Deep Learning Based Text Classification: A Comprehensive Review(部分翻译总结)
原文链接:https://arxiv.org/pdf/2004.03705.pdf
摘要:
回顾了近年来的150多个基于深度学习的文本分类模型,并讨论了它们的技术贡献、相似性和优势。总结了40多个广泛用于文本分类的流行数据集。最后,对不同深度学习模型在流行基准上的表现进行量化分析,并探讨未来的研究方向。
1 介绍
自动文本分类的方法大致分为3类:
- 基于规则的方法
- 基于机器学习方法(数据驱动)
- 混合方法
基于规则的方法使用一组预定义的规则将文本分类为不同的类别,这些方法需要对领域有深入的了解,而且系统很难维护。
基于机器学习的方法利用预先标记的例子作为训练数据,学习文本片段与其标签之间的内在联系。因此,基于机器学习的方法可以检测数据中隐藏的模式,具有更高的可扩展性,并且可以应用于各种任务。近年来,机器学习模型引起了人们的广泛关注。大多数经典的基于机器学习的模型遵循流行的两步过程,第一步从文档(或任何其他文本单元)中提取一些手工制作的特征,第二步将这些特征输入分类器进行预测。一些流行的手工制作功能包括单词包(BoW)及其扩展。常用的分类算法有朴素贝叶斯、支持向量机、隐马尔可夫模型、梯度提升树和随机森林。两步方法有几个局限性。例如,依赖手工制作的特性需要繁琐的特性工程和分析才能获得良好的性能。此外,特征设计对领域知识的依赖性强,使得该方法很难推广到新的任务中。最后,这些模型不能充分利用大量的训练数据,因为特征(或特征模板)是预先定义的。
2012年开始了一个范式转变,当时一个基于深度学习的模型AlexNet以很大的优势赢得了ImageNet的竞争。自那时起,深度学习模型被应用于计算机视觉和自然语言处理领域的一系列任务,提高了最新水平。这些模型试图学习特征表示并以端到端的方式执行分类(或回归)。它们不仅能够发现数据中隐藏的模式,而且可以从一个应用转移到另一个应用。毫不奇怪,这些模型正成为近年来各种文本分类任务的主流框架。
混合方法使用基于规则和机器学习方法的组合来进行预测。
根据他们的神经网络结构将这些工作分为几类,例如基于递归神经网络(RNNs)、卷积神经网络(CNNs)、Transformer、注意力、胶囊网络等模型。
2 文本分类深度学习模型
-
基于前馈网络的模型:将文本视为词袋
-
基于RNN的模型:将文本视为一个单词序列,旨在捕获单词相关性和文本结构
-
基于CNN的模型:训练识别文本中的模式,如关键短语,以便分类
-
胶囊网络:解决了CNN池化操作所带来的信息丢失问题,最近被应用于文本分类
-
注意力机制:有效识别文本中的相关词汇,并已成为开发深度学习模型的有用工具
-
记忆增强网络:它将神经网络与外部记忆结合在一起,模型可以读取和写入
-
Transformer:它允许比RNN更多的并行化,使得使用GPU集群高效,使得(预)训练非常大的语言模型成为可能
-
图神经网络:用于捕捉自然语言的内部图形结构,如句法和语义分析树
-
孪生网络:设计用于文本匹配,文本分类的一个特殊情况
-
混合模型:注意力机制、RNN、CNN等结合起来,捕捉句子和文档的局部和全局特征
-
其它模型:使用自动编码器和对抗性训练的无监督学习,以及强化学习
2.1 前馈神经网络
模型将文本视为一个词袋,对于每个单词,使用嵌入模型(如word2vec或Glove)学习向量表示,将嵌入的向量和或平均值作为文本的表示,将其通过一个或多个前馈层(称为多层感知机(MLPS))传递,然后使用logistic回归、朴素贝叶斯或支持向量机等分类器对最终层的表示进行分类。典型代表有:
- DAN
- fastText
DAN:
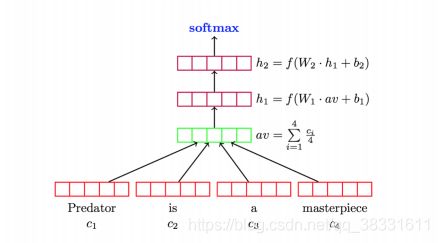
fastText:在文本分类任务中,fastText(浅层网络)往往能取得和深度网络相媲美的精度,却在训练时间上比深度网络快许多数量级。fastText模型的前半部分,即从输入层输入到隐含层输出部分,主要在做一件事情,生成用来表征文档的向量。那么它是如何做的呢?叠加构成这篇文档的所有词及n-gram的词向量,然后取平均。叠加词向量背后的思想就是传统的词袋法,即将文档看成一个由词构成的集合,fastText模型的后半部分,即从隐含层输出到输出层输出,会发现它就是一个softmax线性多类别分类器,分类器的输入是一个用来表征当前文档的向量。于是fastText的核心思想就是:将整篇文档的词及n-gram向量叠加平均得到文档向量,然后使用文档向量做softmax多分类。这中间涉及到两个技巧:字符级n-gram特征的引入以及分层Softmax分类。
fastText具体可以参考知乎文章:https://zhuanlan.zhihu.com/p/32965521
doc2vec:使用无监督算法来学习可变长度文本片段(如句子、段落和文档)的定长特征表示。
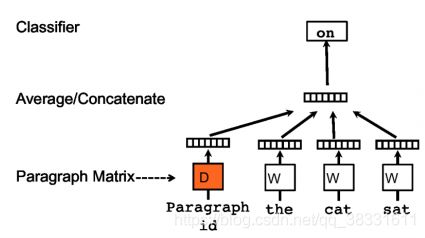
它不是仅是使用一些单词来预测下一个单词,我们还添加了另一个特征向量,即文档Id。因此,当训练单词向量W时,也训练文档向量D,并且在训练结束时,它包含了文档的向量化表示。
2.2 基于RNN的模型
1. Tree-LSTM:
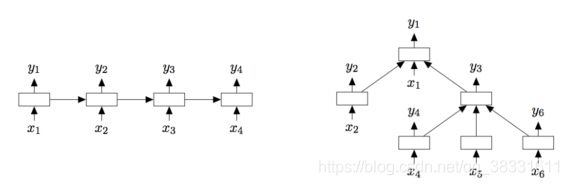
2. 用一个内存网络代替单个内存单元来扩充LSTM体系结构。
J. Cheng, L. Dong, and M. Lapata, “Long short-term memory-networks for machine reading,” arXiv preprint arXiv:1601.06733, 2016.
3. MT-LSTM(Multi-Timescale LSTM,多时间尺度LSTM):
被设计用于通过捕获不同时间尺度的有价值信息来对长文本(如句子和文档)进行建模。因此,MT-LSTM可以对非常长的文档建模。在文本分类方面,MT-LSTM优于基于LSTM和RNN的模型。
4. TopicRNN:
综合了RNNs和潜在主题模型的优点。它使用RNNs捕获本地(语法)依赖,使用潜在主题捕获全局(语义)依赖。
P. Liu, X. Qiu, and X. Huang, “Recurrent neural network for text classification with multi-task learning,” arXiv preprint arXiv:1605.05101,2016.
使用多任务学习来训练RNN,以利用来自多个相关任务的标记训练数据。
R. Johnson and T. Zhang, “Supervised and semi-supervised text categorization using lstm for region embeddings,” arXiv preprint arXiv:1602.02373, 2016.
基于LSTM的文本区域嵌入方法。
P. Zhou, Z. Qi, S. Zheng, J. Xu, H. Bao, and B. Xu, “Text classification improved by integrating bidirectional lstm with two-dimensional max pooling,” arXiv preprint arXiv:1611.06639, 2016.
将双向LSTM(bilstm)模型与二维max池集成,以捕获文本特征。
Z. Wang, W. Hamza, and R. Florian, “Bilateral multi-perspective matching for natural language sentences,” arXiv preprint arXiv:1702.03814,2017.
“匹配聚合”框架下的双边多视角匹配模型。
S. Wan, Y. Lan, J. Guo, J. Xu, L. Pang, and X. Cheng, “A deep architecture for semantic matching with multiple positional sentence representations,” in Thirtieth AAAI Conference on Artificial Intelligence, 2016.
使用双向LSMT模型生成的多个位置句子表示来探索语义匹配。
2.3 基于CNN的模型
RNN被训练成跨时间识别模式,而CNN则学习跨空间识别模式。RNNs在需要理解远程语义的NLP任务(如POS标记或QA)中工作良好,而CNNs在检测局部和位置不变模式非常重要的情况下工作良好。
1. DCNN:
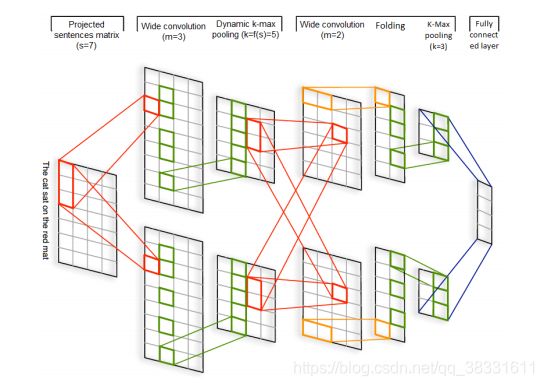
模型由循环的宽卷积层和动态池化层连接的方式组成,中间卷积层的输出即feature map的大小会根据输入句子的长度而变化。
宽卷积:
传统的卷积操作往往会使经过卷积后的句子长度变短(L - w + 1,L 为句子长度,w为filter宽度),而本文使用的宽卷积会使句子长度增加(L + w - 1),因为宽卷积的窗口并不需要覆盖所有输入值,没有值的部分可以用0值填充,这样边缘信息就不会丢失。
动态池化层:
给定一个序列p和值k,其中p >= k,k-max pooling会选择序列p中前k个最大值,并且保留原来序列的次序。
k-max pooling的好处是可以选取句子中不止一个的重要信息,并且保留了它们的相对次序。同时,由于应用在最后的卷积层上只需要提取出k个值,所以这种方法允许不同长度的输入(输入的长度应该要大于k)。然而,对于中间的卷积层而言,池化的参数k不是固定的,池化参数k可以根据句子大小和卷积层次中的级别动态选择。
DCNN具体参考知乎文章:https://zhuanlan.zhihu.com/p/48137188
2. word2vec + 一层卷积:
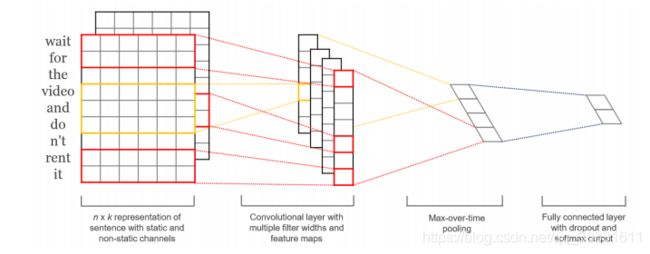
J. Liu, W. C. Chang, Y. Wu, and Y. Yang, “Deep learning for extreme multi-label text classification,” in SIGIR 2017 - Proceedings of the 40th International ACM SIGIR Conference on Research and Development in Information Retrieval, 2017.
对Kim-CNN(即上图模型)的体系结构进行了两次修改。首先,采用动态最大池方案从文档的不同区域捕获更细粒度的特性。其次,在池和输出层之间插入一个隐藏的瓶颈层来学习紧凑的文档表示,来减少模型大小和提高模型性能。
R. Johnson and T. Zhang, “Effective use of word order for text categorization with convolutional neural networks,” in NAACL HLT 2015 - 2015 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Proceedings of the Conference, 2015.
“Deep pyramid convolutional neural networks for text categorization,” in Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2017, pp. 562–570.
没有使用预先训练好的低维词向量作为CNNs的输入,而是直接将CNNs应用到高维文本数据中,学习小文本区域的嵌入以进行分类。
3. 字符级CNN:
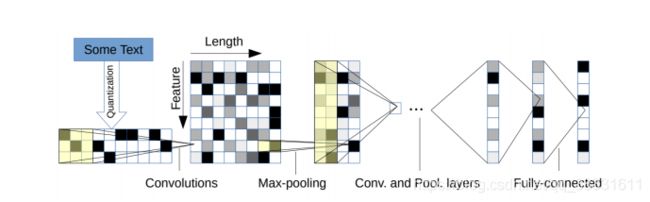
该模型以固定大小、编码为一个热向量的字符作为输入,将其通过由具有池操作的六个卷积层和三个完全连接层组成的深CNN模型。
4. VDCNN:
直接在字符级操作,只使用小卷积和池操作。研究表明,VDCNN的性能随着深度的增加而提高。
Y. Zhang and B. Wallace, “A sensitivity analysis of (and practitioners’ guide to) convolutional neural networks for sentence classification,”arXiv preprint arXiv:1510.03820, 2015.
研究了不同的单词嵌入方法和池机制的影响,发现使用非静态word2vec和GloVe优于一个热向量,而max pooling始终优于其它池方法。
2.4 胶囊网络
CNNs通过使用连续的卷积层和池化对图像或文本进行分类。尽管池化操作识别显著特征并降低卷积操作的计算复杂度,但它们会丢失有关空间关系的信息,并且可能基于实体的方向或比例对实体进行错误分类。为了解决池化的问题,Hinton提出了一种新的方法,称为胶囊网络(CapsNets)。
最近,胶囊网络被应用于文本分类,其中胶囊被用来表示一个句子或文档作为一个矢量。
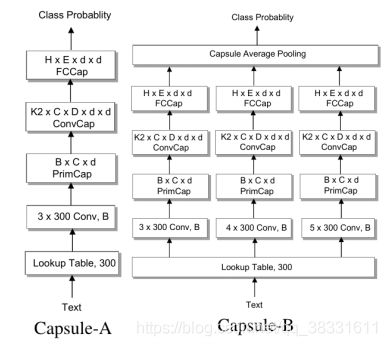
Capsule-A为常规的胶囊网络,Capsule-B在n-gram卷积层使用三个带不同窗口大小滤波器的并行网络来学习更全面的文本表示,CapsNet-B在实验中表现较好。
J. Kim, S. Jang, E. Park, and S. Choi, “Text classification using capsules,” Neurocomputing, vol. 376, pp. 214–221, 2020.
在文本分类方面静态路由始终优于动态路由。
H. Ren and H. Lu, “Compositional coding capsule network with k-means routing for text classification,” arXiv preprint arXiv:1810.09177,2018.
使用胶囊之间的组合编码机制和基于k-均值聚类的新路由算法。首先,单词嵌入是使用码本中的所有码字向量形成的。然后通过k-means路由将低级胶囊捕获的特征聚合到高级胶囊中。
2.5 基于attention机制的模型
Z. Yang, D. Yang, C. Dyer, X. He, A. Smola, and E. Hovy, “Hierarchical attention networks for document classification,” in Proceedings of the 2016 conference of the North American chapter of the association for computational linguistics: human language technologies, 2016, pp. 1480–1489.
提出了一种用于文本分类的分层注意网络。该模型有两个显著的特点:(1)反映文档层次结构的层次结构;(2)在单词和句子层次上应用两个层次的注意机制,使其能够在构建文档表示时区别地关注更多和更少的重要内容。
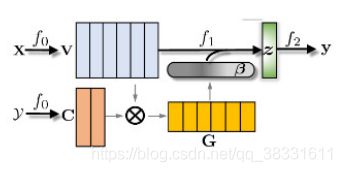
G. Wang, C. Li, W. Wang, Y. Zhang, D. Shen, X. Zhang, R. Henao, and L. Carin, “Joint embedding of words and labels for text classification,” arXiv preprint arXiv:1805.04174, 2018.
将文本分类看作是一个标签词匹配问题:每个标签都嵌入到与词向量相同的空间中。作者介绍了一个注意框架,该框架通过余弦相似性度量文本序列和标签之间嵌入的兼容性,如图8(b)所示。
C. Tan, F. Wei, W. Wang, W. Lv, and M. Zhou, “Multiway attention networks for modeling sentence pairs,” in IJCAI, 2018, pp. 4411–4417.
在匹配聚合框架下,使用多个注意函数来匹配句子对。
Z. Lin, M. Feng, C. N. d. Santos, M. Yu, B. Xiang, B. Zhou, and Y. Bengio, “A structured self-attentive sentence embedding,” arXiv preprint arXiv:1703.03130, 2017.
利用自注意力机制提取可解释的句子嵌入。
I. Yamada and H. Shindo, “Neural attentive bag-of-entities model for text classification,” arXiv preprint arXiv:1909.01259, 2019.
使用神经注意实体包模型,使用知识库中的实体执行文本分类。
Q. Chen, Z.-H. Ling, and X. Zhu, “Enhancing sentence embedding with generalized pooling,” arXiv preprint arXiv:1806.09828, 2018.
提出一种基于向量的多头注意力模型。
2.6 记忆增强网络
记忆增强网络将神经网络与外部记忆结合起来,模型可以对其进行读写。
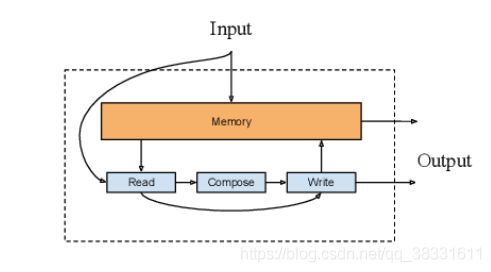
S. Sukhbaatar, J. Weston, R. Fergus et al., “End-to-end memory networks,” in Advances in neural information processing systems, 2015,pp. 2440–2448.
提出了端到端的记忆网络,其中的记忆条目通过注意机制以软方式检索,从而实现端到端的训练。
A. Kumar, O. Irsoy, P. Ondruska, M. Iyyer, J. Bradbury, I. Gulrajani, V. Zhong, R. Paulus, and R. Socher, “Ask me anything: Dynamic memory networks for natural language processing,” in 33rd International Conference on Machine Learning, ICML 2016, 2016.
提出了一种动态记忆方法(DMN),它处理输入序列和问题,形成情景记忆,并生成相关答案。问题触发一个迭代注意过程,它允许模型将其注意条件设置为前一次迭代的输入和结果。然后,这些结果在层次递归序列模型中进行推理以生成答案。DMN是端到端训练,并获得最新的QA和POS标记结果。
C. Xiong, S. Merity, and R. Socher, “Dynamic memory networks for visual and textual question answering,” in 33rd International Conference on Machine Learning, ICML 2016, 2016.
对DMN进行了详细的分析,改进了DMN的存储和输入模块。
2.7 Transformer
RNNs所面临的计算瓶颈之一是文本的顺序处理。尽管CNNs比RNNs的序列性要小,但是获取句子中单词之间关系的计算成本也随着句子长度的增加而增加,这与RNNs类似。Transformer克服了这一限制,将自我注意应用于并行计算句子中的每个单词,或记录“注意分数”,以模拟每个单词对另一个单词的影响。由于这个特性,Transformer允许比CNNs和RNNs更多的并行化,这使得在GPU集群上有效地训练大量数据的非常大的模型成为可能。
预训练语言模型分为两类,自回归预训练语言模型和自编码语言模型,最早的自回归预训练语言模型之一是OpenGPT,这是一个单向模型,它从左到右(或从右到左)逐字预测文本序列,每个单词的预测取决于以前的预测。
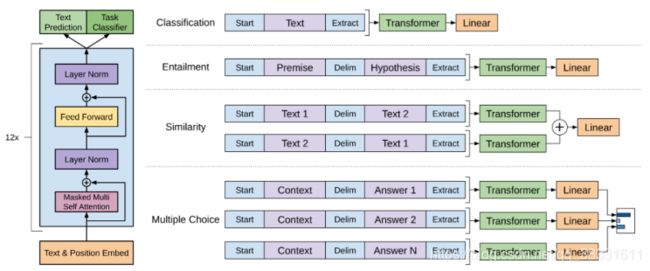
它由12层Transformer块组成,每个Transformer块由一个mask的多头注意力模块、一个层归一化和一个位置前馈层组成。OpenGPT可以通过添加特定于任务的线性分类器和使用特定于任务的标签进行微调来适应下游任务,例如文本分类。
最广泛使用的自动编码预训练语言模型之一是BERT]。与OpenGPT基于先前的单词预测不同,BERT使用masked语言建模任务进行训练,该任务随机屏蔽文本序列中的一些标记,然后通过对双向Transformer获得的编码向量进行调节,独立地恢复屏蔽标记。关于改进BERT的工作有很多。RoBERTa比BERT更健壮,并且使用更多的训练数据进行训练。ALBERT降低了记忆消耗,提高了BERT的训练速度。 DistillBERT在预训练期间利用知识蒸馏将BERT的大小减少40%,同时保留其99%的原始能力,并使推理速度加快60%。SpanBERT扩展了BERT以更好地表示和预测文本跨度。BERT及其变体已经针对各种NLP任务进行了微调,包括QA、文本分类]和NLI(自然语言推断)。
有人试图将自回归和自编码预训练语言模型的优点结合起来。XLNet集成了OpenGPT等自回归模型和BERT的双向上下文建模思想。XLNet在预训练期间使用了一个置换操作,允许上下文同时包含来自左和右的token,使其成为一个广义的顺序感知自回归语言模型。这种排列是通过在Transformer中使用一个特殊的注意mask来实现的。XLNet还引入了一个双流自注意力模式,允许位置感知的单词预测。这是由于观察到单词分布因单词位置的不同而变化很大。例如,句子的开头与句子中其他位置的分布有很大的不同。
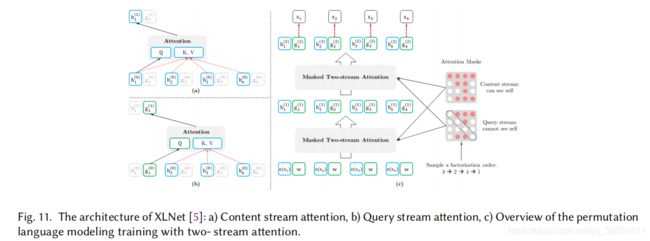 如图所示,为了在置换3-2-4-1中预测位置1中的字token,通过包括所有先前字(3、2、4)的位置嵌入和令牌嵌入来形成内容流,然后通过包括要预测的字(位置1中的字)的内容流和位置嵌入来形成查询流,最后根据查询流中的信息进行预测。
如图所示,为了在置换3-2-4-1中预测位置1中的字token,通过包括所有先前字(3、2、4)的位置嵌入和令牌嵌入来形成内容流,然后通过包括要预测的字(位置1中的字)的内容流和位置嵌入来形成查询流,最后根据查询流中的信息进行预测。
**统一语言模型(UniLM)**旨在处理自然语言理解和生成任务。UniLM使用三种类型的语言建模任务进行预训练:单向、双向和序列到序列预测。
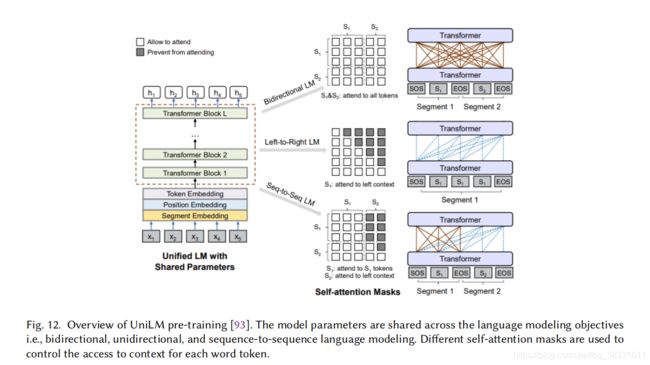
如图所示,通过使用共享Transformer网络和利用特定的自注意力mask来控制预测条件所处的上下文来实现统一建模。据报道,UniLM的第二个版本在广泛的自然语言理解和生成任务上达到了最新的水平,显著优于以前的预训练语言模型,包括OpenGPT-2、XLNet、BERT及其变体。
2.8 图神经网络
尽管自然语言文本具有顺序性,但它们也包含内部的图形结构,如句法和语义分析树,它们定义了句子中单词之间的句法/语义关系。
为NLP开发的最早的基于图的模型之一是TextRank。作者提出将自然语言文本表示为图形(V,E),其中V表示一组节点,E表示节点之间的一组边。根据手头的应用,节点可以表示各种类型的文本单位,例如单词、搭配、整句话等。同样,边缘可以表示任何节点之间的不同类型的关系,例如词汇或语义关系、上下文重叠等。GNNs利用文档或单词之间的相互关系来推断文档标签。
H. Peng, J. Li, Y. He, Y. Liu, M. Bao, L. Wang, Y. Song, and Q. Yang, “Large-scale hierarchical text classification with recursively regularized deep graph-cnn,” in Proceedings of the 2018 World Wide Web Conference. International World Wide Web Conferences Steering Committee, 2018, pp. 1063–1072.
提出了一种基于图CNN的深度学习模型,首先将文本转换成词的图,然后使用图卷积运算卷积词的图。如下图所示。
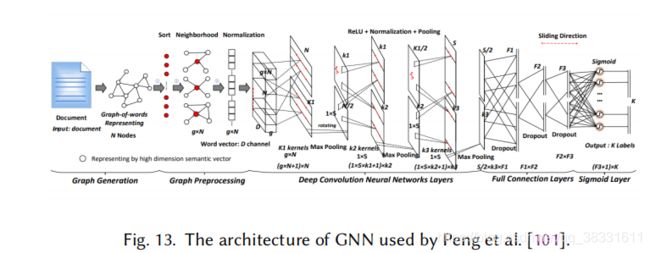
实验表明,文本的词表示图具有捕获非连续语义和远距离语义的优势,CNN模型具有学习不同层次语义的优势。
H. Peng, J. Li, Q. Gong, S. Wang, L. He, B. Li, L. Wang, and P. S. Yu, “Hierarchical taxonomy-aware and attentional graph capsule rcnns for large-scale multi-label text classification,” arXiv preprint arXiv:1906.04898, 2019.
提出了一种基于层次分类感知和注意图胶囊CNNs的文本分类模型。该模型的一个独特之处是使用了类标签之间的层次关系,在以前的方法中,这些关系被认为是独立的。具体来说,为了利用这种关系,作者开发了一种层次分类嵌入方法来学习它们的表示,并通过结合标签表示相似度定义了一种新的加权边缘损失。
L. Yao, C. Mao, and Y. Luo, “Graph convolutional networks for text classification,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 33, 2019, pp. 7370–7377.
使用相似图CNN(GCNN)模型进行文本分类。他们基于单词共现和文档单词关系为一个语料库构建了一个文本图,然后学习了一个文本图卷积网络(text GCN),如下图所示。
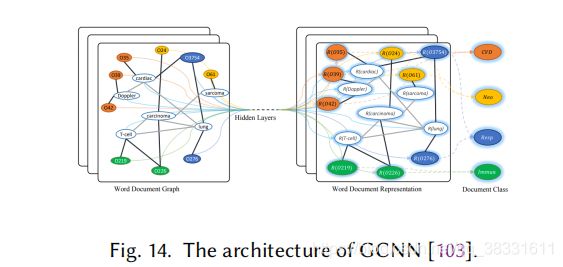
文本GCN由word和document的一个one-hot表示初始化,然后在已知文档类标签的监督下,共同学习word和document的嵌入。
2.9 孪生神经网络
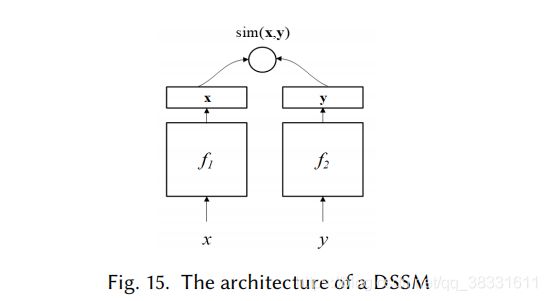
DSSM(或S2Net)由一对DNNs、f1和f2组成,它们将输入x和y映射到公共低维语义空间中的对应向量中。然后用两个向量的余弦距离来度量x和y的相似性。虽然s2net假设f1和f2共享相同的体系结构甚至相同的参数,但是在DSSMs中,f1和f2可以根据x和y的不同而具有不同的体系结构。例如,要计算图像-文本对的相似性,f1可以是深度CNN和f2是RNN或MLP。根据(x,y)的定义,这些模型可以应用于各种NLP任务。例如,(x,y)可以是查询文档排名的查询文档对,或者QA中的问答对,等等。
由于文本具有顺序性,因此使用RNNs或LSTMs来度量文本之间的语义相似度,实现f1和f2是很自然的。
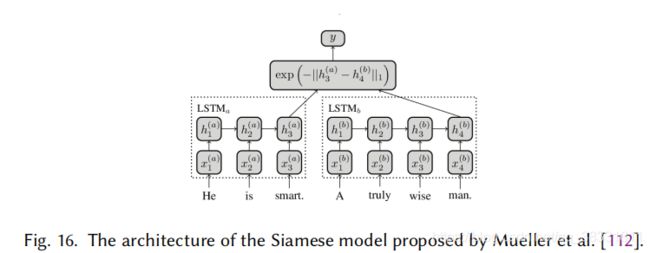
J. Mueller and A. Thyagarajan, “Siamese recurrent architectures for learning sentence similarity,” in 30th AAAI Conference on Artificial Intelligence, AAAI 2016, 2016.
其中两个网络使用相同的LSTM模型。
P. Neculoiu, M. Versteegh, and M. Rotaru, “Learning Text Similarity with Siamese Recurrent Networks,” 2016.
提出了一个相似的模型,该模型对f1和f2使用字符级Bi-LSTMs,并使用余弦函数计算相似性。
除RNNs外,s2net中还使用BOW模型和CNNs来表示句子。
H. He, K. Gimpel, and J. Lin, “Multi-perspective sentence similarity modeling with convolutional neural networks,” in Conference Proceedings - EMNLP 2015: Conference on Empirical Methods in Natural Language Processing, 2015.
提出了一种利用CNNs对多视角句子相似度进行建模的S2Net。
T. Renter, A. Borisov, and M. De Rijke, “Siamese CBOW: Optimizing word embeddings for sentence representations,” in 54th Annual Meeting of the Association for Computational Linguistics, ACL 2016 - Long Papers, 2016.
提出了一个连体CBOW模型,该模型通过平均句子的词嵌入来形成句子向量表示,并将句子相似度计算为句子向量之间的余弦相似度。随着BERT成为新的最先进的句子嵌入模型,有人试图构建基于BERT的s2net,如SBERT和TwinBERT。
2.10 混合模型
1. C-LSTM(卷积LSTM)

C-LSTM利用CNN来提取高级短语(n-gram)表示序列,该序列被馈送到LSTM网络以获得句子表示。
2. DSCNN
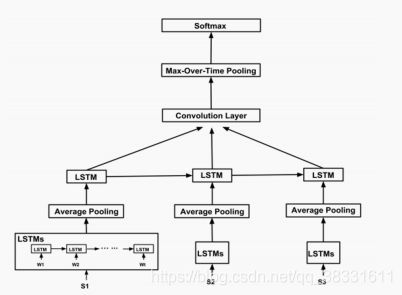
一种用于文档建模的依赖敏感CNN,DSCNN是一个层次模型,其中LSTM学习被馈送到卷积层和最大池层的句子向量以生成文档表示。
G. Chen, D. Ye, E. Cambria, J. Chen, and Z. Xing, “Ensemble application of convolutional and recurrent neural networks for multi-label text categorization,” in IJCNN, 2017, pp. 2377–2383.
通过CNN-RNN模型执行多标签文本分类,该模型能够捕获全局和局部文本语义,因此,在具有可处理的计算复杂性的同时,能够建模高阶标签相关性。
D. Tang, B. Qin, and T. Liu, “Document modeling with gated recurrent neural network for sentiment classification,” in Proceedings of the 2015 conference on empirical methods in natural language processing, 2015, pp. 1422–1432.
使用CNN学习句子表示,使用门控RNN学习编码句子之间内在关系的文档表示。
Y. Xiao and K. Cho, “Efficient character-level document classification by combining convolution and recurrent layers,” arXiv preprint arXiv:1602.00367, 2016.
将文档视为字符序列,而不是单词,并建议使用基于字符的卷积和递归层进行文档编码。与字级模型相比,该模型在参数较少的情况下取得了可比的性能。
S. Lai, L. Xu, K. Liu, and J. Zhao, “Recurrent convolutional neural networks for text classification,” in Twenty-ninth AAAI conference on artificial intelligence, 2015.
应用了递归结构,以捕获用于学习单词表示的远程上下文依赖。为了降低噪声,采用最大池法自动选择对文本分类任务至关重要的显著词。
3. HDLTex
一种用于文本分类的分层深度学习方法,HDLTex采用了一系列混合的深度学习模型体系结构,包括MLP、RNN和CNN,以在文档层次结构的每个层次提供专门的理解。
4. SAN
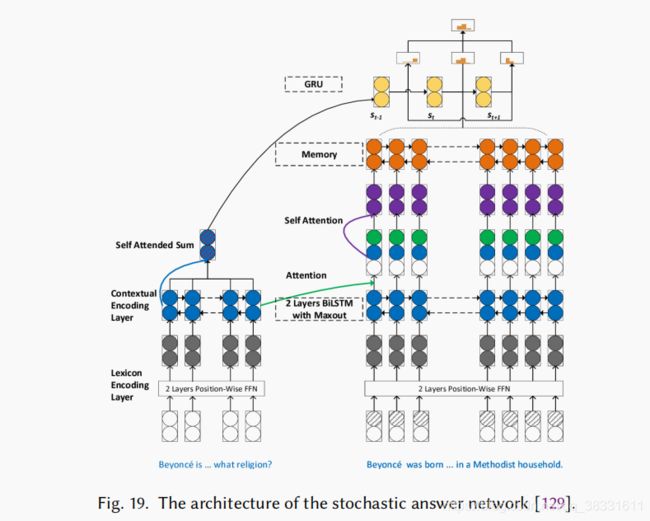
一种用于机器阅读理解中多步推理的鲁棒随机应答网络,SAN结合了不同类型的神经网络,包括记忆网络、Transformer、Bi -LSTM、注意力机制和CNN。B-LSTM组件获取问题和段落的上下文表示。它的注意力机制导出了一个问题感知的段落表示。然后,使用另一个LSTM为文章生成一个工作内存。最后,基于门控递归单元(GRU)的应答模块输出预测。
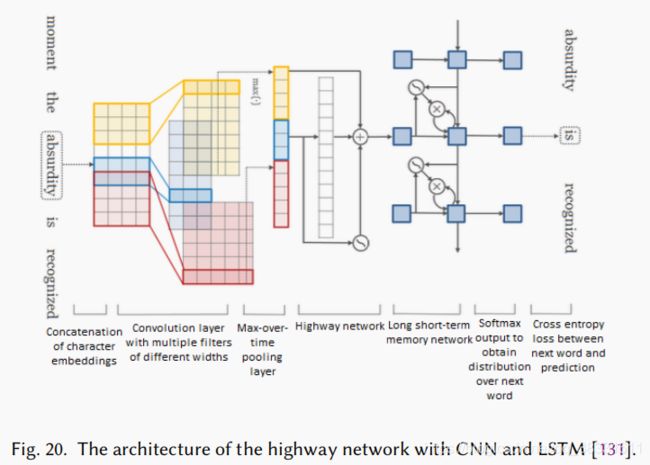
5. highway network with CNN and LSTM
Y. Kim, Y. Jernite, D. Sontag, and A. M. Rush, “Character-Aware neural language models,” in 30th AAAI Conference on Artificial Intelligence, AAAI 2016, 2016.
2.11 其他方法
1. 使用自动编码器的无监督学习
R. Kiros, Y. Zhu, R. R. Salakhutdinov, R. Zemel, R. Urtasun, A. Torralba, and S. Fidler, “Skip-thought vectors,” in Advances in neural information processing systems, 2015, pp. 3294–3302.
提出了一种无监督学习通用句子编码器的跳跃思维模型。训练编码器-解码器模型来重建编码句子的周围句子。
A. M. Dai and Q. V. Le, “Semi-supervised sequence learning,” in Advances in Neural Information Processing Systems, 2015.
研究了序列自动编码器(sequence autoencoder)在句子编码中的应用,该编码器将输入序列读入向量并再次预测输入。他们表明,在一个大的无监督语料库上进行预训练的句子编码比只进行预训练的单词嵌入产生更好的准确性。
M. Zhang, Y. Wu, W. Li, and W. Li, “Learning Universal Sentence Representations with Mean-Max Attention Autoencoder,” 2019.
提出了一种平均最大注意自动编码器,该编码器利用多头自注意机制重构输入序列。在编码中使用mean-max策略,在编码过程中,对隐藏向量应用mean和max池操作来捕获输入的不同信息。当自动编码器学习输入的压缩表示时,变分自动编码器(VAEs)学习表示数据的分布,并且可以看作是自动编码器的正则化版本。
S. R. Bowman, L. Vilnis, O. Vinyals, A. M. Dai, R. Jozefowicz, and S. Bengio, “Generating sentences from a continuous space,” in CoNLL 2016 - 20th SIGNLL Conference on Computational Natural Language Learning, Proceedings, 2016.
提出了基于RNN的VAE语言模型示。
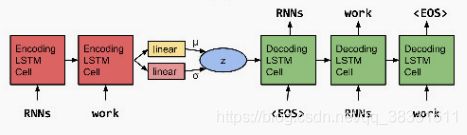
该模型融合了整句的分布式潜在表示,允许显式地建模句子的整体属性,如风格、主题和高级句法特征。
2. 对抗训练
T. Miyato, A. M. Dai, and I. Goodfellow, “Adversarial training methods for semi-supervised text classification,” arXiv preprint arXiv:1605.07725, 2016.
通过对RNN中嵌入的单词而不是原始输入本身应用扰动,将对抗性和虚拟对抗性训练扩展到有监督和半监督的文本分类任务。
D. S. Sachan, M. Zaheer, and R. Salakhutdinov, “Revisiting lstm networks for semi-supervised text classification via mixed objective function,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 33, 2019, pp. 6940–6948.
研究了用于半监督文本分类的LSTM模型。他们发现,对于有标签和无标签的数据,使用结合了交叉熵、对抗性和虚拟对抗性损失的混合目标函数,可以显著改善监督学习方法。
P. Liu, X. Qiu, and X. Huang, “Adversarial multi-task learning for text classification,” arXiv preprint arXiv:1704.05742, 2017.
将对抗训练扩展到文本分类的多任务学习框架,旨在减轻任务独立(共享)和任务依赖(私有)的潜在特征空间之间的相互干扰。
3. 强化学习
X. Liu, L. Mou, H. Cui, Z. Lu, and S. Song, “Finding decision jumps in text classification,” Neurocomputing, vol. 371, pp. 177–187, 2020.
提出了一种将文本分类建模为顺序决策过程的神经代理。受人类文本阅读认知过程的启发,智能体按顺序扫描一段文本,并在希望的时间做出分类决策。分类结果和何时进行分类都是决策过程的一部分,由经过RL训练的策略控制。
Y. Li, Q. Pan, S. Wang, T. Yang, and E. Cambria, “A generative model for category text generation,” Information Sciences, vol. 450, pp.301–315, 2018.
将RL、GANs和RNNs相结合,建立了一种新的类别句子生成对抗网络模型(CS-GAN),该模型能够生成扩展原始数据集的类别句子,并在有监督的训练中提高其泛化能力。
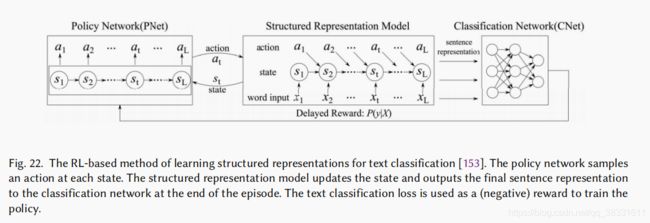
T. Zhang, M. Huang, and L. Zhao, “Learning structured representation for text classification via reinforcement learning,” in Thirty-Second AAAI Conference on Artificial Intelligence, 2018.
提出了一种基于RL的文本分类学习结构化表示方法。他们提出了两个基于LSTM的模型。第一个选项只选择输入文本中与任务相关的重要单词。另一个发现句子的短语结构。使用这两个模型的结构发现被表示为由策略网络引导的顺序决策过程,策略网络在每个步骤决定使用哪个模型,利用策略梯度优化策略网络。
5 挑战和机遇
建立常识知识模型:将常识性知识融入深度学习模型有可能显著提高模型性能,这与人类利用常识性知识执行不同任务的方式几乎相同。例如,一个配备常识知识库的QA系统可以回答关于真实世界的问题。常识知识也有助于在信息不完整的情况下解决问题。人工智能系统利用人们对日常事物或概念的普遍信念,以类似的方式,基于对未知事物的“默认”假设进行推理。尽管这一思想已经被用于情绪分类,但是还需要更多的研究来探索如何在神经模型中有效地建模和使用常识知识。
可解释的深度学习模型:尽管深度学习模型在具有挑战性的基准测试中取得了令人满意的性能,但大多数模型都是不可解释的,并且仍然存在许多悬而未决的问题。例如,为什么一个模型在一个数据集上优于另一个模型,但在其他数据集上却表现不佳?深度学习模式到底学到了什么?什么是最小的神经网络结构,能够在给定的数据集上达到一定的精度?尽管注意和自我注意机制为回答这些问题提供了一些见解,但对这些模型的潜在行为和动力学的详细研究仍然缺乏。更好地理解这些模型的理论方面有助于开发针对各种文本分析场景的更好的模型。
内存效率模型:大多数现代神经语言模型需要大量的记忆来训练和推理。但是,为了满足移动设备的计算和存储限制,这些模型必须进行简化和压缩。这可以通过使用知识蒸馏来构建学生模型,或者使用模型压缩技术来实现。开发与任务无关的模型简化方法是一个活跃的研究课题。
少样本和零样本学习:大多数深度学习模型都是有监督的模型,需要大量的领域标签。实际上,为每个新域收集这样的标签是昂贵的。微调一个针对特定任务的预训练语言模型(PLM)如BERT和OpenGPT比从头开始训练一个模型需要更少的领域标签,从而为开发基于PLM的新的少样本和零样本学习方法提供了机会。
注:本人为深度学习领域的小白,针对自己研究,翻译了文章中部分内容,由于时间因素大部分为机器翻译,如有不正确或解释不通的地方敬请谅解。
[5] Z. Yang, Z. Dai, Y. Yang, J. Carbonell, R. R. Salakhutdinov, and Q. V. Le, “Xlnet: Generalized autoregressive pretraining for languageunderstanding,” in Advances in neural information processing systems, 2019, pp. 5754–5764.
[23] Z. Wang, W. Hamza, and R. Florian, “Bilateral multi-perspective matching for natural language sentences,” arXiv preprint arXiv:1702.03814,2017.
[55] J. Kim, S. Jang, E. Park, and S. Choi, “Text classification using capsules,” Neurocomputing, vol. 376, pp. 214–221, 2020.
[57] H. Ren and H. Lu, “Compositional coding capsule network with k-means routing for text classification,” arXiv preprint arXiv:1810.09177, 2018.
[60] Z. Yang, D. Yang, C. Dyer, X. He, A. Smola, and E. Hovy, “Hierarchical attention networks for document classification,” in Proceedings of the 2016 conference of the North American chapter of the association for computational linguistics: human language technologies, 2016, pp. 1480–1489.
[65] G. Wang, C. Li, W. Wang, Y. Zhang, D. Shen, X. Zhang, R. Henao, and L. Carin, “Joint embedding of words and labels for text classification,” arXiv preprint arXiv:1805.04174, 2018.
[68] C. Tan, F. Wei, W. Wang, W. Lv, and M. Zhou, “Multiway attention networks for modeling sentence pairs,” in IJCAI, 2018, pp. 4411–4417.
[70] Z. Lin, M. Feng, C. N. d. Santos, M. Yu, B. Xiang, B. Zhou, and Y. Bengio, “A structured self-attentive sentence embedding,” arXiv preprint arXiv:1703.03130, 2017.
[78] S. Sukhbaatar, J. Weston, R. Fergus et al., “End-to-end memory networks,” in Advances in neural information processing systems, 2015, pp. 2440–2448.
[79] A. Kumar, O. Irsoy, P. Ondruska, M. Iyyer, J. Bradbury, I. Gulrajani, V. Zhong, R. Paulus, and R. Socher, “Ask me anything: Dynamic memory networks for natural language processing,” in 33rd International Conference on Machine Learning, ICML 2016, 2016.
[80] C. Xiong, S. Merity, and R. Socher, “Dynamic memory networks for visual and textual question answering,” in 33rd International Conference on Machine Learning, ICML 2016, 2016.
[83] A. Radford, J. Wu, R. Child, D. Luan, D. Amodei, and I. Sutskever, “Language models are unsupervised multitask learners,” OpenAI Blog, vol. 1, no. 8, p. 9, 2019.
[93] L. Dong, N. Yang, W. Wang, F. Wei, X. Liu, Y. Wang, J. Gao, M. Zhou, and H.-W. Hon, “Unified language model pre-training for natural language understanding and generation,” in Advances in Neural Information Processing Systems, 2019, pp. 13 042–13 054.
[94] H. Bao, L. Dong, F. Wei, W. Wang, N. Yang, X. Liu, Y. Wang, S. Piao, J. Gao, M. Zhou et al., “Unilmv2: Pseudo-masked language models for unified language model pre-training,” arXiv preprint arXiv:2002.12804, 2020.
[96] R. Mihalcea and P. Tarau, “Textrank: Bringing order into text,” in Proceedings of the 2004 conference on empirical methods in natural language processing, 2004, pp. 404–411.
[102] H. Peng, J. Li, Q. Gong, S. Wang, L. He, B. Li, L. Wang, and P. S. Yu, “Hierarchical taxonomy-aware and attentional graph capsule rcnns for large-scale multi-label text classification,” arXiv preprint arXiv:1906.04898, 2019.
[137] M. Zhang, Y. Wu, W. Li, and W. Li, “Learning Universal Sentence Representations with Mean-Max Attention Autoencoder,” 2019.
[152] Y. Li, Q. Pan, S. Wang, T. Yang, and E. Cambria, “A generative model for category text generation,” Information Sciences, vol. 450, pp.301–315, 2018.