一纸读懂另类数据 | 未央研究
一纸读懂另类数据 | 未央研究
未央研究 清华大学五道口金融学院 今天
什么是另类数据?
1、定义
另类数据(Alternative Data)是不同于传统的交易所披露、公司公告披露的新数据,是有利于投资者进行投资决策的有价值信息。比如个人的消费信息,地区的天气状况,公司的销售记录等。
另类数据是典型的大数据(Big Data),Big代表其具有三个特性:
体量大(Volume):数据规模与传输量巨大。
流动速度大(Velocity):数据的获取和传输是实时(real-time)或者接近实时。
数据种类多(Variety):另类数据的形式很多样。数据或者已经存在自己的数据结构,或者是无数据结构。
2、分类
另类数据的来源与形式虽然多种多样,但是目前存在的另类数据可以分为三大类:
个人产生数据(Data generated by individuals):
社交网络信息,产品评价,搜索记录,购物喜好等。
商业过程数据(Data generated by business process):
商业运输,信用卡使用记录,订购,预定数据,购买数据等。
传感器数据(Data generated by sensors):
卫星数据,GPS定位数据,车辆轨迹,个人运动轨迹等。
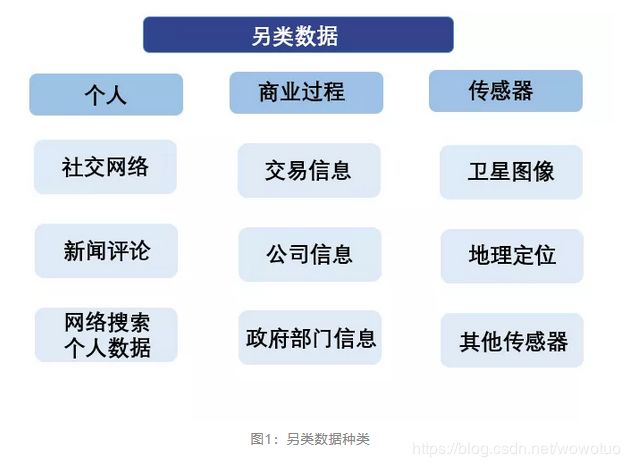
图1:另类数据种类
行业市场分析
1、良好的发展环境
为了寻找稳定,收益率高的投资策略,近年来,基金经理对于量化策略的认可程度逐年升高,而随着大数据运算的不断发展,通过获取,处理,分析另类数据获得信息,制定策略已经成了量化策略全新的方向。
另类数据的兴起,得益于当今时代良好的环境,总结来看有三点:
可获得数据数量的大幅度提升
近年来公开数据不断增加,人类收据数据能力显著提升,有估计显示目前人类社会90%的数据都来源于近2-3年,而且在未来,各类数据的数量还会不断增长。
计算机计算能力,储存能力的大幅度提升
随着云计算(Cloud Computing)的成熟与发展,再加上计算机性能的提升,人类已经能储存和传输巨大量的数据,预计在2020年之前,近1/3的数据将会储存或通过云进行传输。
机器学习算法处理另类数据能力的快速发展
机器学习是计算机科学与统计科学所形成的交叉学科,通过不断的进行训练(Function Approximation),机器学习可以分析和处理大量看似无意义甚至无关的数据,也就是我们常说的“另类数据”,通过分析数据得出有用的信息或结论。
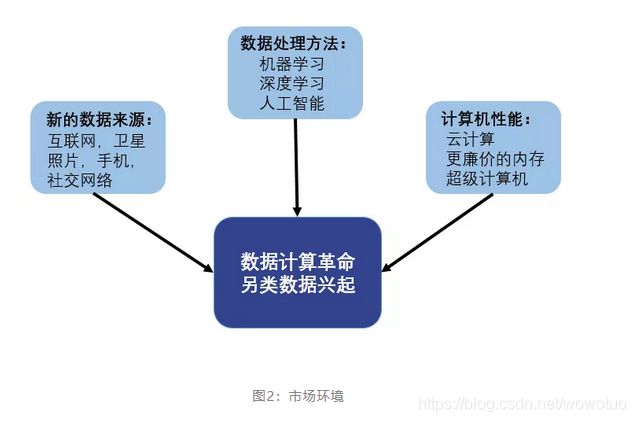
图2:市场环境
2、需求端
核心优势
由于良好的发展环境,另类数据掀起了一场数据革命。传统数据有着反应速度慢,批量处理难等问题,但另类数据中包含的信息不依赖于专业的数据网络与管理,并且能够实时获取处理,这是其相较于传统数据的最大优点,数据的时效性与准确性可以为量化投资者或基金经理带来高Sharpe的投资策略,同时也使得市场的反应更快,更有效。
在过去,投资者需要了解数据,需要找各种各样公司、找行业、专业的人士交流,然后综合得出结论。传统投资研究的弊端就体现在这里,数据的实时性无法得到保障,因为交流和联系不是天天都发生的,并且交流的对象也具有片面性,抽象来看,传统投资公司所得到的数据信息只是一个点上的片面信息。
但是如果利用“爬虫”的手段,通过数据清洗的方法,将数据结构化运用。通过日月积累的数据信息,可以准确了解公司的实际运营及业绩。这样获取的信息,全面,实时,客观,这也是股票投资基本面研究最需求的信息。
巨大的需求
随着数据技术的不断发展,越来越多的基金开始使用另类数据进行投资,这导致那些不使用另类数据的投资者更加倾向于进入这个全新的投资领域。从数据来看,买方机构对于另类数据的花费逐年升高,反映出另类数据市场的需求的旺盛。
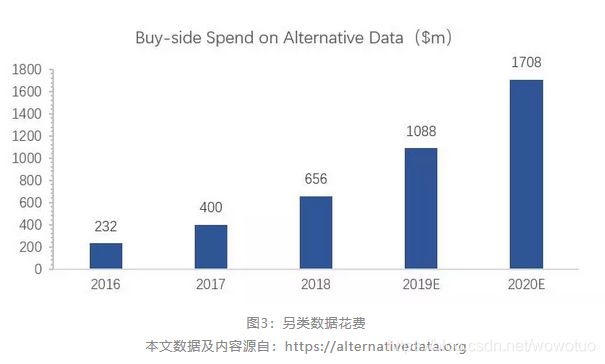
图3:另类数据花费
本文数据及内容源自:https://alternativedata.org
3、供给端
供给的不断增长
前文已经提到,随着大数据技术的不断发展,越来越多的人才与机构投入到数据科学的研究中,目前世界市场与另类数据相关的科技与分析机构价值在$130bn左右,而到2020年,这个数字将增长至$200bn。
近十年来,另类数据提供商(Provider)的数目从几乎没有,到现在的井喷式增加,这得益于完善的技术支持,良好的市场环境,并且在未来仍然会保持较快的增长速度。不仅如此,对于机构聘用从事另类数据分析的在职员工数目也不断上升。
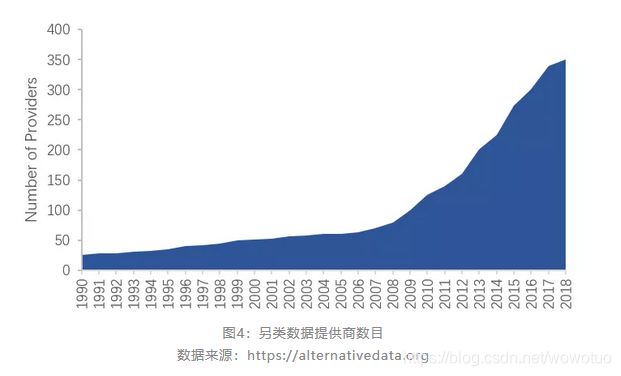
图4:另类数据提供商数目
数据来源:https://alternativedata.org
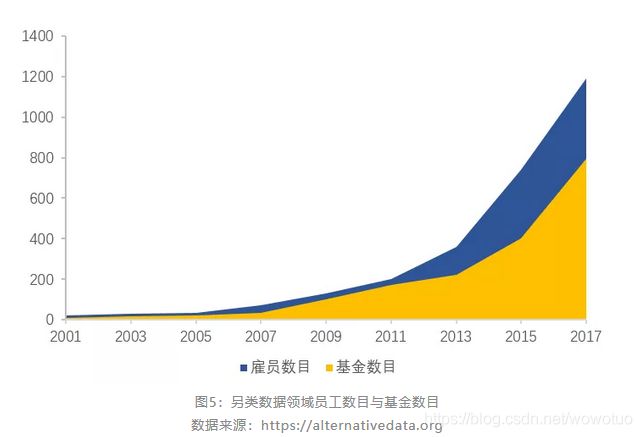
图5:另类数据领域员工数目与基金数目
数据来源:https://alternativedata.org
供给商的主要类型
目前市场上存在着大量的另类数据供给商,他们提供着不同种类的另类数据,我们无法根据种类对他们进行分类,但是可以根据对于出售数据的处理程度将他们大致分为三类:
原始数据提供者(Raw Data Provider):
这类供应商只收集最原始的另类数据,对于数据的处理程度最小。
轻处理数据提供者(Semi-Processed Data Provider):
这类供应商通过对地理区域、行业部门进行分类,将数据映射到特定部门,他们通常会制作数据文档,并提供一些与金融资产相关的可视化数据。
信号提供者(Signals and Reports Provider):
这类供应商一般关注于某个特定行业,通过收集行业另类数据,像行业研究者提供基础信息,或者向投资该行业的量化投资者提供打包好的量化投资信号。
这三类数据供应商面对不同需求的客户,通过不同的数据处理方式,持续将大量实时数据输送到市场中。
行业运营分析
1、另类数据利用的一般模式
虽然另类数据的种类多种多样,但是绝大多数投资者处理和利用数据的模式是相同的,其使用过程可以总结为下图:
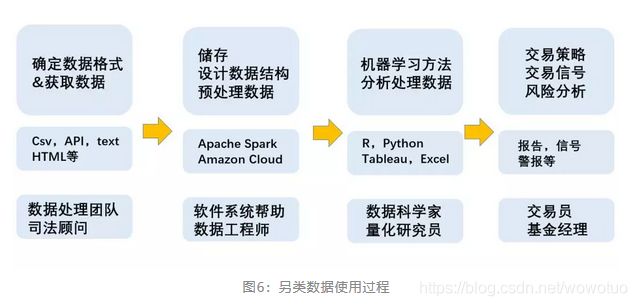
图6:另类数据使用过程
首先要确定需求数据的形式并且获取数据,之后进行数据结构的处理与整合,使数据符合分析标准,之后再利用机器学习及算法进行分析,最终转化为可用的信号或信息。任何一种另类数据的分析都要经过这样四个过程才能发挥价值。
2、数据中介(Data Intermedia)
随着另类数据市场的不断发展,该市场也发展出了较为完善的中介系统,数据市场的中介可以分为大致三类:
咨询中介(Consultants):这类中介为买方机构提供关于另类数据购买,处理,相关法律事宜的咨询,并且为买方机构提供数据供应商的信息,以及其所能提供数据的信息,典型的例子是Integrity Research。
数据收集中介(Data Aggregators):这类中介致力于收集大量数据提供者的数据,买方用户可以在数据中介挑选自己想要的数据种类,只需要和数据收集中介进行协商而不是在巨大的数据市场中挑选自己想要的数据,典型的例子是Eagle Alpha。
技术支持中介(Technology Solutions):这类中介为大数据需求者提供技术咨询,包括数据库的构建,量化因子的设计等,典型公司有IBM,SAP等。
数据中介作为连接数据买方和数据卖方的桥梁,使得不同程度处理的另类数据在市场流通,为不同的机构和个人服务。
3、数据价值
目前全世界有大概78%的基金组织使用了另类数据,其中使用频次最高的也是被认为准确度最高的是网页数据(Web Data)。
矿场,耕地的卫星图片可以在公开报道前反映一国生产规模的变化,成千上万物品的在线交易量可以即时的反应通胀程度,游客的数目可以带来实时的销售预测,所有的这些数据都可以被用来产生全新的投资策略,产生更加稳定的Alpha。
但是可以获取的数据并不是无穷无尽的,不同的数据有不同的有效时间,个体产生的数据通常通过网页爬虫获取,常有的来源有博客,视频资料等,这类数据的有效时间一般小于5年;商业过程产生的另类数据,最可靠的是信用类数据,如信用卡消费记录,公司消费记录等,这类数据的追溯时间可以达到近10-15年,有一些政府官方数据可以追溯至20年时间;最后一类,传感器产生的数据,使用最多的是手机,卫星,定位的数据,他们的有效期大约在3-4年左右。

图7:另类数据使用状况
数据来源:https://alternativedata.org
行业发展前景
另类数据对于投资市场的影响将是深远的。因为随着越来越多的投资者采用另类数据集,市场的反应将更加的迅速,这导致那些不使用另类数据的投资者无法跟上市场的脚步而逐渐被淘汰,另类数据与人工智能的结合可以越来越多地代替传统或“旧”数据源(如季度公司收益、低频宏观经济数据等),这为基金投资与量化投资都带来了优势。
对于管理者,他们愿意雇佣采用和学习另类数据集和方法的人。最终,“旧”数据集将失去最预测价值,利用“大数据”的新数据集将成为标准,J.P.Morgan在其报告中指出,机器学习技术将成为定量投资者和一些基础投资者的标准工具。系统性策略,如风险溢价、趋势追随、股票多头做空等,将越来越多地采用机器学习工具和方法。“大数据生态系统”包括专门收集、汇总和销售新数据集的公司,以及这两者的研究团队,而这一系统的不断完善与发展,也必将为另类数据的市场不断注入活力。
本文由未央研究团队根据https://alternativedata.org网站资料进行编译及解读。