webMagic爬取网易云音乐评论
前期准备:
在前几篇文章中给大家介绍了如何去使用springboot,但是光说还不行,我们得在实际项目中去使用,加深自己对springboot的印象。
我自己选择的一个项目就是利用爬虫爬取网易云音乐的热评(自己很喜欢每首歌后面的评论)。那么首先第一步我们必须明白什么是爬虫。所谓爬虫就是大量获取网页上的数据,利用模拟http请求,分析返回的数据的一个过程。
第二步我们采用什么方式去做爬虫。之前纠结了很久,因为做爬虫这一块的话,网上都推荐使用python来爬,但是我对python不是很熟悉,所以就采用java来做爬虫。(写到最后我才发现,本文侧重点不是在于springboot,而在于怎么去爬取网易云音乐的评论-.-,跟我一开始做这个项目的初衷不太一样,有点尴尬,但总算学到点东西)
框架的选择:
这里使用的java语言,所以对应的爬虫框架也要是java的。我在github上找了下java版的爬虫,最终选择了webMagic这款爬虫框架。
框架优点:
1. 文档中文,使用起来很方便。
2. github上也有7k的star,说明口碑还不错。
附上git地址:https://github.com/code4craft/webmagic
项目整体是采用springboot +mybatis+ redis(作分布式爬虫的数据存储)。
项目的搭建:
- 在springboot中导入webmagic的依赖。github都有说明,不会的可以去看看。
- 在springboot中导入日志包,数据库依赖。附上pom.xml,见文章末尾
编写代码:
在开始爬取数据之前,我们得思考一下怎么去爬?首先我们得先明确一点,目标网页是静态页面还是动态页面,如果是静态页面,那么很简单,只需要根据返回的http内容就可以抓到我们想要的数据,但如果是动态加载的页面,我们必须要拿到ajax返回的数据,对ajax返回的数据进行分析。举个例子,网易歌手页面地址:https://music.163.com/discover/artist。
按F12查看 network,可以看到各种请求返回的内容,点击 artist,查看网络请求内容:
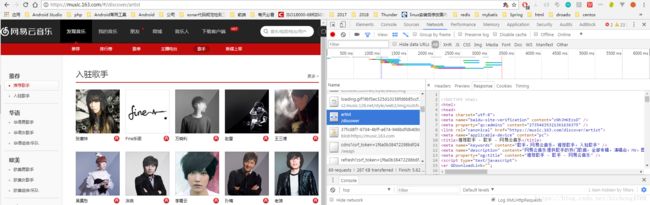
这里我们可以看到歌手页面地址返回的内容是一个html,这应该就是一个静态页面,如果你还不放心的话,可以查找一下关键字,比如 张惠妹
![]()
我们可以在html中看到有内容呈现,可以判断,网易歌手页面是一个静态页面。
爬取流程:
我们最终的目标是评论也就是:https://music.163.com/song?id=326904。利用这个目标反推一下,我们需要什么?
从这个url我们可以看出需要歌曲的id,也就是326904。歌曲id 从专辑页面来,专辑从歌手来。由此,我们可以整理下爬虫的顺序。
1. 初始页面:https://music.163.com/discover/artist 歌手列表,获取歌手id。
2. 歌手专辑页面:https://music.163.com/artist/album?id=6452 歌手专辑页面。获取歌手某一个专辑的id。
3. 歌曲页面:https://music.163.com/album?id=37251353 根据专辑名称获取该专辑下的所有歌曲id。
4. 最终目标页面:https://music.163.com/song?id=531051217 获取评论信息。
歌手->专辑->歌曲->评论。
歌手页面:
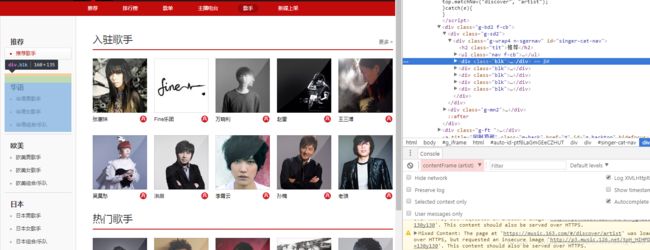
歌手页面将歌手分为华语、欧美、日本、韩国等,所以我们还需要进入到对应的分组查询歌手。随便选择一个分组进入:

注意我标注的三个地方:华语男歌手地址是https://music.163.com/#/discover/artist/cat?id=1001,这个id就是华语男歌手的id。但是在华语男歌手大组下面,还根据姓氏首字母拼音又进行了分组,检查元素,我们可以看到:

也就是在地址后面加了个initial参数,到这里其实已经结束了,这里首字母相当于分页的功能。
歌手显示页面找打了, 那么我们如何找到歌手的id呢,审查元素,我们可以看到

看到没有 歌手id就在a标签的href属性里面。所以,我们代码需要做的事情就是如何将a标签中href的属性取出来。
这里,我建议使用 xpath来抽取元素。有关xpath的介绍请点击http://www.w3school.com.cn/xpath/xpath_syntax.asp。
附上爬取歌手信息的代码:
/**
* 抓取的歌手分组(日本歌手、欧美歌手、韩国歌手、其他)
*/
private static final String URL_LIST = "https://music\\.163\\.com/discover/artist$";
/**
* 某一个歌手分组的所有歌手 id 歌手分组
*/
private static final String SINGER_LIST = "https://music\\.163\\.com/discover/artist/cat\\?id=\\d+";
/**
* 某一个歌手分组的所有歌手 initial 歌手姓名ABCDEFG
*/
private static final String SINGER_NAME_LIST = "https://music\\.163\\.com/discover/artist/cat\\?id=\\d+\\&initial=\\d+";
@Override
public void process(Page page) {
//初始页面
if (page.getUrl().regex(URL_LIST).match()) {
List groupHref = page.getHtml().xpath("//div[@class ='blk']//li/a[@class='cat-flag']/@href").all();
page.addTargetRequests(groupHref);
return;
}
//分组后页面
else if (page.getUrl().regex(SINGER_LIST).match()) {
List surNameList = page.getHtml().xpath("//ul[@id='initial-selector']/li/a/@href").all();
page.addTargetRequests(surNameList.subList(1, surNameList.size()));
return;
}
//首字母分页后页面
else if (page.getUrl().regex(SINGER_NAME_LIST).match()) {
List singerListHref = page.getHtml().xpath("//div[@class='m-sgerlist']/ul[@id='m-artist-box']/li[@class='sml']/a/@href").all();
List singerListIamgeHref = page.getHtml().xpath("//div[@class='m-sgerlist']/ul[@id='m-artist-box']/li/p/a/@href").all();
singerListHref.addAll(singerListIamgeHref);
for (String singerHref : singerListHref) {
Matcher matcher = compile.matcher(singerHref);
if (matcher.find()) {
String singerId = matcher.group(1);
page.addTargetRequest("https://music.163.com/artist/album?id=" + singerId);
}
}
return;
}
} 重点就在对元素的提取这一部分,也就是xpath的使用其他没啥。
专辑页面:
歌手个人所有专辑地址:https://music.163.com/#/artist/album?id=6452
在获取歌手页面后,我们将歌手id 和地址拼接,形成需要访问的歌手专辑页面(专辑页面也是静态的~~~很皮)

相同的道理,我们审查元素,发现专辑id在p元素的a标签中的href属性。这里同样有分页,需要注意下分页的元素

选取时,需要过滤一些无用的链接。比如这里 上一页和当前页是不需要加入到爬取url队列中。
附上代码
List albumList = page.getHtml().xpath("//ul[@id='m-song-module']/li//p/a/@href").all();
if (albumList.size() < 0) {
return;
}
//分页数据
List albumListNext = page.getHtml().xpath("//div[@class='u-page']/a[@class='zpgi']/@href").all();
if (albumListNext.size() > 1) {
page.addTargetRequests(albumListNext.subList(1, albumListNext.size()));
} else {
page.addTargetRequests(albumListNext);
}
page.addTargetRequests(albumList); 歌曲页面:
歌曲地址:https://music.163.com/#/album?id=18877
注意:有些时候页面直接审查元素位置不一定就是爬虫爬取的位置,所以我建议直接F12中neiwork中的请求去对元素进行定位操作。
附上代码:
List singList = page.getHtml().xpath("//div[@id='song-list-pre-cache']//ul[@class='f-hide']/li/a/@href").all();
page.addTargetRequests(singList); 歌曲详情页面:
前面一系类的操作,都是为了最终获取歌曲id,通过歌曲id来获取评论。最后一步显得格外重要。
爬取地址:https://music.163.com/#/song?id=185694。
常规操作之后,死活获取不到想要的评论。当时的我心情是这样的

are you kidding me??????
后来发现,这是个动态页面。而且找这个请求还特么找半天,是真的惨。
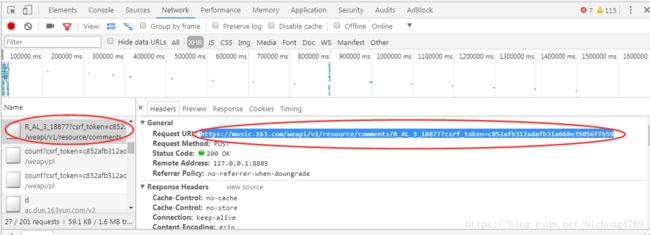
这是一个获取评论的接口,他返回的数据是一个json,这是一个post请求,请求内容类型是:application/x-www-form-urlencoded,请求参数是2个参数params和encSecKey。

经过分析之后,我们发现只需要构造出2个参数的值就能获取评论内容了,这2个值明显是经过js加密的,那么如何构建呢?关于这个两个参数如何加密?大家可以查看我的下一篇博客:https://blog.csdn.net/bicheng4769(如何获取到偏移量、密钥)
我这里就简单跟大家说一下:这里加密采用了AES加密算法和RSA加密算法。唯一的问题是:我需要用java去实现这个加密算法,还好java都有内置的加密算法,所以这里只需要熟悉加密算法的几种模式就好。附上AES加密工具类代码:
public class MusicEncrypt {
/***
* 密钥
*/
private static String sKey = "0CoJUm6Qyw8W8jud";
/**
* 偏移量
*/
private static String ivParameter = "0102030405060708";
private static String context = "{rid: \"R_SO_4_25641368\",offset: \"0\",total: \"true\",limit: \"20\",csrf_token: \"\"}";
/**
* aes加密
* @param content 加密内容
* @param sKey 偏移量
* @return
*/
public static String AESEncrypt(String content,String sKey) {
try {
byte[] encryptedBytes;
byte[] byteContent = content.getBytes("UTF-8");
Cipher cipher = Cipher.getInstance("AES/CBC/PKCS5Padding");
SecretKeySpec secretKeySpec = new SecretKeySpec(sKey.getBytes(), "AES");
IvParameterSpec iv = new IvParameterSpec(ivParameter.getBytes());
cipher.init(Cipher.ENCRYPT_MODE, secretKeySpec, iv);
encryptedBytes = cipher.doFinal(byteContent);
return new String(Base64Utils.encode(encryptedBytes), "UTF-8");
} catch (NoSuchAlgorithmException e) {
e.printStackTrace();
} catch (NoSuchPaddingException e) {
e.printStackTrace();
} catch (InvalidKeyException e) {
e.printStackTrace();
} catch (InvalidAlgorithmParameterException e) {
e.printStackTrace();
} catch (BadPaddingException e) {
e.printStackTrace();
} catch (IllegalBlockSizeException e) {
e.printStackTrace();
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
}
return null;
}
public static String rsaEncrypt() {
String secKey = "257348aecb5e556c066de214e531faadd1c55d814f9be95fd06d6bff9f4c7a41f831f6394d5a3fd2e3881736d94a02ca919d952872e7d0a50ebfa1769a7a62d512f5f1ca21aec60bc3819a9c3ffca5eca9a0dba6d6f7249b06f5965ecfff3695b54e1c28f3f624750ed39e7de08fc8493242e26dbc4484a01c76f739e135637c";
return secKey;
}
}爬虫页面:
/**
* 歌曲地址 id 歌曲id
*/
private static final String SONGNADDRESS = "https://music\\.163\\.com/song\\?id=(\\d+)";
/**
* 获取评论地址
*/
private static final String COMMENT = "https://music\\.163\\.com/weapi/v1/resource/comments/*+";
if (page.getUrl().regex(SONGNADDRESS).match()) {
String songName = page.getHtml().xpath("//div[@class='tit']/em[@class='f-ff2']/text()").toString();
String singerName = page.getHtml().xpath("//p[@class='des s-fc4']/span/a/text()").toString();
String ablumName = page.getHtml().xpath("//p[@class='des s-fc4']/a/text()").toString();
Matcher matcher = compileSong.matcher(page.getUrl().toString());
if (matcher.find()) {
//构造请求
Request request = new Request("https://music.163.com/weapi/v1/resource/comments/R_SO_4_" + songId + "?csrf_token=");
request.setMethod("post");
request.setRequestBody(HttpRequestBody.form(makePostParam(songId, "true", 1), "UTF-8"));
page.addTargetRequest(request);
}
return;
} else if (page.getUrl().regex(COMMENT).match()) {
Matcher matcher = songId.matcher(page.getUrl().toString());
if (matcher.find()) {
String songId = matcher.group(1);
List contentList = new JsonPathSelector("$.hotComments.[*].content").selectList(page.getRawText());
List likeCountList = new JsonPathSelector("$.hotComments.[*].likedCount").selectList(page.getRawText());
List nicknameList = new JsonPathSelector("$.hotComments.[*].user.nickname").selectList(page.getRawText());
List timeList = new JsonPathSelector("$.hotComments.[*].time").selectList(page.getRawText());
String stringTotal = new JsonPathSelector("$.total").select(page.getRawText());
}
return;
}
/**
* 获取评论的2个参数设置
*
* @param content
* @return
*/
public Map makePostParam(String content) {
Map map = new HashMap<>();
map.put("params", MusicEncrypt.AESEncrypt((MusicEncrypt.AESEncrypt(content, sKey)), "FFFFFFFFFFFFFFFF"));
map.put("encSecKey", MusicEncrypt.rsaEncrypt());
return map;
}
public Map makePostParam(String songId, String paging, int nowPageNum) {
return makePostParam(makeContent(songId, paging, nowPageNum));
}
/**
* @param songId 歌曲ID
* @param paging 是否第一页 true 第一页 其余传入false
* @param nowPageNum 当前页数
* @return
*/
public static String makeContent(String songId, String paging, int nowPageNum) {
int offset;
if (nowPageNum < 1) {
offset = 20;
}
offset = (nowPageNum - 1) * 20;
String baseContent = "{rid: \"R_SO_4_%s\",offset: \"%d\",total: \"%s\",limit: \"20\",csrf_token: \"\"}";
return String.format(baseContent, songId, offset, paging);
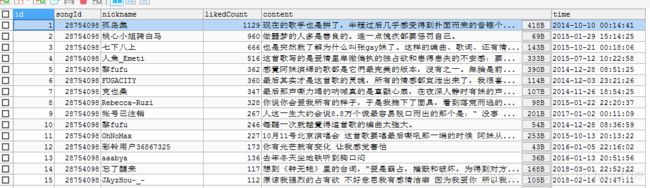
} 至此 终于爬到了歌曲的评论。附结果:
总结语:
爬虫最重要的就是选择器,也就是你能从一大堆的html中提取出自己想要的东西,复杂一点的比如网易云评论,做了反爬虫处理,所以我们需要构建出对应的参数,才能获取到想要的信息。而关于爬取网易云音乐的过程中,最重要的就是构建params和encSecKey。最终通过加密后的参数进行post请求,对返回的json进行分析。
附github地址:https://github.com/woaicaojing0/spiderMusic(如果觉得还ok,请给个star)
附 pom.xml
<dependencies>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starterartifactId>
<exclusions>
<exclusion>
<groupId>ch.qos.logbackgroupId>
<artifactId>logback-classicartifactId>
exclusion>
exclusions>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-testartifactId>
<scope>testscope>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-webartifactId>
dependency>
<dependency>
<groupId>us.codecraftgroupId>
<artifactId>webmagic-coreartifactId>
<version>0.7.3version>
<exclusions>
<exclusion>
<groupId>org.slf4jgroupId>
<artifactId>slf4j-log4j12artifactId>
exclusion>
exclusions>
dependency>
<dependency>
<groupId>us.codecraftgroupId>
<artifactId>webmagic-extensionartifactId>
<version>0.7.3version>
<exclusions>
<exclusion>
<groupId>org.slf4jgroupId>
<artifactId>slf4j-log4j12artifactId>
exclusion>
exclusions>
dependency>
<dependency>
<groupId>org.apache.logging.log4jgroupId>
<artifactId>log4j-coreartifactId>
<version>2.7version>
dependency>
<dependency>
<groupId>org.apache.logging.log4jgroupId>
<artifactId>log4j-apiartifactId>
<version>2.7version>
dependency>
<dependency>
<groupId>org.apache.logging.log4jgroupId>
<artifactId>log4j-slf4j-implartifactId>
<version>2.7version>
dependency>
<dependency>
<groupId>org.mybatis.spring.bootgroupId>
<artifactId>mybatis-spring-boot-starterartifactId>
<version>1.3.1version>
dependency>
<dependency>
<groupId> mysqlgroupId>
<artifactId> mysql-connector-javaartifactId>
<version>5.1.42version>
dependency>
<dependency>
<groupId>com.squareup.okhttp3groupId>
<artifactId>okhttpartifactId>
<version>3.7.0version>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-data-redisartifactId>
dependency>
<dependency>
<groupId>org.apache.commonsgroupId>
<artifactId>commons-lang3artifactId>
<version>3.4version>
dependency>
dependencies>