Joint Model (Intent+Slot)
0、BERT for Joint Intent Classification and Slot Filling
本文《BERT for Joint Intent Classification and Slot Filling》提出了使用BERT进行文本意图分类和槽位填充的任务,其结果达到了目前最好的成绩。
论文地址
github 地址
引言
意图识别/意图分类(Intent Classification)和槽位填充 (Slot Filling) 是自然语言理解 (Natural Language Understanding, NLU)领域中的两个比较重要的任务。在聊天机器人、智能语音助手等方面有着广泛的应用。
意图识别可以看作一个分类任务,就是对当前输入的句子进行分类,得到其具体意图,然后完成后续的处理。而槽位填充则是一个序列标注问题,是在得到意图之后,再对句子的每一个词进行标注,标注的格式为BIO格式,将每个元素标注为“B-X”、“I-X”或者“O”。其中,“B-X”表示此元素所在的片段属于X类型并且此元素在此片段的开头,“I-X”表示此元素所在的片段属于X类型并且此元素在此片段的中间位置,“O”表示不属于任何类型。比如tell me the weather report for half moon bay这句话中,它的意图类别为weather/find(查询天气),slot filling的结果为:
其中的NoLabel就是O,其它的slot filling结果如上所示。
数据集
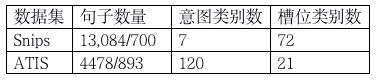
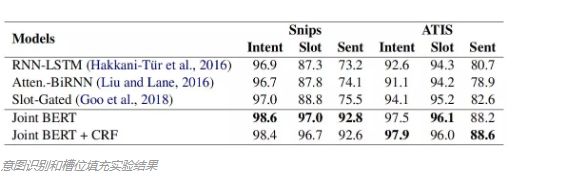
意图分类和槽位填充任务主要有两个数据集Snips和ATIS。数据集的概况如下表所示。其中句子(utterance)数量为训练集和测试集的数量。

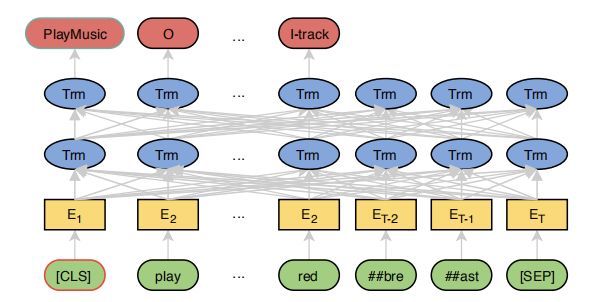
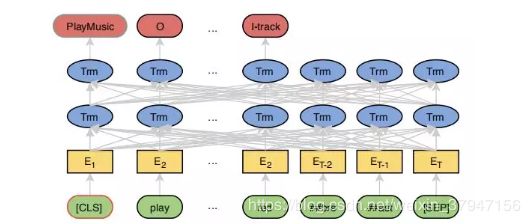
模型介绍
本文提出了使用BERT来进行意图识别和槽位填充,文章模型中的意图识别部分继续沿用了 BERT 的 [CLS] 部分进行分类,槽位填充除了直接用输出结果进行序列标注,另外还接了一层 CRF改善实验结果。模型细节如下图所示。
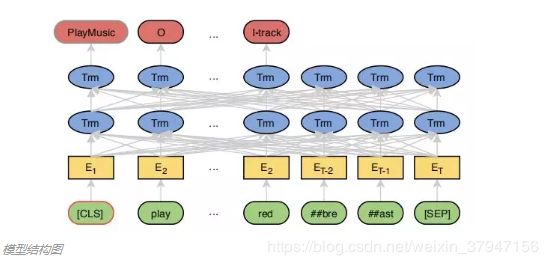
意图识别结果使用softmax对BERT的输出结果通过全连接层来得到不同意图的概率,其公式为:
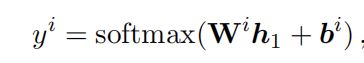
![]()
此模型中,BERT的输入是使用 WordPiece处理之后的词语,一个词可能会被拆成多个sub-token,比如 “redbreast”被拆成“##red”, “##bre”, “##ast”三部分,而此模型使用的是这些sub-token 中的第一个token作为输入。槽位标记也是使用softmax函数对每一个输出进行分类:
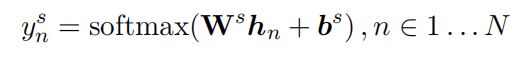
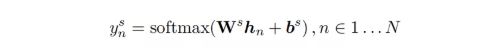
这两个任务联合训练时,需要最大化以下目标函数,使用cross-entropy作为分类的损失函数。

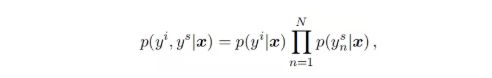
另外,本文还在BERT的输出加入CRF,测试相应的效果,CRF最终没有取得效果,其准确率反而会下降。
实验结果
目前在Snips和ATIS两个数据集上,本文的模型取得了最优的结果。同时也比较了加入CRF效果,加入CRF后准确率并没有提升。
1、第一篇Slot-Gated Modeling for Joint Slot Filling and Intent Prediction
github 地址(加入crf)
创新点:
- 提出slot-gate方法实现了最好的性能表现。
- 通过数据集实验表明slot-gate的有效性。
- slot-gate有助于分析槽位和意图的关系。

底部特征:
使用BILSTM结构,输入:x={ }, 输出:
attention:
slot filling :对于slot filling,x映射到其对应的槽标签序列 。 对于每个隐藏状态 ,我们通过学习的attention weight 计算slot上下文向量 作为LSTM的隐藏状态 的加权和:
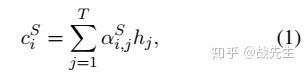
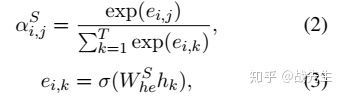
σ:激活函数
:前馈神经网络的权重矩阵。
:计算的是 和当前输入向量 之间的关系
T是attention维度,一般和输入向量一致
slot 标签计算公式:
![]()
:输入中第i个字的slot标签
:权重矩阵。
:the hidden state
:slot上下文向量
intent:
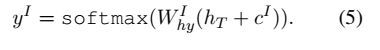
:intent 上下文向量,计算公式和 相似
:权重矩阵
:the hidden state
Slot-Gated Mechanism
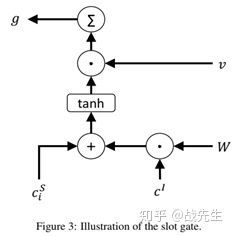
提出的Slot-gated模型引入了一个额外的gate,利用intent上下文向量来建模slot-intent关系,以提高槽填充性能。 首先,组合slot上下文向量 和intent上下文向量 以通过图3中所示的时隙门:
![]()
其中v和W分别是可训练的向量和矩阵。 在一个时间步骤中对元素进行求和。 g可以看作联合上下文向量(和)的加权特征。
加入g:
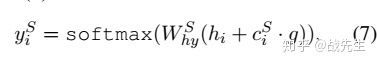
为了比较slot gate的作用,本文还提出了一个只包含intent attention的slot gate 模型,其中(6)和(7)分别改为(8)和(9)(如图2所示)b)):
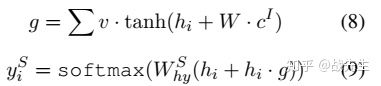
Joint Optimization
![]()
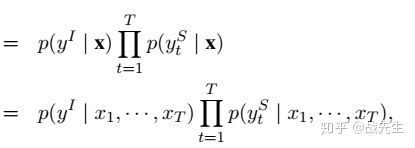
2. 第二篇文章主要利用双向的GRU+CRF作为意图与槽位的联合模型。
Zhang X, Wang H. A Joint Model of Intent Determination and Slot Filling for Spoken Language Understanding[C] IJCAI. 2016
模型如下:
- 输入为窗口化的词向量:
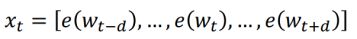
- 利用双向GRU模型学习到高维度特征。
- 意图与槽位
对于意图分类来说,利用每一个学习到的隐藏层特征,采用max pooling槽位得到全句的表达,再采用softmax进行意图的分类:
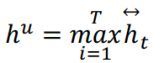
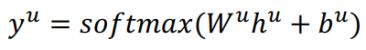
对于槽位来说,对每个隐藏层的输入用前向网络到各个标签的概率,并采用CRF对全局打分得到最优的序列。
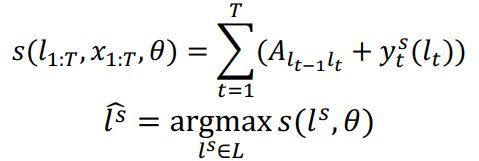
联合的损失函数为槽位与意图的极大似然
![]()
本文的模型简单而且槽位识别的准确率与意图识别的准确率都达到很高的水准,
本文的结果基于ATIS数据集:
Intent :98.32 Slot (F1):96.89
3. 第三篇主要采用利用语义分析树构造了路径特征对槽位与意图的识别的联合模型。(RecNN+Viterbi)
Guo D, Tur G, Yih W, et al. Joint semantic utterance classification and slot filling with recursive neural networks[C] 2014 IEEE. IEEE, 2014
先介绍下本文的basic Recursive NN的模型

输入为单个词向量(后续优化输入为窗口的词向量),每个词性被看作为权重向量(weight vector ),这样每个词在其路径的运算为简单的词向量与词性权重向量的点积运算。如上图中的方块为词性的权重向量与输入向量的点积运算后的结果。当一个父节点有多个孩子分支的时候,可以看成每个分支与权重点积的和运算。
意图识别模块
意图识别,该文章中直接采用根节点的输出向量直接做一个分类。
槽位识别
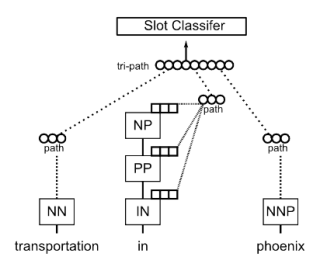
这一模块引入了路径向量的特征
![]()
如”in“这个单词,在语义分析树中的路径为”IN-PP-NP“,将该路径的每个输出向量做一个加权运算得到path的特征,本文采用了三个词的path特征的concat作为tri-path特征进行槽位的分类,从而进行对”in“的一个预测。
优化
文章中还在baseline的基础上做了一些优化:
优化输入为窗口的词向量
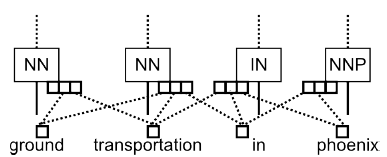
节点用与先前简单加权不同的网络,采用了非线性的激活函数
![]()
采用基于Viterbi的CRF优化全局,及采用了基于tri-gram的语言模型极大化标注序列
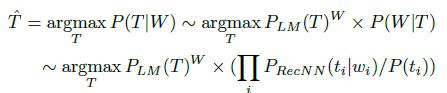
本文的结果基于ATIS数据集:
Intent :95.40 Slot (F1):93.96
4. 第四篇主要是基于CNN+Tri-CRF的模型
Xu P, Sarikaya R. Convolutional neural network based triangular crf for joint intent detection and slot filling 2013 IEEE Workshop on. IEEE, 2013
看一下篇CNN+TriCRF模型,模型框架如下:

对于槽位识别的模型
输入的为每个的词向量,经过一个卷积层得到高维特征h,随后经过Tri-CRF作为整体的打分。Tri-CRF与线性的CRF的区别是输入前用了一个前向网络得到每个标签的分类。我们来分析一下评分的公式:
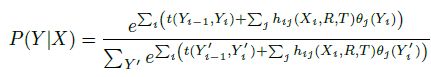
上述的t(Yi-1,Yi)为转移的打分,hij为CNN得到的高维特征,每个时刻的高维特征经过一个前向网络得到每个标签的概率,这样前两者的结合就是整体的打分。
对于意图识别
CNN采用同一套参数,得到每个隐藏层的高维特征h,直接采用max pooling得到整句的表达,用softmax得到意图分类。
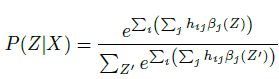
将上述结合起来实际上就是联合模型。
本文的结果基于ATIS数据集:
Intent :94.09 Slot (F1):95.42
5. 第五篇的主要是基于attention-based RNN
Liu B, Lane I. Attention-based recurrent neural network models for joint intent detection and slot filling[J]. 2016.
首先介绍一下context vector的概念,参见Bahdanau D, Cho K, Bengio Y. Neural machine translation by jointly learning to align and translate[J]. 2014.
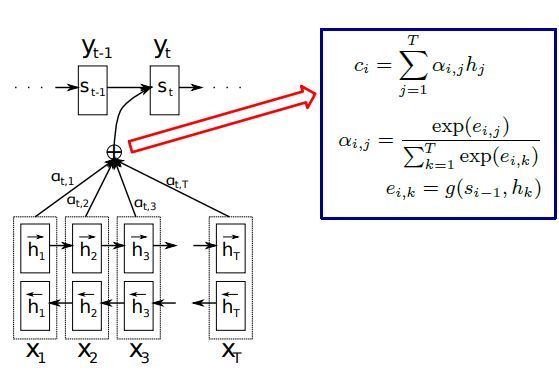
上述公式中的g实际上是一个前向的网络得到decoder每个隐藏层与输入序列中每个encoder隐藏层的相关,即attention分量,对encoder每时刻隐藏层的输出与当前时刻的attention的加权即得到文本向量(context vector)
进入正文,本文采用的encoder-decoder模型如下:
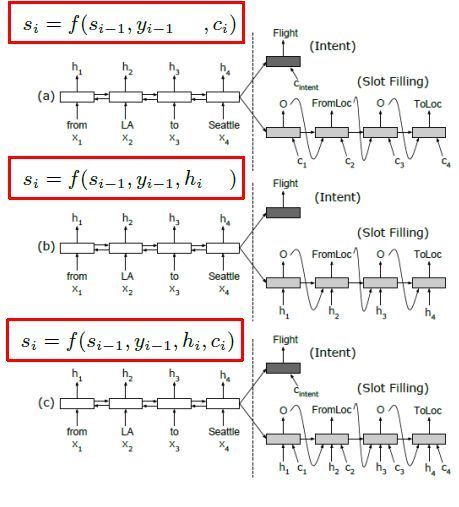
槽位
图a隐藏层非对齐attention的模型。decoder隐藏层非对齐的方式,decoder端的每个cell的输入为上一时刻隐藏层s,上一时刻标签的概率s与文本向量c的输入。
图b为隐藏层对齐无attention的模型,decoder端的每个cell的输入为上一时刻隐藏层s,上一时刻标签的概率s与对应的encoder的每个时刻隐藏层的输出。
图c隐藏层对齐attention的模型。decoder端的每个cell的输入为上一时刻隐藏层s,上一时刻标签的概率s,上一时刻标签的概率s与文本向量c的输入与对应的encoder的每个时刻隐藏层的输出。
意图
采用encoder的最后输出加入文本向量作为intent的分类。
该模型基于ATIS数据集(+aligned inputs):
Intent :94.14 Slot (F1):95.62
本文还基于上述的idea得到另外一种基于attention RNN的联合模型
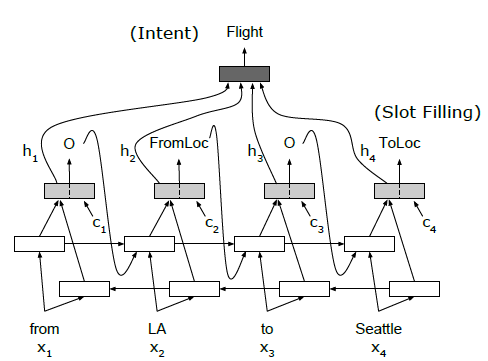
BiRNN 隐藏层的输入为
![]()
槽位
BiRNN得到的高维特征与文本向量concat起来作为单层decoderRNN的输入用于槽位识别,需要注意的是encoder的输出概率只作用于BiRNN的正向传输层。
意图
单层decoderRNN的隐藏层的输出的加权得到最后的输出向量,得到最后的意图分类
该模型基于ATIS数据集(+aligned inputs):
Intent :94.40 Slot (F1):95.78
6. 第六篇主要是在线意图与槽位,语言的联合模型(Online-RNN-LU)。上述四种联合模型之所以不是在线处理,主要一点是都是以整个句子为单位做解析,不能做到实时的解析。本文的亮点就是实时解析,对输入到当前为止的时刻T得到最优意图与槽位的解析以及一个词语的预测。
Liu B, Lane I. Joint online spoken language understanding and language modeling with recurrent neural networks[J]. 2016.
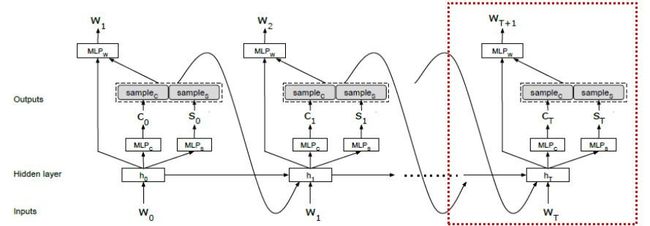
上图表示当前到时刻T的一个解析:
意图
w为T时刻前(包括T)的词语序列,c为T时刻前的意图,s为T时刻前的槽位序列,根据上述三者作为当前时刻T的RNN的输入,RNN隐藏层的输出,通过不同的MLP层分别作为当前时刻T意图与槽位的分类,同时该隐藏层的输出concat意图与槽位的信息输入MLP层得到下一个词的预测。
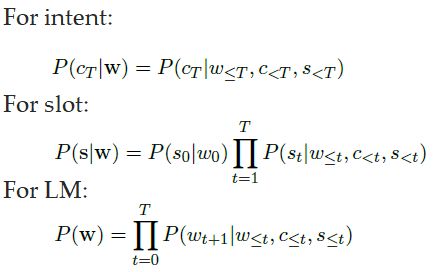
实际如下操作,采用LSTM,输入为上一时刻的词语序列,意图与槽位信息。其中公式中的IntentDist,SlotLabelDist,WordDist为MLP层。
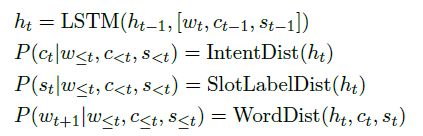
训练的方法即上述三个模块的极大似然
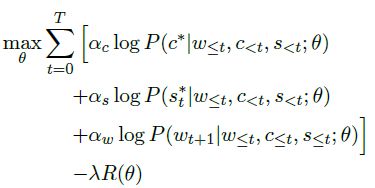
值的注意的是本文由于在线的算法,采用了greedy的思想,基于先前的意图与槽位达到当前的最优。