :param file:输入保存图片信息的txt文件(image_dir+file构成图片的路径)
203. :param output_record_dir:保存record文件的路径
204. :param resize_height:
205. :param resize_width:
206. PS:当resize_height或者resize_width=0是,不执行resize
207. :param shuffle:是否打乱顺序
208. :param log:log信息打印间隔
209. '''
210. # 加载文件,仅获取一个label
211. images_list, labels_list=load_labels_file(file,1,shuffle)
212.
213. writer = tf.python_io.TFRecordWriter(output_record_dir)
214. for i, [image_name, labels] in enumerate(zip(images_list, labels_list)):
215. image_path=os.path.join(image_dir,images_list[i])
216. if not os.path.exists(image_path):
217. print('Err:no image',image_path)
218. continue
219. image = read_image(image_path, resize_height, resize_width)
220. image_raw = image.tostring()
221. if i%log==0 or i==len(images_list)-1:
222. print('------------processing:%d-th------------' % (i))
223. print('current image_path=%s' % (image_path),'shape:{}'.format(image.shape),'labels:{}'.format(labels))
224. # 这里仅保存一个label,多label适当增加"'label': _int64_feature(label)"项
225. label=labels[0]
226. example = tf.train.Example(features=tf.train.Features(feature={
227. 'image_raw': _bytes_feature(image_raw),
228. 'height': _int64_feature(image.shape[0]),
229. 'width': _int64_feature(image.shape[1]),
230. 'depth': _int64_feature(image.shape[2]),
231. 'label': _int64_feature(label)
232. }))
233. writer.write(example.SerializeToString())
234. writer.close()
235.
236. def disp_records(record_file,resize_height, resize_width,show_nums=4):
237. '''
238. 解析record文件,并显示show_nums张图片,主要用于验证生成record文件是否成功
239. :param tfrecord_file: record文件路径
240. :return:
241. '''
242. # 读取record函数
243. tf_image, tf_label = read_records(record_file,resize_height,resize_width,type='normalization')
244. # 显示前4个图片
245. init_op = tf.initialize_all_variables()
246. with tf.Session() as sess:
247. sess.run(init_op)
248. coord = tf.train.Coordinator()
249. threads = tf.train.start_queue_runners(sess=sess, coord=coord)
250. for i in range(show_nums):
251. image,label = sess.run([tf_image,tf_label]) # 在会话中取出image和label
252. # image = tf_image.eval()
253. # 直接从record解析的image是一个向量,需要reshape显示
254. # image = image.reshape([height,width,depth])
255. print('shape:{},tpye:{},labels:{}'.format(image.shape,image.dtype,label))
256. # pilimg = Image.fromarray(np.asarray(image_eval_reshape))
257. # pilimg.show()
258. show_image("image:%d"%(label),image)
259. coord.request_stop()
260. coord.join(threads)
261.
262.
263. def batch_test(record_file,resize_height, resize_width):
264. '''
265. :param record_file: record文件路径
266. :param resize_height:
267. :param resize_width:
268. :return:
269. :PS:image_batch, label_batch一般作为网络的输入
270. '''
271. # 读取record函数
272. tf_image,tf_label = read_records(record_file,resize_height,resize_width,type='normalization')
273. image_batch, label_batch= get_batch_images(tf_image,tf_label,batch_size=4,labels_nums=5,one_hot=False,shuffle=False)
274.
275. init = tf.global_variables_initializer()
276. with tf.Session() as sess: # 开始一个会话
277. sess.run(init)
278. coord = tf.train.Coordinator()
279. threads = tf.train.start_queue_runners(coord=coord)
280. for i in range(4):
281. # 在会话中取出images和labels
282. images, labels = sess.run([image_batch, label_batch])
283. # 这里仅显示每个batch里第一张图片
284. show_image("image", images[0, :, :, :])
285. print('shape:{},tpye:{},labels:{}'.format(images.shape,images.dtype,labels))
286.
287. # 停止所有线程
288. coord.request_stop()
289. coord.join(threads)
290.
291.
292. if __name__ == '__main__':
293. # 参数设置
294.
295. resize_height = 224 # 指定存储图片高度
296. resize_width = 224 # 指定存储图片宽度
297. shuffle=True
298. log=5
299. # 产生train.record文件
300. image_dir='dataset/train'
301. train_labels = 'dataset/train.txt' # 图片路径
302. train_record_output = 'dataset/record/train.tfrecords'
303. create_records(image_dir,train_labels, train_record_output, resize_height, resize_width,shuffle,log)
304. train_nums=get_example_nums(train_record_output)
305. print("save train example nums={}".format(train_nums))
306.
307. # 产生val.record文件
308. image_dir='dataset/val'
309. val_labels = 'dataset/val.txt' # 图片路径
310. val_record_output = 'dataset/record/val.tfrecords'
311. create_records(image_dir,val_labels, val_record_output, resize_height, resize_width,shuffle,log)
312. val_nums=get_example_nums(val_record_output)
313. print("save val example nums={}".format(val_nums))
314.
315. # 测试显示函数
316. # disp_records(train_record_output,resize_height, resize_width)
317. batch_test(train_record_output,resize_height, resize_width)
1.3 训练方法实现过程
inception_v3要求训练数据height, width = 224, 224,项目使用create_tf_record.py制作了训练train.tfrecords和验证val.tfrecords数据,下面是inception_v3_train_val.py文件代码说明:
1. #coding=utf-8
2.
3. import tensorflow as tf
4. import numpy as np
5. import pdb
6. import os
7. from datetime import datetime
8. import slim.nets.inception_v3 as inception_v3
9. from create_tf_record import *
10. import tensorflow.contrib.slim as slim
11.
12.
13. labels_nums = 5 # 类别个数
14. batch_size = 16 #
15. resize_height = 224 # 指定存储图片高度
16. resize_width = 224 # 指定存储图片宽度
17. depths = 3
18. data_shape = [batch_size, resize_height, resize_width, depths]
19.
20. # 定义input_images为图片数据
21. input_images = tf.placeholder(dtype=tf.float32, shape=[None, resize_height, resize_width, depths], name='input')
22. # 定义input_labels为labels数据
23. # input_labels = tf.placeholder(dtype=tf.int32, shape=[None], name='label')
24. input_labels = tf.placeholder(dtype=tf.int32, shape=[None, labels_nums], name='label')
25.
26. # 定义dropout的概率
27. keep_prob = tf.placeholder(tf.float32,name='keep_prob')
28. is_training = tf.placeholder(tf.bool, name='is_training')
29.
30. def net_evaluation(sess,loss,accuracy,val_images_batch,val_labels_batch,val_nums):
31. val_max_steps = int(val_nums / batch_size)
32. val_losses = []
33. val_accs = []
34. for _ in range(val_max_steps):
35. val_x, val_y = sess.run([val_images_batch, val_labels_batch])
36. # print('labels:',val_y)
37. # val_loss = sess.run(loss, feed_dict={x: val_x, y: val_y, keep_prob: 1.0})
38. # val_acc = sess.run(accuracy,feed_dict={x: val_x, y: val_y, keep_prob: 1.0})
39. val_loss,val_acc = sess.run([loss,accuracy], feed_dict={input_images: val_x, input_labels: val_y, keep_prob:1.0, is_training: False})
40. val_losses.append(val_loss)
41. val_accs.append(val_acc)
42. mean_loss = np.array(val_losses, dtype=np.float32).mean()
43. mean_acc = np.array(val_accs, dtype=np.float32).mean()
44. return mean_loss, mean_acc
45.
46. def step_train(train_op,loss,accuracy,
47. train_images_batch,train_labels_batch,train_nums,train_log_step,
48. val_images_batch,val_labels_batch,val_nums,val_log_step,
49. snapshot_prefix,snapshot):
50. '''
51. 循环迭代训练过程
52. :param train_op: 训练op
53. :param loss: loss函数
54. :param accuracy: 准确率函数
55. :param train_images_batch: 训练images数据
56. :param train_labels_batch: 训练labels数据
57. :param train_nums: 总训练数据
58. :param train_log_step: 训练log显示间隔
59. :param val_images_batch: 验证images数据
60. :param val_labels_batch: 验证labels数据
61. :param val_nums: 总验证数据
62. :param val_log_step: 验证log显示间隔
63. :param snapshot_prefix: 模型保存的路径
64. :param snapshot: 模型保存间隔
65. :return: None
66. '''
67. saver = tf.train.Saver()
68. max_acc = 0.0
69. with tf.Session() as sess:
70. sess.run(tf.global_variables_initializer())
71. sess.run(tf.local_variables_initializer())
72. coord = tf.train.Coordinator()
73. threads = tf.train.start_queue_runners(sess=sess, coord=coord)
74. for i in range(max_steps + 1):
75. batch_input_images, batch_input_labels = sess.run([train_images_batch, train_labels_batch])
76. _, train_loss = sess.run([train_op, loss], feed_dict={input_images: batch_input_images,
77. input_labels: batch_input_labels,
78. keep_prob: 0.5, is_training: True})
79. # train测试(这里仅测试训练集的一个batch)
80. if i % train_log_step == 0:
81. train_acc = sess.run(accuracy, feed_dict={input_images: batch_input_images,
82. input_labels: batch_input_labels,
83. keep_prob: 1.0, is_training: False})
84. print("%s: Step [%d] train Loss : %f, training accuracy : %g" % (
85. datetime.now(), i, train_loss, train_acc))
86.
87. # val测试(测试全部val数据)
88. if i % val_log_step == 0:
89. mean_loss, mean_acc = net_evaluation(sess, loss, accuracy, val_images_batch, val_labels_batch, val_nums)
90. print("%s: Step [%d] val Loss : %f, val accuracy : %g" % (datetime.now(), i, mean_loss, mean_acc))
91.
92. # 模型保存:每迭代snapshot次或者最后一次保存模型
93. if (i % snapshot == 0 and i > 0) or i == max_steps:
94. print('-----save:{}-{}'.format(snapshot_prefix, i))
95. saver.save(sess, snapshot_prefix, global_step=i)
96. # 保存val准确率最高的模型
97. if mean_acc > max_acc and mean_acc > 0.7:
98. max_acc = mean_acc
99. path = os.path.dirname(snapshot_prefix)
100. best_models = os.path.join(path, 'best_models_{}_{:.4f}.ckpt'.format(i, max_acc))
101. print('------save:{}'.format(best_models))
102. saver.save(sess, best_models)
103.
104. coord.request_stop()
105. coord.join(threads)
106.
107. def train(train_record_file,
108. train_log_step,
109. train_param,
110. val_record_file,
111. val_log_step,
112. labels_nums,
113. data_shape,
114. snapshot,
115. snapshot_prefix):
116. '''
117. :param train_record_file: 训练的tfrecord文件
118. :param train_log_step: 显示训练过程log信息间隔
119. :param train_param: train参数
120. :param val_record_file: 验证的tfrecord文件
121. :param val_log_step: 显示验证过程log信息间隔
122. :param val_param: val参数
123. :param labels_nums: labels数
124. :param data_shape: 输入数据shape
125. :param snapshot: 保存模型间隔
126. :param snapshot_prefix: 保存模型文件的前缀名
127. :return:
128. '''
129. [base_lr,max_steps]=train_param
130. [batch_size,resize_height,resize_width,depths]=data_shape
131.
132. # 获得训练和测试的样本数
133. train_nums=get_example_nums(train_record_file)
134. val_nums=get_example_nums(val_record_file)
135. print('train nums:%d,val nums:%d'%(train_nums,val_nums))
136.
137. # 从record中读取图片和labels数据
138. # train数据,训练数据一般要求打乱顺序shuffle=True
139. train_images, train_labels = read_records(train_record_file, resize_height, resize_width, type='normalization')
140. train_images_batch, train_labels_batch = get_batch_images(train_images, train_labels,
141. batch_size=batch_size, labels_nums=labels_nums,
142. one_hot=True, shuffle=True)
143. # val数据,验证数据可以不需要打乱数据
144. val_images, val_labels = read_records(val_record_file, resize_height, resize_width, type='normalization')
145. val_images_batch, val_labels_batch = get_batch_images(val_images, val_labels,
146. batch_size=batch_size, labels_nums=labels_nums,
147. one_hot=True, shuffle=False)
148.
149. # Define the model:
150. with slim.arg_scope(inception_v3.inception_v3_arg_scope()):
151. out, end_points = inception_v3.inception_v3(inputs=input_images, num_classes=labels_nums, dropout_keep_prob=keep_prob, is_training=is_training)
152.
153. # Specify the loss function: tf.losses定义的loss函数都会自动添加到loss函数,不需要add_loss()了
154. tf.losses.softmax_cross_entropy(onehot_labels=input_labels, logits=out)#添加交叉熵损失loss=1.6
155. # slim.losses.add_loss(my_loss)
156. loss = tf.losses.get_total_loss(add_regularization_losses=True)#添加正则化损失loss=2.2
157. accuracy = tf.reduce_mean(tf.cast(tf.equal(tf.argmax(out, 1), tf.argmax(input_labels, 1)), tf.float32))
158.
159. # Specify the optimization scheme:
160. optimizer = tf.train.GradientDescentOptimizer(learning_rate=base_lr)
161.
162.
163. # global_step = tf.Variable(0, trainable=False)
164. # learning_rate = tf.train.exponential_decay(0.05, global_step, 150, 0.9)
165. #
166. # optimizer = tf.train.MomentumOptimizer(learning_rate, 0.9)
167. # # train_tensor = optimizer.minimize(loss, global_step)
168. # train_op = slim.learning.create_train_op(loss, optimizer,global_step=global_step)
169.
170.
171. # 在定义训练的时候, 注意到我们使用了`batch_norm`层时,需要更新每一层的`average`和`variance`参数,
172. # 更新的过程不包含在正常的训练过程中, 需要我们去手动像下面这样更新
173. # 通过`tf.get_collection`获得所有需要更新的`op`
174. update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS)
175. # 使用`tensorflow`的控制流, 先执行更新算子, 再执行训练
176. with tf.control_dependencies(update_ops):
177. # create_train_op that ensures that when we evaluate it to get the loss,
178. # the update_ops are done and the gradient updates are computed.
179. # train_op = slim.learning.create_train_op(total_loss=loss,optimizer=optimizer)
180. train_op = slim.learning.create_train_op(total_loss=loss, optimizer=optimizer)
181.
182.
183. # 循环迭代过程
184. step_train(train_op, loss, accuracy,
185. train_images_batch, train_labels_batch, train_nums, train_log_step,
186. val_images_batch, val_labels_batch, val_nums, val_log_step,
187. snapshot_prefix, snapshot)
188.
189.
190. if __name__ == '__main__':
191. train_record_file='dataset/record/train.tfrecords'
192. val_record_file='dataset/record/val.tfrecords'
193.
194. train_log_step=100
195. base_lr = 0.01 # 学习率
196. max_steps = 200 # 迭代次数 可选择10000次 有条件可选择100000次
197. train_param=[base_lr,max_steps]
198.
199. val_log_step=10 #可定义200
200. snapshot=200 #保存文件间隔
201. snapshot_prefix='models/model.ckpt'
202. train(train_record_file=train_record_file,
203. train_log_step=train_log_step,
204. train_param=train_param,
205. val_record_file=val_record_file,
206. val_log_step=val_log_step,
207. labels_nums=labels_nums,
208. data_shape=data_shape,
209. snapshot=snapshot,
210. snapshot_prefix=snapshot_prefix)
1.4 模型预测
模型测试的程序,predict.py代码如下:
1. #coding=utf-8
2.
3. import tensorflow as tf
4. import numpy as np
5. import pdb
6. import cv2
7. import os
8. import glob
9. import slim.nets.inception_v3 as inception_v3
10.
11. from create_tf_record import *
12. import tensorflow.contrib.slim as slim
13.
14.
15. def predict(models_path,image_dir,labels_filename,labels_nums, data_format):
16. [batch_size, resize_height, resize_width, depths] = data_format
17.
18. labels = np.loadtxt(labels_filename, str, delimiter='\t')
19. input_images = tf.placeholder(dtype=tf.float32, shape=[None, resize_height, resize_width, depths], name='input')
20.
21. with slim.arg_scope(inception_v3.inception_v3_arg_scope()):
22. out, end_points = inception_v3.inception_v3(inputs=input_images, num_classes=labels_nums, dropout_keep_prob=1.0, is_training=False)
23.
24. # 将输出结果进行softmax分布,再求最大概率所属类别
25. score = tf.nn.softmax(out,name='pre')
26. class_id = tf.argmax(score, 1)
27.
28. sess = tf.InteractiveSession()
29. sess.run(tf.global_variables_initializer())
30. saver = tf.train.Saver()
31. saver.restore(sess, models_path)
32. images_list=glob.glob(os.path.join(image_dir,'*.jpg'))
33. for image_path in images_list:
34. im=read_image(image_path,resize_height,resize_width,normalization=True)
35. im=im[np.newaxis,:]
36. #pred = sess.run(f_cls, feed_dict={x:im, keep_prob:1.0})
37. pre_score,pre_label = sess.run([score,class_id], feed_dict={input_images:im})
38. max_score=pre_score[0,pre_label]
39. print("{} is: pre labels:{},name:{} score: {}".format(image_path,pre_label,labels[pre_label], max_score))
40. sess.close()
41.
42.
43. if __name__ == '__main__':
44.
45. class_nums=5
46. image_dir='test_image'
47. labels_filename='dataset/label.txt'
48. models_path='models/model.ckpt-200'
49.
50. batch_size = 1 #
51. resize_height = 224 # 指定存储图片高度
52. resize_width = 224 # 指定存储图片宽度
53. depths=3
54. data_format=[batch_size,resize_height,resize_width,depths]
55. predict(models_path,image_dir, labels_filename, class_nums, data_format)
另外,可将ckpt转pb文件,见下文。
运行总结见下文。