拉勾网的职位信息爬取(详细)
1.进入拉钩网,(调到注册页可删掉url详情后缀直接登陆主页)

2.选定一个城市一种职位,分析一下页面,发现点击第一页第二页换页时url地址栏并未发生变化,可以判断是ajax发送的请求,且显示是post请求
拿到实际的请求地址,并构造查询字符串和请求体内容
-
https://www.lagou.com/jobs/positionAjax.json?gj=3%E5%B9%B4%E5%8F%8A%E4%BB%A5%E4%B8%8B&px=default&city=%E6%B7%B1%E5%9C%B3&needAddtionalResult=false
-
first: true
pn: 1 # 页码
kd: 深圳python #自己所输入的查询关键字
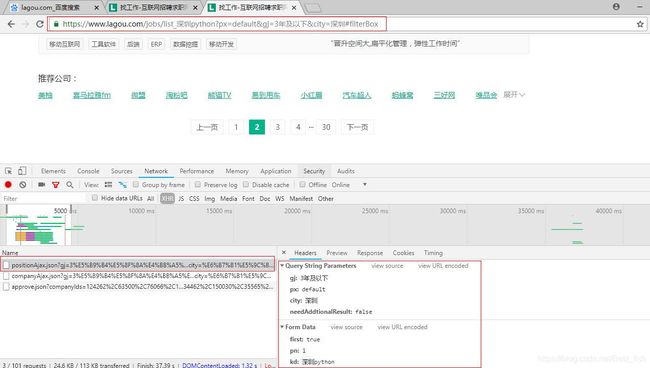
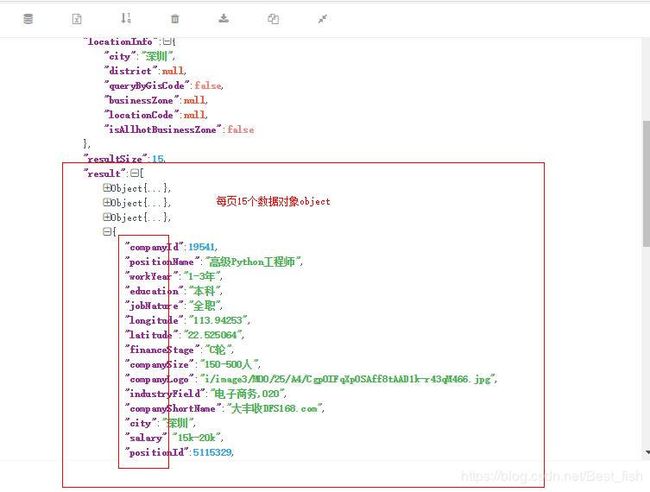
3.看了下页面,每页是15个招聘信息,将响应的Response内容粘贴到json解析器里查看了json的结构,确定要提取的内容

4.提取的内容:
result_list = jsonpath(json_obj, "$..result")[0] # 要加[0]取到数据列表
"""jsonpath取到的任何数据它都会自己在外面加一层[]变为一个列表,
所以实际取到的数据是[ [object{},object{},...,object{}] ]
"""
5.爬虫代码
#coding:utf-8
import requests
import json
from jsonpath import jsonpath
class LagouSpider:
def __init__(self):
self.headers = {
"Accept": "application/json, text/javascript, */*; q=0.01",
"Accept-Encoding": "gzip, deflate, br",
"Accept-Language": "zh-CN,zh;q=0.9,en;q=0.8",
"Connection": "keep-alive",
"Content-Length": "25",
"Content-Type": "application/x-www-form-urlencoded; charset=UTF-8",
"Cookie": "user_trace_token=20170923184359-1ba5fe6f-a04c-11e7-a60e-525400f775ce; LGUID=20170923184359-1ba6010d-a04c-11e7-a60e-525400f775ce; _ga=GA1.2.136733168.1506163440; JSESSIONID=ABAAABAAAFCAAEGB705AF5022E928409CB59D368BF6245A; _gid=GA1.2.1817431977.1542253084; Hm_lvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1542253085; LGSID=20181115113805-dc74fe6d-e887-11e8-88bd-5254005c3644; PRE_UTM=; PRE_HOST=; PRE_SITE=; PRE_LAND=https%3A%2F%2Fwww.lagou.com%2F; index_location_city=%E6%B7%B1%E5%9C%B3; TG-TRACK-CODE=index_search; _gat=1; LGRID=20181115114649-14fd6b22-e889-11e8-9ef4-525400f775ce; Hm_lpvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1542253610; SEARCH_ID=f18b4e7b272c464b9f853e717d1e496d",
"Host": "www.lagou.com",
"Origin": "https://www.lagou.com",
# headers里必须携带referer来源信息
"Referer": "https://www.lagou.com/jobs/list_python?px=default&gj=3%E5%B9%B4%E5%8F%8A%E4%BB%A5%E4%B8%8B&xl=%E6%9C%AC%E7%A7%91&hy=%E7%A7%BB%E5%8A%A8%E4%BA%92%E8%81%94%E7%BD%91&city=%E6%B7%B1%E5%9C%B3",
# headers里必须协带的代理信息(headers可只包含Referer和User-Agent信息)
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36",
"X-Anit-Forge-Code": "0",
"X-Anit-Forge-Token": "None",
"X-Requested-With": "XMLHttpRequest"
}
self.post_url = "https://www.lagou.com/jobs/positionAjax.json?"
self.query_str = {
"city": raw_input("请输入城市名"), # 要查询哪个城市的职位
"needAddtionalResult": "false" # 请求url末尾的字符串信息
}
self.page = 0 # 从第一页开始
self.form_data = {
"first": "false",
"pn": self.page,
"kd": raw_input("职位") # 要查询的工作岗位
}
self.item_list = [] # 用于存放爬去信息的列表
def send_request(self, url):
print("[INFO]:发送并获取{}".format(url))
response = requests.post(url, params=self.query_str, data=self.form_data, headers=self.headers)
return response
def parse_page(self, response):
python_obj = response.json() # etree/Beautifulsoup/json 等多种提取方式
# jsonpath取到的数据都是列表所以取到的是这样的结构[[{},{},{}]]
result_list = jsonpath(python_obj, "$..result")[0]
# 到最后一页之后,设置标志位,终止循环
if not result_list:
return True
# 处理提取到的数据 提取需要的字段
for result in result_list:
item = {}
item["city"] = result["city"]
item["district"] = result["district"]
item["companyShortName"] = result["companyShortName"]
item["education"] = result["education"]
item["salary"] = result["salary"]
item["createTime"] = result["createTime"]
self.item_list.append(item)
def save_data(self):
json.dump(self.item_list, open("lagou.json", "w"))
def main(self):
# while True:
while self.page <= 1:
response = self.send_request(self.post_url)
if self.parse_page(response) == True:
break
self.page += 1
self.save_data()
if __name__ == '__main__':
spider = LagouSpider()
spider.main()
6.爬取到的数据

7.将爬到的json数据保存为csv格式
- csv格式的文件和excel有点类似,第一行是表头,随便拿到一个数据取到keys即可用作表头
- json转csv脚本,遍历values,用csv对象将其一行一行写入文件(json文件路径要正确):
#!/usr/bin/env python
# -*- coding:utf-8 -*-
"""各编码之间转换可能会出现bug,统一一下编码"""
import sys
reload(sys)
sys.setdefaultencoding("utf-8")
import json
import csv
def json_to_csv():
json_file = open("lagou.json", "r")
csv_file = open("lagou.csv", "w")
item_list = json.load(json_file)
sheet_data = item_list[0].keys()
value_data = [item.values() for item in item_list]
csv_writer = csv.writer(csv_file)
csv_writer.writerow(sheet_data)
csv_writer.writerows(value_data)
csv_file.close()
json_file.close()
if __name__ == "__main__":
json_to_csv()
8.爬取结果
