Elasticsearch全文搜索引擎
一.关于Elasticsearch
Elasticsearch是一个基于Lucene的搜索服务器。是一个分布式、高扩展、高实时的搜索与数据分析引擎,基于RESTful web接口。Elasticsearch是用Java语言开发的,并作为Apache许可条款下的开放源码发布,是一种流行的企业级搜索引擎。Elasticsearch用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便
二.安装Elasticsearch
首先去ES官网根据自己的环境去下载,注意Elasticsearch 的硬性要求要确保jdk版本要在1.8以上,可以根据java -version自行查看,如果嫌弃官网太慢可以从此处下载,我这里是linux环境
下载完后对文件接行解压,之后./elstaicsearch 执行bin目录下面的elstaicsearch文件

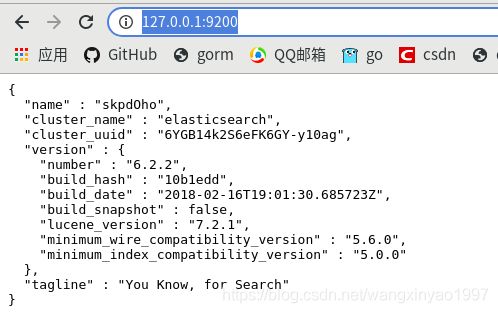
等待执行完成之后,访问http://127.0.0.1:9200/ (9200是elasticsearch默认端口,和mysql的3306一个道理),访问之后如下说明成功:
为了Elasticsearch的数据可视化,所以推荐安装 Kibana,这是一个官方推出的把 Elasticsearch 数据可视化的工具,里面有一个 Dev Tools 的工具可以方便的和 Elasticsearch 服务进行交互,慢的话可以点击此处地址下载,同样按照上面原理一样,执行bin目录下的kibana执行文件

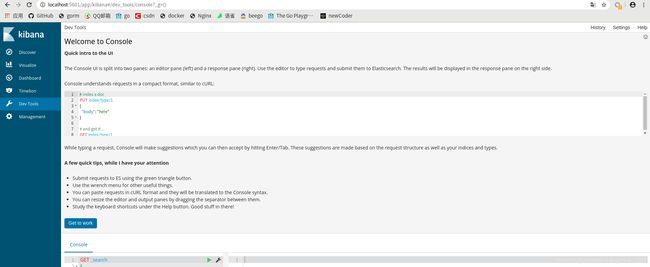
等待一段时间后就可以看到提示信息,运行在 5601 端口,访问地址 http://localhost:5601/app/kibana#/dev_tools/console?_g=() 可以成功进入到 Dev-tools 界面:
点击 【Get to work】,然后在控制台输入 GET /_cat/health?v 查看服务器状态,可以在返回的结果中看到 green 即表示服务器状态目前是健康的:

三.Elasticsearch使用
1.ElasticSearch基本描述
- 节点 Node、集群 Cluster 和分片 Shards
ElasticSearch 是分布式数据库,允许多台服务器协同工作,每台服务器可以运行多个实例。单个实例称为一个节点(node),一组节点构成一个集群(cluster)。分片是底层的工作单元,文档保存在分片内,分片又被分配到集群内的各个节点里,每个分片仅保存全部数据的一部分。 - 索引 Index、类型 Type 和文档 Document
对比mysql来说如下,就是说访问一个文档元数据应该包括囊括 index/type/id 这三种类型
index → db
type → table
document → row
2.RESTful API 与 Elasticsearch 进行交互
所有其他语言可以使用 RESTful API 通过端口 9200 和 Elasticsearch 进行通信,可以通过web 客户端访问 Elasticsearch,一个 Elasticsearch 请求和任何 HTTP 请求一样由若干相同的部件组成:
curl -X '://:/?' -d ''
- VERB:适当的 HTTP 方法 或 谓词 : GET、 POST、 PUT、 HEAD 或者 DELETE等
- PROTOCOL:http或者 https
- HOST:Elasticsearch 集群中任意节点的主机名
- PORT: Elasticsearch HTTP 服务的端口号,默认是 9200
- PATH:API 的终端路径(例如 _count 将返回集群中文档数量),Path 可能包含多个组件,例如:_cluster/stats 和 _nodes/stats/jvm
- QUERY_STRING:任意可选的查询字符串参数(例如 ?pretty 将格式化地输出 JSON 返回值,使其更容易阅读)
- BODY:一个 JSON 格式的请求体
比如计算集群中文档的数量,可以用:
curl -XGET 'http://localhost:9200/_count?pretty' -d '
{
"query": {
"match_all": {}
}
}
但是如果安装了Kibana,可以用:
GET /_count?pretty
{
"query": {
"match_all": {}
}
}
文档管理(CRUD)
C - 新增
POST /db/user/1
{
"username": "thinkao",
"password": "123456",
"age": "18"
}
POST /db/user/2
{
"username": "peter",
"password": "123456",
"age": "22"
}
解释就是往索引为 db 类型为 user 的数据库中插入一条 id 为 1 的一条数据,这条数据其实就相当于一个拥有 username/password/age 三个属性的一个实体,就是 JSON 数据,执行结果version 是版本号的意思,当我们执行操作会自动加 1
D - 删除
DELETE /db/user/1
执行完成后可以看到 version 变成 2
U - 修改
PUT /db/user/2
{
"username": "lisa",
"password": "123456",
"age": "22"
}
R - 查询
GET /db/user/2
搜索:上面已经演示了基本的文档 CRUD 功能,然而 Elasticsearch 的核心功能是搜索,为更好的演示这个功能,先往 Elasticsearch 中插入一些数据
PUT /movies/movie/1
{
"title": "The Godfather",
"director": "Francis Ford Coppola",
"year": 1972,
"genres": [
"Crime",
"Drama"
]
}
PUT /movies/movie/2
{
"title": "Lawrence of Arabia",
"director": "David Lean",
"year": 1962,
"genres": [
"Adventure",
"Biography",
"Drama"
]
}
PUT /movies/movie/3
{
"title": "To Kill a Mockingbird",
"director": "Robert Mulligan",
"year": 1962,
"genres": [
"Crime",
"Drama",
"Mystery"
]
}
PUT /movies/movie/4
{
"title": "Apocalypse Now",
"director": "Francis Ford Coppola",
"year": 1979,
"genres": [
"Drama",
"War"
]
}
PUT /movies/movie/5
{
"title": "Kill Bill: Vol. 1",
"director": "Quentin Tarantino",
"year": 2003,
"genres": [
"Action",
"Crime",
"Thriller"
]
}
PUT /movies/movie/6
{
"title": "The Assassination of Jesse James by the Coward Robert Ford",
"director": "Andrew Dominik",
"year": 2007,
"genres": [
"Biography",
"Crime",
"Drama"
]
}
_search端点
现在已经把一些电影信息放入了索引,可以通过搜索看看是否可找到它们。 为了使用 ElasticSearch 进行搜索,我们使用 _search 端点,可选择使用索引和类型。也就是说,按照以下模式向URL发出请求:
- http://localhost:9200/_search - 搜索所有索引和所有类型
- http://localhost:9200/movies/_search - 在电影索引中搜索所有类型
- http://localhost:9200/movies/movie/_search - 在电影索引中显式搜索电影类型的文档
搜索请求正文和ElasticSearch查询DSL
如果只是发送一个请求到上面的URL,我们会得到所有的电影信息。为了创建更有用的搜索请求,还需要向请求正文中提供查询。 请求正文是一个JSON对象,除了其它属性以外,它还要包含一个名称为 “query” 的属性,这就可使用ElasticSearch的查询DSL(DSL 它是ElasticSearch自己基于JSON的域特定语言,可以在其中表达查询和过滤器。你可以把它简单同SQL对应起来,就相当于是条件语句)
{
"query": {
//Query DSL here
}
}
基本自由文本搜索
ElasticSearch可将解析和转换为更简单的查询树,如果忽略了所有的可选参数,并且只需要给它一个字符串用于搜索,它可以很容易使用,如下:现在尝试在两部电影的标题中搜索有“kill”这个词的电影信息
GET /_search
{
"query": {
"query_string": {
"query": "kill"
}
}
}

指定搜索的字段
在前面例子中,使用了一个非常简单的查询,一个只有一个属性 “query” 的查询字符串查询。 如前所述,查询字符串查询有一些可以指定设置,如果不使用,它将会使用默认的设置值。
这样的设置称为“fields”,可用于指定要搜索的字段列表。如果不使用“fields”字段,ElasticSearch查询将默认自动生成的名为 “_all” 的特殊字段,来基于所有文档中的各个字段匹配搜索
为了做到这一点,修改以前的搜索请求正文,以便查询字符串查询有一个 fields 属性用来要搜索的字段数组:
GET /_search
{
"query": {
"query_string": {
"query": "ford",
"fields": [
"title"
]
}
}
}
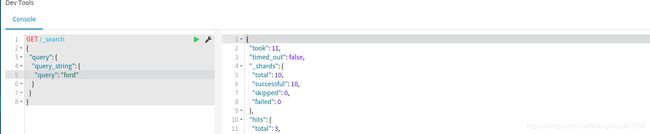
可以看到下图结果只搜索出一条数据,title为ford

现在,从查询中移除fields属性,应该能匹配到 3 行数据:
过滤
前面已经介绍了几个简单的自由文本搜索查询。现在来看看另一个示例,搜索 “drama”,不明确指定字段,如下查询
GET /_search
{
"query": {
"query_string": {
"query": "drama"
}
}
}
因为在索引中有五部电影在 _all 字段(从类别字段)中包含单词 “drama”,所以得到了上述查询的 5 个命中。 现在,想象一下,如果我们想限制这些命中为只是 1962 年发布的电影。要做到这点,需要应用一个过滤器,要求 “year” 字段等于 1962。要添加过滤器,修改搜索请求正文,以便当前的顶级查询(查询字符串查询)包含在过滤的查询中:
{
"query": {
"filtered": {
"query": {
"query_string": {
"query": "drama"
}
},
"filter": {
//Filter to apply to the query
}
}
}
}
过滤的查询是具有两个属性(query和filter)的查询。执行时,它使用过滤器过滤查询的结果。要完成这样的查询还需要添加一个过滤器,完整的搜索请求如下所示:
GET /_search
{
"query": {
"filtered": {
"query": {
"query_string": {
"query": "drama"
}
},
"filter": {
"term": {
"year": 1962
}
}
}
}
}
但是上述查询可能会报错 “reason”: “no [query] registered for [filtered]”,这是因为ES的新旧版本不支持导致,过滤查询已被弃用,可以自行更换如:
GET /_search
{
"query": {
"bool": {
"filter": {
"match_all": {}
},
"must": {
"match": {
"year": 1962
}
}
}
}
}
更简单的方法是使用常数分数查询
GET /_search
{
"query": {
"constant_score": {
"filter": {
"term": {
"year": 1962
}
}
}
}
}
3.springboot简单实例
pom.xml
org.springframework.boot
spring-boot-starter-data-elasticsearch
application.properties
spring.data.elasticsearch.cluster-nodes=127.0.0.1:9300
Entity实体类
@Document(indexName = "users", type = "user")
//indexName:对应索引库名称,type:对应在索引库中的类型
public class User {
private int id;
private String username;
private String password;
private int age;
//getter and setter
Dao层:
public interface UserDao extends ElasticsearchRepository {
}
Controller 层
@RestController
public class UserController {
@Autowired
private UserDao userDao;
@PostMapping("/add")
public String addUser(@RequestParam(name = "username") String username,@RequestParam(name = "password") String password,@RequestParam(name = "age") Integer age){
User user = new User();
System.out.println(username+","+password+","+age);
user.setUsername(username);
user.setPassword(password);
user.setAge(age);
return String.valueOf(userDao.save(user).getId());
}
@DeleteMapping("/delete")
public String deleteUser(Integer id){
userDao.deleteById(id);
return "success";
}
@PutMapping("/update")
public String updateUser(Integer id, String username, String password, Integer age){
User user = new User();
user.setId(id);
user.setUsername(username);
user.setPassword(password);
user.setAge(age);
return String.valueOf(userDao.save(user).getId());
}
@GetMapping("/get")
public User getUser(Integer id){
return userDao.findById(id).get();
}
@GetMapping("/getAll")
public Iterable getAllUsers() {
return userDao.findAll();
}
}
结语:总体来说使用 SpringBoot 来操作 Elasticsearch 的话使用方法有点类似 JPA ,当然在条件允许下把 Elasticsearch 当做 SQL 服务器来用也是可以de.