事件相机 [CVPR 2020] EventSR: Events to Image Reconstruction, Restoration, Super-Resolution
CVPR2020
EventSR: From Asynchronous Events to Image Reconstruction, Restoration, and Super-Resolution via End-to-End Adversarial Learning

Err,由于题目太长了,所以标题就只能去掉几个单词了。。。
目录
CVPR2020
EventSR: From Asynchronous Events to Image Reconstruction, Restoration, and Super-Resolution via End-to-End Adversarial Learning
Abstract
Introduction
Related Works
Proposed Methods
Event embedding and datasets
Loss functions and training strategy of EventSR
Abstract
Event cameras sense intensity changes and have many advantages over conventional cameras. To take advantage of event cameras, some methods have been proposed to reconstruct intensity images from event streams. However, the outputs are still in low resolution (LR), noisy, and unrealistic. The low-quality outputs stem broader applications of event cameras, where high spatial resolution (HR) is needed as well as high temporal resolution, dynamic range, and no motion blur.
motivation:
一些方法已经提出从事件流重建强度图像,但这些方法的输出仍然是低分辨率 (LR),噪声和不现实的。
低质量的输出阻碍了事件相机的广泛应用,因为它不仅需要高的空间分辨率,还需要高的时间分辨率、动态范围和无运动模糊。
We consider the problem of reconstructing and super-resolving intensity images from LR events, when no ground truth (GT) HR images and downsampling kernels are available.
To tackle the challenges, we propose a novel end-to-end pipeline that reconstructs LR images from event streams, enhances the image qualities, and upsamples the enhanced images, called EventSR.
For the absence of real GT images, our method is primarily unsupervised, deploying adversarial learning. To train EventSR, we create an open dataset including both real-world and simulated scenes. The use of both datasets boosts up the network performance, and the network architectures and various loss functions in each phase help improve the image qualities. The whole pipeline is trained in three phases. While each phase is mainly for one of the three tasks, the networks in earlier phases are finetuned by respective loss functions in an end-to-end manner.
本文工作:
第一句,给出了本文的核心研究问题:在没有 ground truth (GT) HR 图像和 downsampling kernel 可用的情况下,考虑 LR 事件的重建和超分辨强度图像的问题。
第二句,给出了本文的核心研究任务:提出了一种新的端到端的 pipeline,该 pipeline 可以 1)从事件流重构 LR 图像,2)增强图像的质量,3)并对增强后的映像进行上采样,该 pipeline 称为 EventSR。
最后部分,给出了本文的核心研究内容:由于缺乏真实的GT图像,本文的方法主要是无监督的,部署对抗性学习。为了训练 EventSR,创建了一个包括真实场景和模拟场景的开放数据集。两种数据集的使用提高了网络性能,各阶段的网络架构和各种损失函数有助于提高图像质量。整个 pipeline 的训练分三个阶段进行。虽然每个阶段针对三个任务中的一个,在较早的阶段,网络是由各自的损失函数在端到端方式进行微调。
Experimental results show that EventSR reconstructs high-quality SR images from events for both simulated and real-world data. A video of the experiments is available at https://youtu.be/OShS_MwHecs.
实验结果:
EventSR 能够从模拟和真实数据的事件重建高质量的SR图像。
Introduction
前言就是一个漏斗,从大到小,从宽到窄。具体地,就是从非常大的背景,逐步缩小到本文要具体解决的某个方面的问题。
Event cameras are bio-inspired sensors that sense the changes of intensity at the time they occur and produce asynchronous event streams [24, 44, 18], while conventional cameras capture intensity changes at a fixed frame rate. This distinctive feature has sparked a series of methods developed specific for event cameras [37], and only recently, generic learning algorithms were successfully applied to event-based problems [44, 53, 46, 32, 7].
第一段:事件相机大背景介绍。告诉读者,本文研究的是 事件相机。
Event cameras (e.g., DAVIS 240) convey clear advantages such as very high dynamic range (HDR) (140dB) [24], no motion blur and high temporal resolution (1µs), and it has been shown that an event camera alone is sufficient to perform high-level tasks such as object detection [27], tracking [14], and SLAM [19]. In addition, as its potential, event streams might contain complete visual information for reconstructing high quality intensity images and videos with HDR and no motion blur. However, state-ofthe-arts (SOTA) [44, 32, 29, 3] for intensity image reconstruction suffer due to accumulated noise and blur (out of focus) in stacked events and low resolution (LR) of event cameras. The active pixel sensor (APS) images are with low dynamic range, LR and blur. The reconstructed images thus typically are in LR and with artifacts. Although [19, 35] focused HR for event cameras, namely spherical HR image mosaicing and HR panorama of events, respectively, they did not consider image-plane HR intensity image reconstruction and its perceptual realisticity.
第二段:提出具体的方向。告诉读者,本文研究的是 事件相机 的 图像重构 问题。
由于叠加事件中累积的噪声和模糊 (失焦) 以及事件相机的低分辨率 (LR),[44, 32, 29, 3] 图像重建会受到影响。有源像素传感器 (APS) 图像具有低动态范围,低 LR 和模糊等特征。因此,重建的图像通常是 LR 并存在伪影。虽然 [19,35] 分别针对事件相机聚焦 HR,即球形 HR 图像拼接和 HR 事件全景,但没有考虑像平面 HR 强度图像重建及其感知现实性。
In this work, we strive to answer the question, ‘is it possible to directly super-resolve LR event streams to reconstruct image-plane high quality high resolution (HR) intensity images?’ The challenges aforementioned render the reconstruction of HR intensity images ill-posed. The problem of reconstructing, restoring (e.g. denoising/deblurring), and super-resolving intensity images from pure event streams has not been convincingly excavated and substantiated. We delve into the problem of reconstructing high-quality SR intensity images with HDR and no motion blur.
第三段:提出具体的问题。告诉读者,本文研究的是 事件相机 的 重构 高质量高分辨率 (HR) 强度图像 的问题。指出了这个问题是全新的挑战。
For conventional camera images, deep learning (DL) based methods have achieved significant performance gains on single image super-resolution (SISR) using LR and HR image pairs [36, 23, 45]. Most of the works assume that the downsampling methods are available and LR images are pristine. When it comes to event cameras, either stacked events or APS images are noisy and blurred, and GT HR images are unavailable, let alone the degradation models. It is less clear if such DL methods work for event cameras.
第四段:说明本文的难度。从这段开始,就将很宽的研究领域聚焦到非常具体的问题上面来。
对于传统相机图像,基于深度学习 (DL) 的方法使用 LR 和 HR 图像对在单图像超分辨率 (SISR) 上取得了显著的性能提高[36,23,45]。大多数研究假设下采样方法是可用的,LR 图像是干净的。当涉及到事件相机,无论堆叠的事件还是 APS 图像都是嘈杂和模糊的,且 GT HR 图像是不可用的,更不用说退化模型。目前还不清楚这种 DL 方法是否适用于事件摄像机。
1. Inspired by the development of DL on image translation [54, 43], denoising/debluring [49, 22], and SISR [47, 52], and some recent successes in DL on event camera data [53, 44], we probe unsupervised adversarial learning to the problem of reconstructing HR intensity images from LR event streams. The results obtained demonstrate the efficacy of our method. To the best of our knowledge, this is the first work for recontructing HR intensity images by superresolving LR event streams.
2. The proposed pipeline consists of three major tasks.
First, 1) we reconstruct LR images from LR event streams. However, these reconstructed images are usually noisy, blurred and unrealistic.
2) So, we then restore (deblur/denoise) realistic LR intensity images from events.
3) Finally, we super-resolve the restored LR images to SR images from events as shown in Fig. 1.
Figure 1: Reconstructing realistic HDR SR intensity image from pure events. EventSR reconstructs LR HDR intensity image, restores realistic LR image and finally generates SR image (with scale factor of ˆ4) from events in phase 1,2 and 3, respectively.
3. Our framework is an end-to-end learning approach and, for more efficient training, we propose phase-to-phase network training strategy. The losses of later phases are back-propagated to the networks of earlier phases. The various loss functions and detailed network architectures are also important to best qualities. We build an open dataset containing 110K images for event to SR image reconstruction, using an event camera simulator [31], event camera dataset [28], and also RGB SR dataset [48, 41]. The conjunctive and alternative use of both real-world and simulated data for EventSR effectively boosts up the network performance.
4. Experimental results using both the simulated dataset [44] and real-world dataset [28] show that EventSR achieves significantly better results than the SOTAs [44, 3, 29].
5. In summary, our contributions are: 1) the first pipeline of reconstructing image-plane HR intensity images from LR events considering image restoration, 2) an open dataset to train EventSR for event-based super-resolution and the skills of using it for high performance training, 3) the proposed detail architecture, loss functions and end-to-end learning strategy, and 4) better results than the SOTA works for image reconstruction. Our dataset is open at https://github.com/ wl082013/ESIM_dataset.
![事件相机 [CVPR 2020] EventSR: Events to Image Reconstruction, Restoration, Super-Resolution_第1张图片](http://img.e-com-net.com/image/info8/d7ff50c3106a43c5af3f8865c9af9ba3.jpg)
第五段:说明本文的具体方法和贡献。
具体的逻辑过程是:
1. 简单概括:本文的方法是一个 从 LR 事件流中重建 HR 强度图像的无监督对抗学习问题;结果证明了该方法的有效性;是第一个通过超分辨 LR 事件流来重新构造 HR 强度图像的工作。
2. 具体任务:1)从LR事件流重建LR图像;2)从事件中恢复 (去模糊/去噪) 真实的 LR 强度图像;3)将恢复的 LR 图像超分辨为 SR 图像。
3. 训练方法:端到端的学习方法;提出了阶段到阶段的网络训练策略;后面阶段的损失误差被反向传播到前面阶段的网络中;各种损失函数和网络结构起到了高质量输出的作用;构建了新的数据集(使用事件摄像机模拟器 [31],事件摄像机数据集 [28],以及 RGB SR 数据集 [48, 41]);
4. 实验结论。
5. 贡献总结:1) 首次提出从 LR 事件中重建 image-plane HR强度图像的 pipeline; 2) 基于事件的超分辨率的数据集; 3) 提出了架构,损失函数和端到端学习策略;4) 比 SOTA 更好的结果。
数据集在 https://github.com/ wl082013/ESIM_dataset。
Related Works
- Events to intensity image reconstruction
The first attempt of reconstructing intensity images from events was done by [8] using rotating visual interpretations. Later on [18] tried to reconstruct 2D panoramic gradient images from a rotating event camera and [19] further delved into reconstructing HR masaic images based on spherical 3D scenes. Besides, Bardow et al. [3] proposed to estimate optical flow and intensity changes simultaneously via a variational energy function. Similarly, Munda et al. [29] regarded image reconstruction as an energy minimization problem defined on manifolds induced by event timestamps. Compared to [29], Scheerlinck et al. [37] proposed to filter events with a high-pass filter prior to integration. Recently, DL-based approaches brought great progress on intensity image and video reconstruction. Wang et al. [44] proposed to use GAN [15, 4, 43] to reconstruct intensity images and achieved the SOTA performance. In contrast, Rebecq et al. [32] exploited recurrent networks to reconstruct video from events. They also used an event sensor with VGA (640ˆ480 pixels) resolution to reconstruct higher resolution video, however, the problem is essentially different from our work.
[8] Interacting maps for fast visual interpretation.
[18] Simultaneous mosaicing and tracking with an event camera (BMVC2014) :重建二维全景梯度图像。
[29] Real-time intensity-image reconstruction for event cameras using manifold regularisation(IJCV2018):将图像重建看作是定义在由事件时间戳引起的流形上的能量最小化问题。
[37] Continuous-time intensity estimation using event cameras (ACCV2018):建议在集成前用高通滤波器过滤事件
[44] Event-based high dynamic range image and very high frame rate video generation using conditional generative adversarial networks (CVPR2019):使用GAN[15,4,43]重建强度图像
- Deep learning on event-based vision
Reinbacher et al. [35] considered sub-pixel resolution to create a panorama for tracking with much higher spatial resolution of events, however, not of intensity image reconstruction. Alonso et al. [1] further used an encoder-decoder structure for event segmentation. In contrast, Zhu et al. [53] utilized an encoder-decoder network for optical flow, depth and egomotion estimation via unsupervised learning. Besides, Cannici et al. [7] refined YOLO [33] for event-based object detection. Moreover, [46] and [6] both utilized CNNs for human pose and action recognition. Meanwhile, to analyze event alignment, Gallego et al. [12, 11] proposed some loss and optimization functions,which are further applied to motion compensation [39], flow estimation [53], etc.
深度学习的 基于事件相机 的视觉任务:
tracking;event segmentation;optical flow, depth and egomotion estimation;object detection;human pose and action recognition; motion compensation;flow estimation 。
- Deep learning on image restoration/enhancement
Image restoration addresses the problem of unsatisfactory scene representation, and the goal is to manipulate an image in such a way that it will in some sense more closely depict the scene that it represents [34] by deblurring and denoising from a degraded version. While the objective of image enhancement is to process the image (e.g. contrast improvement, image sharpening, super-resolution) so that it is better suited for further processing or analysis [2]. Recently, CNN has been broadly applied to image restoration and enhancement. The pioneering works include a multilayer perception for image denoising [5] and a three-layer CNN for image SR [9]. Deconvolution was adopted to save computation cost and accelerate inference speed [10, 38]. Very deep networks were designed to boost SR accuracy in [20, 25]. Dense connections among various residual blocks were included in [51]. Similarly, CNN- and GAN-based methods were developed for image denoising in [26, 22, 47, 52].
Proposed Methods
Our goal is to reconstruct SR images 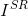 from a stream of events
from a stream of events  . To feed events to the network, we consider merging events based on the number of incoming events to embed them into images as done in [44, 53]. We then propose a novel unsupervised framework that incorporates namely, event to image reconstruction (Phase 1), event to image restoration (Phase 2), and event to image superresolution (Phase 3) as shown in Fig. 2. We train the whole system in a sequential phase-to-phase manner, than learning all from scratch. This gradually increases the task difficulty to finally reconstruct SR images. In each phase, the networks of earlier phases are updated thus in an end-to-end manner. More details are given in Sec. 3.2.
. To feed events to the network, we consider merging events based on the number of incoming events to embed them into images as done in [44, 53]. We then propose a novel unsupervised framework that incorporates namely, event to image reconstruction (Phase 1), event to image restoration (Phase 2), and event to image superresolution (Phase 3) as shown in Fig. 2. We train the whole system in a sequential phase-to-phase manner, than learning all from scratch. This gradually increases the task difficulty to finally reconstruct SR images. In each phase, the networks of earlier phases are updated thus in an end-to-end manner. More details are given in Sec. 3.2.
![事件相机 [CVPR 2020] EventSR: Events to Image Reconstruction, Restoration, Super-Resolution_第2张图片](http://img.e-com-net.com/image/info8/56fefb11d3e34ec1816d563d572bbc9b.jpg)
Figure 2: An illustration of the proposed EventSR consisting of three phases: event to image reconstruction (Phase 1), event to image restoration (Phase 2), and event to image super-resolution (Phase 3) via unsupervised adversarial learning. With well designed training and test dataset, EventSR not only works well for simulated but also for real-world data with HDR effects and motion blur.
整体介绍了本文的思想:
事件到图像重建(第一阶段),事件到图像恢复(第二阶段),事件到图像超分辨率(第三阶段)
关键是训练方式:以循序渐进的方式训练整个系统,而不是从头开始学习。这逐渐增加了最终重建SR图像的任务难度。在每个阶段,较早阶段的网络以端到端方式更新。
[44] Event-based high dynamic range image and very high frame rate video generation using conditional generative adversarial networks (CVPR2019):使用GAN[15,4,43]重建强度图像
Event embedding and datasets
- Event embedding
To process event streams using CNNs, we need to stack events into an image or fixed tensor representation as in [44, 53]. An event camera interprets the intensity changes as asynchronous event streams. An event
is represented as a tuple
, where
are pixel coordinates,
is the timestamp of the event, and
is the polarity indicating the sign of brightness change.
A natural choice is to encode the events in a spatial-temporal 3D volume or voxel grid [53, 44]. Here, we consider representing 3D event volume by merging events based on the number of events as shown in Fig 3. We reduce event blur (out of focus) by adjusting event sharpness and also variance (contrast) as in [11].
The first
events are merged into frame one, and next
to create one stack with
events will be fed as input to EventSR. In Fig 3, S1, S2, S3 and S4 are the frames containing different number of events
,
,
, respectively. The event embedding method guarantees rich event data as inputs for EventSR and allows us to adaptively adjust
Figure 3: An illustration of event embedding and dataset creation for training EventSR. More details are in the main context.
![事件相机 [CVPR 2020] EventSR: Events to Image Reconstruction, Restoration, Super-Resolution_第3张图片](http://img.e-com-net.com/image/info8/0fb4fda781fc490b968d0526688181b9.jpg)
事件数据需要通过一定的处理,才能送入网络中。
一般有两种处理方式:spatial-temporal 3D volume or voxel grid。本文选用前者。
具体地,第一组 ![]() 个事件合并到第一帧中,下一组
个事件合并到第一帧中,下一组 ![]() 个合并到第二帧中,然后将 帧组成一个 stack。因此,包含事件的一个 stack 包含
个合并到第二帧中,然后将 帧组成一个 stack。因此,包含事件的一个 stack 包含 ![]() 个事件,将作为输入提供给 EventSR。在图 3 中,S1、S2、S3 和 S4 分别是包含不同数量事件
个事件,将作为输入提供给 EventSR。在图 3 中,S1、S2、S3 和 S4 分别是包含不同数量事件 ![]() ,
, ![]() ,
, ![]() ,
, ![]() 的帧。
的帧。
- EventSR dataset
这段比较长,我们可以分解来看
1. One crucial contribution of this work is to build a dataset including both simulated and real-world scenes for training EventSR. As mentioned in Sec. 1, real events are noisy and out of focus. Besides, real APS images are degraded with blur, noise and low dynamic range. Therefore, training with only real-world data is not optimal, also shown in [44], and not enough to reconstruct SR images.
1. 为什么要建立这个数据集?
本文的一个重要贡献就是 构建包含模拟和真实场景的数据集。
真实的事件是含噪声的的,焦距模糊的。真实 APS 图像存在模糊、噪声和低动态范围等问题。因此,仅使用真实数据进行训练并不是最优的,不足以重建SR图像。
2. We propose a novel EventSR dataset including both real and simulated events. We utilize both data conjunctively and alternatively in each phase of training as shown in Fig. 3 and Table. 1, and demonstrate that it works well.
For the simulated data, there are three categories for different purposes.
First, we use the dataset proposed by [44] for comparisons in intensity image reconstruction.
Second, in order to better handle the ill-posed problem caused by real-world data [44], we utilize the reference color images from the event camera dataset [28]. This brings a simulated dataset called ESIM-RW (around 60K) using the event simulator (ESIM) [31]. The networks trained using the dataset generalises well to real event data.
We also take the standard RGB SR dataset [48, 41] to make ESIM-SR dataset (around 50K).
![事件相机 [CVPR 2020] EventSR: Events to Image Reconstruction, Restoration, Super-Resolution_第4张图片](http://img.e-com-net.com/image/info8/200304aa96fa44deaab9cd22e180ff3e.jpg)
2. 数据集组成。
提出了一个新的 EventSR 数据集,包括真实和模拟事件。如图 3 和表 1 所示,在训练的每个阶段结合使用和交替使用数据,并证明其效果良好。
对于模拟数据,有三类用于不同的目的。
首先,我们使用 [44] 提出的数据集(ESIM data)进行图像重建强度的比较。
其次,为了更好地处理由真实数据 [44] 引起的不适定问题,利用了来自事件摄像机数据 [28] 的参考彩色图像。使用事件模拟器 (ESIM) [31] 得到 ESIM- RW (约60K) 的模拟数据集。使用数据集训练的网络可以很好地推广到真实的事件数据。
第三,采用标准的 RGB SR 数据集 [48,41] 来制作 ESIM-SR 数据集(大约50K)。
[44] Event-based high dynamic range image and very high frame rate video generation using conditional generative adversarial networks (CVPR2019):使用GAN[15,4,43]重建强度图像
[28] The event-camera dataset and simulator: Event-based data for pose estimation, visual odometry, and slam
[31] ESIM: an open event camera simulator (In Conference on Robot Learning, 2018)
[48] On single image scale-up using sparse-representations.
[41] Ntire 2018 challenge on single image super-resolution: Methods and results (CVPR 2018)
3. However, note that ESIM generates multiple synthetic events and APS images (cropped and degraded) given one HR color image, which renders the SR problem without real GT, thus making it difficult to evaluate the quality of reconstructing SR images from events.
We use ESIM to create ESIM-SR1 dataset with image size (256
256) for training phase 1 and phase 2. To numerically evaluate the SR quality, we create ESIM-SR2 dataset, where we set ESIM to output ‘HR’ APS images with larger size (e.g. 1024
3. 数据集的一个问题:SR 没有 GT,无法客观评价。
问题:注意,给定一个 HR 的彩色图像,ESIM 生成多个合成事件和 APS 图像 (裁剪和分解),这使得 SR 问题没有真正的 GT,因此很难评估从事件重建 SR 图像的质量。
解决:首先,使用 ESIM 创建图像大小 (256256) 的 ESIM-SR1 数据集,用于阶段 1 和阶段 2 的训练。为了用数值评估 SR 质量,又创建 ESIM-SR2 数据集,其中输出较大的 “HR” APS 图像 (例如10241024) 如表1 所示。然后将 SR 向下采样 (例如 bicubic) 到较小的尺寸 (256256) 作为 LR 图像。 (注意:不同于一般的 SR 问题,这些 “HR” APS图像是低质量 (不清楚棱角) 。但是,它们可以用来评估 SR。)
4. However, reconstructing LR images up to the quality level of these ‘HR’ APS images does not achieve our goal since we want to generate realistic SR images. Thus, we exploit a real-world dataset for phase 3.
For the realworld dataset, we directly make Ev-RW dataset using the event camera dataset [28] including general, motion blur and HDR effects.
4. 数据集的又一个问题:生成真实 SR 图。
问题:将 LR 图像重建到这些 “HR” APS 图像的质量水平并不能达到我们的目标,因为我们想生成真实的 SR 图像。
解决:因此,为阶段 3 使用一个真实的数据集。直接使 Ev-RW 数据集(使用事件摄像机数据集 [28]),包括一般,运动模糊和HDR 效果。
5. It has been shown that using real event and APS pairs for reconstructing SR images is difficult [44]. Instead, in phase 1, we use ESIM-RW dataset, which is crucial for training EventSR. In phase 2, we first refine the real APS images through phase 1 to get clean APS images (the reason is given in Eq. (4)), then use them for event to image restoration. Lastly, for phase 3, we convert the RGB SR images to grayscale as SR-RW dataset, and it turns out they are crucial for training EventSR. The trained EventSR generalizes well for both simulated and real data, and also the data with HDR effects as shown in Fig. 3 and Table. 1.
5. 训练方式。前面介绍了数据集,现在介绍如何使用这些数据集。
用真实事件和 APS 来重建 SR 图像是困难的。相反,在第一阶段,我们使用 ESIM-RW 数据集,这对训练 EventSR 至关重要。第二阶段通过第一阶段对真实的 APS 图像进行细化,得到干净的 APS 图像 (原因见 Eq.(4)),然后将其作为事件进行图像恢复。最后,在第三阶段,我们将 RGB 的 SR 图像转换为灰度作为 SR-RW 数据集,结果表明它们对于训练 EventSR 是至关重要的。经过训练的 EventSR 对模拟数据和真实数据,以及图 3 和表 1 所示的具有 HDR 效应的数据都具有很好的通用性。
Loss functions and training strategy of EventSR
As shown in Fig. 2, EventSR consists of three phases: event to image reconstruction, event to image restoration and event to image super-resolution. EventSR includes three network functionals G, F, and D in each phase.
Event to image reconstruction (Phase 1)
In order to obtain SR images, we first reconstruct images from the event streams. Our goal is to learn a mapping
, aided by an event feedback mapping
, and the discriminator
. The inputs are unpaired training events
and the LR intensity images
.
第一阶段目标:从 event 到 ![]() ;即
;即 ![]() 。
。
策略:由于没有 GT,是无监督的,所以用了 Cycle GAN 的方式进行训练。
Event to image restoration (Phase 2)
Since the reconstructed images are noisy, blurry, and unrealistic, we then aim to restore (denoise/ deblur) images using both events
. The goal of phase 2 is to learn a mapping
, an event feedback mapping
, and the discriminator
. The inputs are unpaired events
第二阶段目标:(由于第一阶段的 ![]() 含有噪声,模糊,不真实)将
含有噪声,模糊,不真实)将 ![]() 复原到干净的
复原到干净的 ![]() ;即
;即![]() 。
。
策略:由于没有 GT,是无监督的,所以用了 Cycle GAN 的方式进行训练。但注意了,这里的 Cycle GAN,输入是事件event,而不是第一阶段输出的 ![]() ;生成器是 Gr 和 Gd 两个部分;反馈生成器 Fd 的输出是 event。
;生成器是 Gr 和 Gd 两个部分;反馈生成器 Fd 的输出是 event。
Event to image super-resolution (Phase 3)
We then reconstruct SR images from events, utilizing the stacked events
. The problem is to learn a mapping
, an event feedback mapping
(原文错了,下标应该是 s), and the discriminator
.
第三阶段目标:将 ![]() 超分辨到
超分辨到 ![]() ;即
;即 ![]() 。
。
策略:由于没有 GT,是无监督的,所以用了 Cycle GAN 的方式进行训练。但注意了,这里的 Cycle GAN,输入是事件event,而不是第二阶段输出的 ![]() ;生成器是 Gr,Gd 和 Gs 三个部分;反馈生成器 Fs 的输出是 event。
;生成器是 Gr,Gd 和 Gs 三个部分;反馈生成器 Fs 的输出是 event。
- Loss functions for EventSR training
The loss functional for each phase is defined as a linear combination of four losses as:
(1)
where
,
,
,
are the discriminator, event similarity, identity, and total variation losses, respectively. Note D and F are the relevant networks of each stage, and
is an accumulated one i.e.
, in phase 1, 2, and 3. The loss for phase 1,2 and 3 is denoted as
,
and
, respectively.
损失函数整体定义,这里给出的公式(1)是指每个阶段都采用的形式,具体到每个阶段,需要加上标,也就是说,训练时一共要计算 4x3=12 个损失函数。另外,对于每个阶段,![]() 是指对应的
是指对应的 ![]() 。
。
Adversarial loss
Given stacked events
. The adversarial loss is:
(2)
We observe standard GAN training is difficult in phase 3. To stabilize the training and make optimization easier, we use the adversarial loss based on the Relativistic GAN [17].
对于每个阶段,采用的对抗损失函数如公式(2)。但是,对于第三阶段,为了 GAN 的稳定性和易于优化,采用 Relativistic GAN [17]。
[17] The relativistic discriminator: a key element missing from standard GAN (ICLR 2019)
Event similarity loss
Since events are usually sparse, we found using pixel-level loss too restrictive and less effective. Here, we propose a new event similarity loss that is based on the interpolation of the pixel-level loss and the perceptual loss based VGG19 inspired by [16]. Namely, we measure the similarity loss of the reconstructed events
and the input events
and the perceptual loss as:
where Φi is the feature map from i-th VGG19 layer, and Ci , Hi , and Wi are the number of channel, height, and width of the feature maps, respectively.
event similarity loss 就是计算传统的 ![]() and the perceptual loss;计算对象是
and the perceptual loss;计算对象是 ![]() 和
和 ![]() 。
。
Identity loss
For better learning from events, and also to avoid brightness and contrast variation among different iterations, we utilize the identity loss
to train Gd in phase 2.
where
and
and
Total variation loss
Since stack events are sparse, the generated images are spatially not smooth. To impose the spatial smoothness of the generated images, we add a total variation loss:
where ∇h and ∇w are the gradients of
采用的 ![]() 原因是,由于 stack 事件是稀疏的,生成的图像在空间上不平滑。对生成的图像进行空间平滑。
原因是,由于 stack 事件是稀疏的,生成的图像在空间上不平滑。对生成的图像进行空间平滑。
- Learning strategy and network structure
End-to-end learning
We have described the pipeline of reconstructing, restoring, and attaining SR images from events. We then explore how to unify three phases and train EventSR in an end-to-end manner. Under the unified learning, the second phase becomes auxiliary to the first and the third stage auxiliary to the second and the first. The total loss is:
第二阶段会重新辅助第一阶段进行训练(看图 2,第二阶段的生成器包括第一阶段的 Gr);同理,第三阶段会重新辅助第一、二阶段。
Phase-to-phase learning
Rather than learning all network parameters from scratch all together, to facilitate the training, we propose a learning strategy called phase-to-phase learning where we start with an easy task and then gradually increase the task difficulty. Specifically, we first start with Gr with Dr, Fr. We then strengthen the task difficulty by fusing Gr and Gd. We train Gd and Dd, Fd from scratch, meanwhile, fine-tuning Gr. Note each loss term has
in the phase 2. The loss gradients back-propagated to Gr, and Dr, Fr are also updated respectively. We lastly fuse Gs with both Gr and Gd from events. We train the Gs, Ds, Fs from scratch, while fine-tuning both Gr, Gd simultaneously. The generation function
.
首先,训练 Gr with Dr, Fr;
然后,从零开始对 Gd、Dd、Fd 进行培训,同时对 Gr 进行微调;
最后,将事件中的 Gs 、Gr 和 Gd 融合在一起。从零开始训练 Gs, Ds, Fs,同时微调 Gr, Gd。
Network Architecture
As shown in Fig. 2, EventSR includes three generators, Gr, Gd and Gs, and three discriminators, Dr and Dd and Ds. For convenience and efficiency, we design Gr, Gd to share the same network structure. For Gs, we adopt the SOTA SR networks [45, 23]. We also set Dr, Dd, and Ds to share the same network architecture. To better utilize the rich information in events, we also design an event feedback module including Fr, Fd, and Fs, sharing the same network structures based on ResNet blocks. However, for Fs, it has down-sampling operation, so we set the stride with 2 instead. Through the event feedback module, the generators learn to fully utilize the rich information from events to reconstruct, restore, and super-resolve images from events.
网络结构包括
生成器 Gr,Gd,Gs:Gr,Gd 结构相同;Gs 采用 [45, 23] 的结构。
判别器 Dr,Dd,Ds:采用相同结构。
反馈器 Fr,Fd,Fs:采用相同结构;Fs 多一个下采样过程。
[45] Esrgan: Enhanced super-resolution generative adversarial networks (ECCVW 2018)
[23] Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network (CVPR 2017)