『 论文阅读』Slot-Gated Modeling for Joint Slot Filling and Intent Prediction
文章目录
- 1. 创新点:
- 2. 模型
- 2.1 底层特征:
- 2.2 attention:
- 2.3 slot-Gate:
- 实验结果:
- conclusion
- Reference
来自论文:《Slot-Gated Modeling for Joint Slot Filling and Intent Prediction》
发表在NAACL HLT 2018,自然语言四大顶会之一。
基于Attention的RNN模型在联合意图识别(ID)和槽位填充(SF)上实现最好性能(其ID和SF的attention权重独立)。作者认为其通过损失函数将两者关联只是隐式地关联,本文提出slot gate结构,其关注于学习intent和slot attention向量之间的关系,通过全局优化获得更好的semantic frame。通过在ATIS和Snips数据集实验,相比于attention模型semantic frame准确率提升了4.2%。
1. 创新点:
- 提出slot-gate方法实现了最好的性能表现。
- 通过数据集实验表明slot-gate的有效性。
- slot-gate有助于分析槽位和意图的关系。

2. 模型
2.1 底层特征:
使用BiLSTM结构,输入: x = ( x 1 , x 2 , . . . x T ) x = (x_1, x_2,... x_T) x=(x1,x2,...xT),输出: h t = [ h t → , h t ← ] h_t = [\overrightarrow{h_t}, \overleftarrow{h_t}] ht=[ht,ht]
2.2 attention:
-
slot filling attention:
- 权重计算:
c i S = ∑ j = 1 T α i , j S h j , (1) c_i^S = \sum^T_{j=1} \alpha^S_{i,j} h_j,\tag{1} ciS=j=1∑Tαi,jShj,(1)
α i , j S = e x p ( e i , j ) ∑ k = 1 T e x p ( e j , k ) (2) \alpha^S_{i,j} = \frac{exp(e_{i,j})}{\sum_{k=1}^T exp(e_{j,k})} \tag{2} αi,jS=∑k=1Texp(ej,k)exp(ei,j)(2)
e i , k = σ ( W h e S h k + W i e h i ) (3) e_{i,k} = \sigma(W_{he}^S h_k + W_{ie} h_i) \tag{3} ei,k=σ(WheShk+Wiehi)(3)
c i S ∈ R b s ∗ T c_i^S \in R^{bs*T} ciS∈Rbs∗T,和 h j h_j hj一致。
e i , k ∈ R 1 e_{i,k} \in R^1 ei,k∈R1, e i , k e_{i,k} ei,k计算的是 h k h_k hk和当前输入向量 h i h_i hi之间的关系。
作者TensorFlow源码 W k e S h k W_{ke}^S h_k WkeShk用的卷积实现,而 W i e S h i W_{ie}^S h_i WieShi用的线性映射_linear()。
T是attention维度,一般和输入向量一致。
- SF
y i S = s o f t m a x ( W h y S ( h i + c i S ) ) (4) y_i^S = softmax(W_{hy}^S (h_i+c_i^S)) \tag{4} yiS=softmax(WhyS(hi+ciS))(4)
- Intent Prediction:其输入时BiLSTM的最后一个单元的输出 h T h^T hT以及其对应的context向量,c的计算方式和slot filling的一致,相当于其i=T。
y I = s o f t m a x ( W h y I ( h T + c I ) ) (5) y^I = softmax(W_{hy}^I (h_T+c^I)) \tag{5} yI=softmax(WhyI(hT+cI))(5)
Attention具体细节见:Attention-Based Recurrent Neural Network Models for Joint Intent Detection and Slot Filling
2.3 slot-Gate:
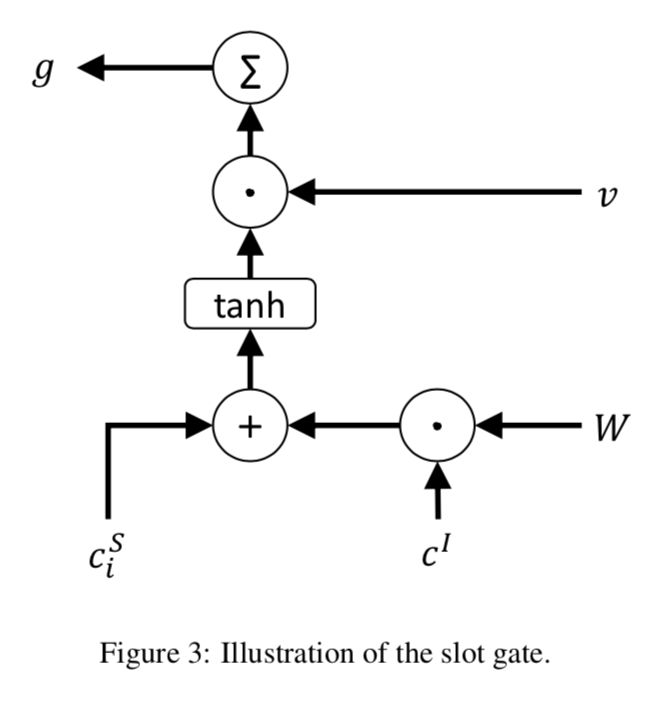
利用意图上下文向量来建模槽意图关系,以提高槽填充性能。如图3:
-
槽位的context向量和意图的context向量组合通过门结构(其中v和W都是可训练的):
g = ∑ v ⋅ t a n h ( c i S + W ⋅ c I ) g = \sum v \cdot tanh(c_i^S + W \cdot c^I) g=∑v⋅tanh(ciS+W⋅cI)c I , c i S , v ∈ R d c^I,c_i^S, v \in R^{d} cI,ciS,v∈Rd,d是输入向量h的维度。
g i ∈ R 1 g_i \in R^1 gi∈R1,获得 c I c^I cI的权重。
论文源码使用的是: g = ∑ v ⋅ t a n h ( c i S + W ⋅ ( c I + f i n s a l S t a t e I ) ) g = \sum v \cdot tanh(c_i^S + W \cdot (c^I+finsalState^I)) g=∑v⋅tanh(ciS+W⋅(cI+finsalStateI))
-
用g作为预测 y i S y_i^S yiS的权重向量:
y i S = s o f t m a x ( W h y S ( h i + c i S ⋅ g ) ) y_i^S = softmax(W_{hy}^S(h_i+c_i^S \cdot g)) yiS=softmax(WhyS(hi+ciS⋅g))
a). 使用了intent和slot的attention。
b). 只使用intent的attention。
实验结果:
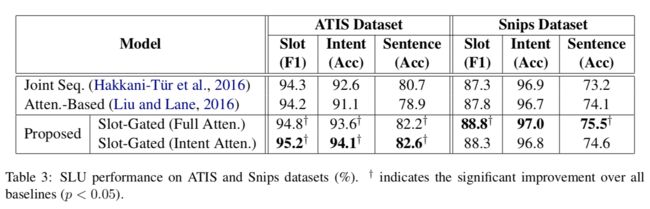
Liu论文中ic error:1.57,SF f1:95.87
slot-gate学习了intent和slot之间的关系-提供intent context向量。实现了更好的性能。
conclusion
本文提出了一种明确学习slot-intent关系的机制-“slot-gated”,学习意图的结果来促进slot filling。实验证明取得了state of art性能,且推广到多个数据集。
感想:
本文提出的一种将intent detect和slot filling显示关联学习的架构,并实验证明有效,说明可以深挖如何在ID和SF显示关联上设计更好的架构,例如本文是单向的门结构,ID结果输入到SF,是否能够将二者相互关联,SF结果也可以输入到ID。或者提出更优雅表征显式关系的结构。
三种模型slot filling对比:
- LSTM+CRF:
y i S = C R F ( W S ( h i + b S ) ) y_i^S = CRF(W^S(h_i+b^S)) yiS=CRF(WS(hi+bS))
-
attention预测:
y i S = s o f t m a x ( W h y S ( h i + c i S ) ) y_i^S = softmax(W_{hy}^S(h_i+c_i^S)) yiS=softmax(WhyS(hi+ciS)) -
slot-Gate:
y i S = s o f t m a x ( W h y S ( h i + c i S ⋅ g ) ) y_i^S = softmax(W_{hy}^S(h_i+c_i^S \cdot g)) yiS=softmax(WhyS(hi+ciS⋅g))
| Data Set | # Train | # Dev | # Test | |V| | # Intents | # Slots |
|---|---|---|---|---|---|---|
| ATIS | 4,978 | - | 893 | 900 | 17 | 79 |
csdn原文:https://blog.csdn.net/shine19930820/article/details/83052300
在原作者代码基础上添加CRF,有微小提升,代码地址:https://github.com/InsaneLife/Joint-NLU:
| crf | softmax | |
|---|---|---|
| Slot f1 | val: 97.39 ; test: 95.15 | val: 97.0; test:95.08 |
| Intent Acc | val: 98.2; test: 95.41 | val: 97.6; test: 95.52 |
| Semantic Acc | val: 90.0; test: 83.42 | val: 89.0 ; test: 83.53 |
Reference
- http://www.aclweb.org/anthology/N18-2118
- 代码:https://github.com/MiuLab/SlotGated-SLU
- https://blog.csdn.net/shine19930820/article/details/83052232
- 添加CRF,有微小提升,代码地址:[https://github.com/InsaneLife/Joint-NLU]