mmdetection2.3.0版本安装过程,以及训练、测试、可视化等(亲测好用,很顺利)
mmdetection2.3.0版本安装过程,以及训练、测试、可视化等(亲测好用,很顺利)
文章目录:
- 1 运行mmdetection2.3.0版本报错
- 1.1 错误解决历程
- 1.2 最终的解决方法
- 2 mmdetection2.3.0 安装过程
- 2.1 创建虚拟环境
- 2.2 安装torch和torchvison
- 2.3 安装mmcv
- 2.4 下载mmdetection
- 2.5 安装编译mmdet
- 2.6 测试环境是否可用
- 2.7 单GPU训练
- 2.8 多GPU训练
- 2.9 再测试集上进行测试
- 2.10 可视化训练的loss结果
- 2.11 计算训练的时间
- 2.12 更改训练模型保存的周期 和 从预训练模型恢复训练
mmdetection 下载20200805最新的代码:
此时的最新代码版本为:mmdetection2.3.0
我尝试在我之前的环境中运行最新的mmdetection2.3.0版本,然后就报错呀,报错呀!
- 我之前mmdetection2.0.0版本——》在这里
mmdetection2.3.0版本比mmdetection2.0.0版本又多了一些模型,具体自己查看
1 运行mmdetection2.3.0版本报错
python tools/train.py -h
1.1 错误解决历程
报错·:ImportError: cannot import name 'get_git_hash' from 'mmcv.utils'
这是因为在mmcv==0.6.2中并没有这个函数,在最新版本的mmcv==1.0.5版本的anaconda3/envs/TensorRT/lib/python3.7/site-packages/mmcv/utils/version_utils.py中可以查看到有get_git_hash()函数

然后把mmcv版本更新到1.0.5版本,然后又报错:ModuleNotFoundError: No module named 'mmcv._ext',然后官网中是issues中提示:需要安装mmcv==0.6.2,啊啊啊啊啊!!!,这是死循环吗???

提示安装mmdet==2.2.1版本,如何安装指定版本的mmdet呢?
- 首先在:
mmdetection/mmdet/version.py中的__version__ =中的版本呢改为:__version__==2.2.1 - 然后再重新编译一遍:
pip install -v -e .
之后可以使用conda查看版本:
conda list mmdet
(TensorRT) shl@zfcv:~/project/mmdetection_0805$ conda list mmdet
# packages in environment at /home/shl/anaconda3/envs/TensorRT:
#
# Name Version Build Channel
mmdet 2.2.1 dev_0 <develop>
(TensorRT) shl@zfcv:~/project/mmdetection_0805$
然后查看官网的这个issues大概是25天前提交的,推测一下:mmcv-full的版本应该是1.0.2`

安装mmcv-full==1.0.2由于官网提供的这个库包是tar,gz格式,没有whl,这意味着这个库包是没有编译的,需要自己下载之后编译:
1、下载mmcv-full==1.0.2的tar.gz库包文件
wget https://files.pythonhosted.org/packages/af/ac/72d570062951e090139a790acfaca495d655f24f008c8ae0c2140cff0eb9/mmcv-full-1.0.2.tar.gz
2、解压
tar zxvf mmcv-full-1.0.2.tar.gz
3、编译,编译的时间稍微有一点久
cd mmcv-full-1.0.2
python setup.py build
4、编译完之后安装
python setup install
5、查看mmcv-full是否安装成功
(TensorRT) shl@zfcv:~/project/mmdetection_0805$ conda list mmcv
# packages in environment at /home/shl/anaconda3/envs/TensorRT:
#
# Name Version Build Channel
mmcv 0.6.2 pypi_0 pypi
mmcv-full 1.0.2 pypi_0 pypi
(TensorRT) shl@zfcv:~/project/mmdetection_0805$
然后执行继续执行:python tools/train.py -h,然后你懂的又报错:ImportError: cannot import name 'get_git_hash' from 'mmcv.utils',哈哈哈哈哈哈...,又回到了这里

这种方法没有解决我的问题,然后有isuess说可是使用torch==1.4.0版本,然后我去官网的仓库看了下,对于cuda10.2目前只支持torch1.5.0及以上版本,我TMD感动的泪水要化成河流啦!

然后还是乖乖去官网看官网对最新版本的mmdetection的安装教程吧,毕竟有些错误经验跟不上官网的更新速度!

截至:20200805 mmdetection/mmdet/version.py中定义的mmdet==2.3.0版本,因此下载最新的版本的代码就必须安装mmcv-full>=1.0.5版本,而截至20200805最新版本的mmcv-full=1.0.5(这个版本是20200803上传的)
告诉我们一个道理:
第一个吃螃蟹的人,必须要付出代价!!!
1.2 最终的解决方法
2 mmdetection2.3.0 安装过程
首先列举下官网对安装环境的要求:
- Linux or macOS (Windows is not currently officially supported)
- Python 3.6+
- PyTorch 1.3+
- CUDA 9.2+ (If you build PyTorch from source, CUDA 9.0 is also compatible)
- GCC 5+
- mmcv
下面是我实际环境安装过程:
2.1 创建虚拟环境
conda create -n mm0805 python=3.7
2.2 安装torch和torchvison
pip intall torch==1.5.0 torchvision==0.6.0
2.3 安装mmcv
pip install mmcv-full==latest+torch1.5.0+cu101 -f https://openmmlab.oss-accelerate.aliyuncs.com/mmcv/dist/index.html
2.4 下载mmdetection
git clone https://github.com.cnpmjs.org/open-mmlab/mmdetection.git
2.5 安装编译mmdet
cd mmdetection
pip install -r requirements/build.txt
pip install -v -e . # or "python setup.py develop"
2.6 测试环境是否可用
python tools/train.py -h.
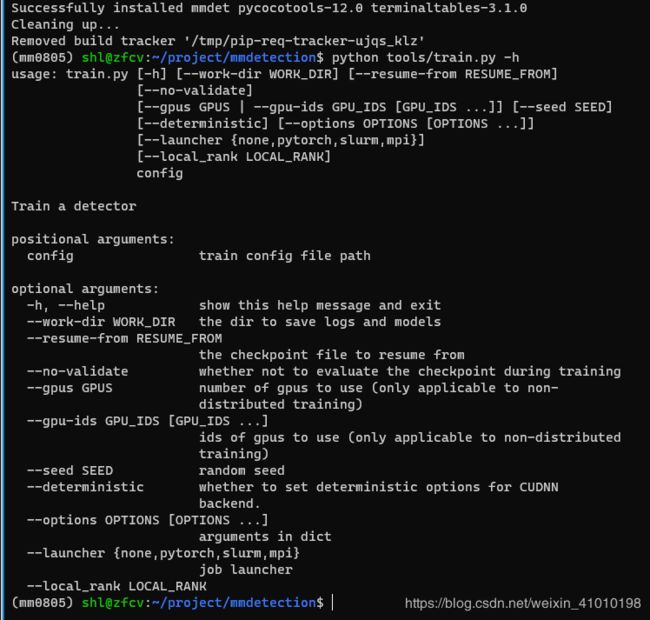
2.7 单GPU训练
python tools/train.py ./configs/gfl/gfl_r50_fpn_mstrain_2x_coco.py --work-dir 1_work_dirs_gfl_hat_hair_beard --gpu-ids 1
2.8 多GPU训练
./tools/dist_train.sh ./configs/gfl/gfl_r50_fpn_mstrain_2x_coco.py 3 --work-dir 1_work_dir_gfl_hat_hair_beard
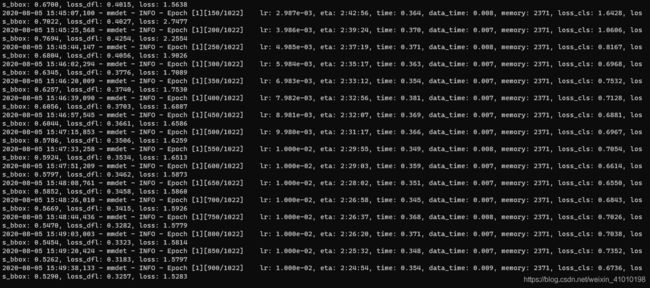
训练结束的结果:
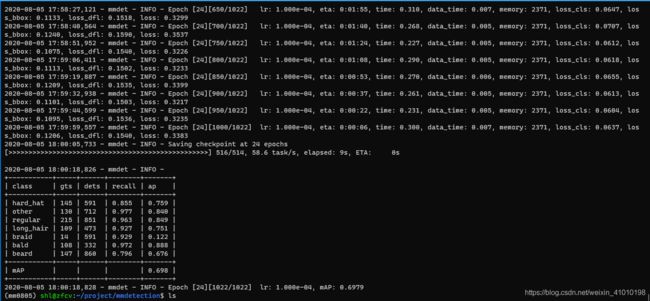
从训练损失可以看,还可以继续下降,可以增大epoch训练的轮数,在下面的配置文件中修改:total_epochs
./configs/gfl/gfl_r50_fpn_mstrain_2x_coco.py
# learning policy
lr_config = dict(step=[16, 22])
total_epochs = 60 # 默认值为24
# multi-scale training
img_norm_cfg = dict(
mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
train_pipeline = [
dict(type='LoadImageFromFile'),
dict(type='LoadAnnotations', with_bbox=True),
dict(
type='Resize',
img_scale=[(1333, 480), (1333, 800)],
multiscale_mode='range',
keep_ratio=True),
dict(type='RandomFlip', flip_ratio=0.5),
dict(type='Normalize', **img_norm_cfg),
dict(type='Pad', size_divisor=32),
dict(type='DefaultFormatBundle'),
dict(type='Collect', keys=['img', 'gt_bboxes', 'gt_labels']),
]
data = dict(train=dict(pipeline=train_pipeline))
2.9 再测试集上进行测试
2.10 可视化训练的loss结果
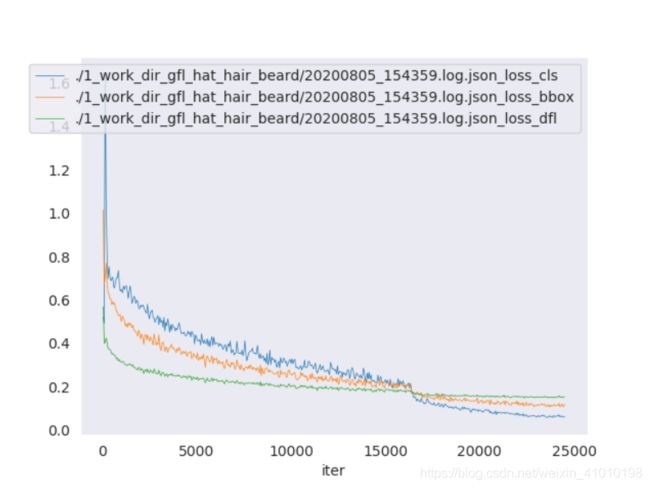
1、可视化命令:
python tools/analyze_logs.py plot_curve ./1_work_dir_gfl_hat_hair_beard/20200805_154359.log.json --keys loss_cls loss_ bbox loss_dfl --out ./plot_result/1_gfl_hat_hair_beard

2、可视化命令参数介绍:
plot_curve:该参数后跟的是训练保存的json文件--keys:后面跟的是要绘制的损失关键字,可以跟多个值--out:后面跟的是绘制保存的结果,可以保存成png图片,也可以保存成pdf
3、绘图的结果:
2.11 计算训练的时间
计算训练时间的命令:
python tools/analyze_logs.py cal_train_time ./1_work_dir_gfl_hat_hair_beard/20200805_154359.log.json

2.12 更改训练模型保存的周期 和 从预训练模型恢复训练
默认是每训练一个epoch保存一次模型,如果要更改,需要在:
mmdetection/configs/_base_/default_runtime.py
# 默认是每隔一轮保存一次训练模型,这里我们改成每隔5轮保存一次
checkpoint_config = dict(interval=5)
# yapf:disable
log_config = dict(
interval=50,
hooks=[
dict(type='TextLoggerHook'),
# dict(type='TensorboardLoggerHook')
])
# yapf:enable
dist_params = dict(backend='nccl')
log_level = 'INFO'
load_from = None
resume_from = None
workflow = [('train', 1)]


♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠