Udacity机器学习入门笔记——2朴素贝叶斯-1
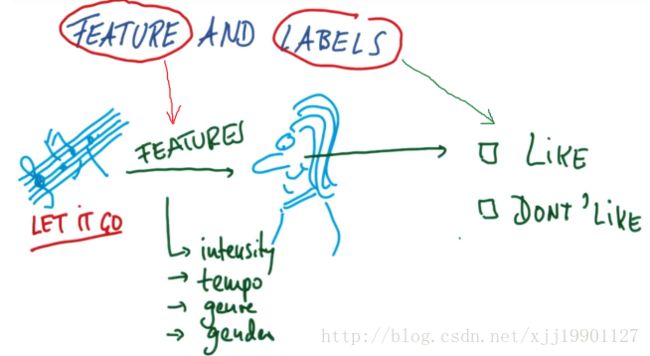
机器学习 一般会涉及到 特征(Features)和标签(Labels)
In machine learning we often take as inputfeatures and we try to produce labels. 在机器学习中我们通常会把特征作为输入,然后尝试生成标签。
机器学习分 有 监督学习(Supervised classification) 和 非监督学习(unsupervised classification)
监督学习(分类)
Supervised means that you have a bunch of examples, where you know sort of the correct answer in those examples.
“监督”表示你有很多不同情况的数据,并且你知道这些情况下的这些操作。---你有许多样本,且事先可以依据 样本特征进行 标签分类
无人驾驶汽车是一个重要的监督分类问题 ,Facebook 的照片识别、网站的推荐系统 也是
看看下面四个 哪个是监督学习范畴? 答案是1和3
- 拿一册带标签的照片,试着认出照片中的某个人
- 对银行数据进行分析,寻找异常的交易,将其标记为涉嫌欺诈
- 根据某人的音乐喜好以及其所爱音乐的特点,比如节奏或流派推荐一首他们可能会喜欢的歌
- 根据优达学城学生的学习风格,将其分成不同的组群
第2个中,可以认为正常和异常为两个标签,但是因为并没有给出异常交易的明确定义(特征和标签之间不能确认联系),因此无法依据样本进行 标签分类 不属于监督学习;当然可以利用非监督学习进行判断
第4个中,因为事先并没有给出 特定的类型(标签),没法事先知道学生属于哪种类型,所以也不是 监督学习;这属于聚类问题,属于非监督学习
机器进行监督学习的过程:以样本为基础进行训练,拟合特征与标签之间的关系,之后就可以进行预判
一般我们会 以特征为坐标轴,将所有的样本制成散点图,然后利用机器学习算法(依据 标签的区域划分特点 )定义一个决策面,之后就可以对新的例子进行预判 (根据特征预判标签)
Very often, instead of looking at the rawdate, we plot the data in a diagram.
往往 我们不去查看原始数据,而是把数据绘制成散点图再进行查看
What our machine learning algorithms do is,they define what’s called a decision suface(decision boundary决策边界、certain surface).
机器学习算法做的事情是:他们定义了一个所谓的决策面(简称DS)

决策面 分为线性决策面(linear)和非线性决策面,选择一个良好的线性决策面很重要

Naive Bayes 朴素贝叶斯 Avery common algorithm to find at a certain surface
朴素贝叶斯 是一个常见的寻找决策面的算法
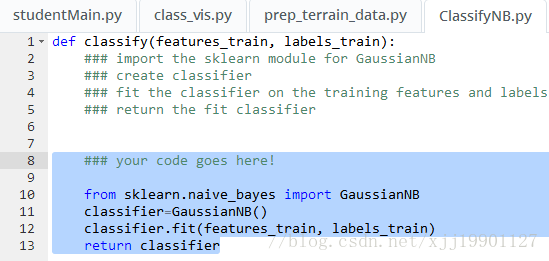
sk-learn是一个算法库(包),里面有许多算法(模块),比如朴素贝叶斯算法Naïve Bayes
GaussianNB(高斯朴素贝叶斯) 是朴素贝叶斯算法的一种(模块naïve_bayes里的一个类),GaussianNB类里面有可以用于 训练(fit)和预判(predict)的方法
GaussianNB介绍网页上的例子:利用朴素贝叶斯算法 进行监督分类的过程(训练过程)都是这样:调用fit函数,并给出一系列用于训练的特征X和标签Y(X,Y都是列表,一个特征元素是对应一个标签元素的)作为fit函数的两个参数
#生成一些可以利用的训练点(样本,X为特征列表,Y为标签列表,一对一)
>>> import numpy as np
>>> X = np.array([[-1, -1], [-2, -1], [-3, -2], [1, 1], [2, 1], [3, 2]])
>>> Y = np.array([1, 1, 1, 2, 2, 2])
#导入GaussianNB算法
>>> from sklearn.naive_bayes import GaussianNB
#创建分类器classifier (clf)
>>> clf = GaussianNB()
#fit替代了train,对样本的特征和标签进行拟合,就是训练过程;fit函数的两个参数传递给fit函数,一个是特征X 一个是标签Y
>>> clf.fit(X, Y)
GaussianNB(priors=None)
#最后我们让已经完成了训练的分类器进行一些预测,我们为它提供一个新点[-0.8,-1],这个特定点的标签是什么?它属于什么类?
>>> print(clf.predict([[-0.8, -1]]))
[1]
#标签只有 [1]和[2]两种类型练习 有关地形数据的GaussianNB 部署 使用给出的代码进行练习,目的是得到16小节中的结果。直接在网页上吧缺省的代码补齐,然后测试答案就可以了。

计算 GaussianNB 准确性
准确性不是指以此预判,而是将预判(多个)与真实结果进行对比,得到的正确率。以上个地形数据的GaussianNB 部署例子的分类器为例计算他的准确性。
sklearn库里有两个函数常用于计算准确性:
一个是 sklearn.naive_bayes模块里的类GaussianNB的函数GaussianNB().score(),因为之前一般都已经对类GaussianNB进行调用了from sklearn.naive_bayes import GaussianNB,所以类里面的实例方法可以直接使用;该函数需要features_test(测试特征)和labels_test(测试标签)两个参数,且直接能得到正确率accuracy = clf.score(features_test, labels_test)
一个是 sklearn.metrics模块的accuracy_score()函数:fromsklearn.metrics import accuracy_score;但是这个函数需要事先得到计算的预测值pred= clf.predict(features_test),然后以 pred 和 labels_test为参数进行操作对比得出正确率accuracy = accuracy_score(pred,labels_test)