1 下载
wget https://github.com/prometheus/alertmanager/releases/download/v0.18.0/alertmanager-0.18.0.linux-amd64.tar.gz -P /usr/local/2 安装
tar xf alertmanager-0.18.0.linux-amd64.tar.gz
mv alertmanager-0.18.0.linux-amd64 alertmanager3 配置为系统服务
cat>/lib/systemd/system/alertmanager.service<4 自定义yml文件配置告警方式
[root@node1 alertmanager]# cat alertmanager.yml
global:
resolve_timeout: 5m
smtp_smarthost: 'smtp.163.com:25'
smtp_from: '[email protected]'
smtp_auth_username: '[email protected]'
smtp_auth_password: 'xxxxxx'
smtp_require_tls: false
route:
receiver: 'mail'
receivers:
- name: 'mail'
email_configs:
- to: '[email protected]'
alertmanager 也是服务可以通过下面方式访问
http://IP:90935 设置prometheus开启alertmanager
vim prometheus.yml
alerting:
alertmanagers:
- static_configs:
- targets:
- localhost:9093
这里完全是localhost ,因为alertmanager也是个服务器可以安装到任何节点,所以只需要根据实际情况做配置即可
systemctl restart prometheus6 添加告警规则
cd /usr/local/prometheus
mkdir rules
vim /usr/local/prometheus/rules/node_rules.yml
groups:
- name: node_alerts
rules:
- alert: HighNodeCpuLoad
expr: node_load1{job=~"aliyun"} > 2
for: 2m
labels:
severity: waring
annotations:
summer: High Node CPU for 1m
console: Please check cpu load ,active 2m.7 Prometheus配置告警规则引入
vim prometheus.yml
rule_files:
- "rules/*_rules.yml"
systemctl restart prometheus8 在某一个节点进行cpu压力测试
while [ 1 ];do : ;done
如cpu多可以多起几个9 页面查看alert
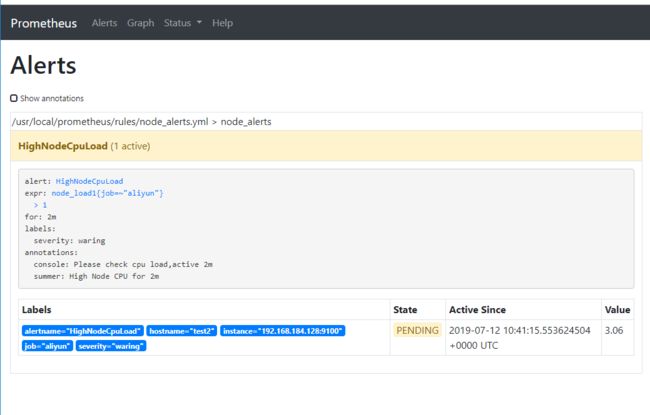
现在事pending状态,过2分钟将会变成报警状态,因为我们设置的是2分钟

10 查看alertmanager页面
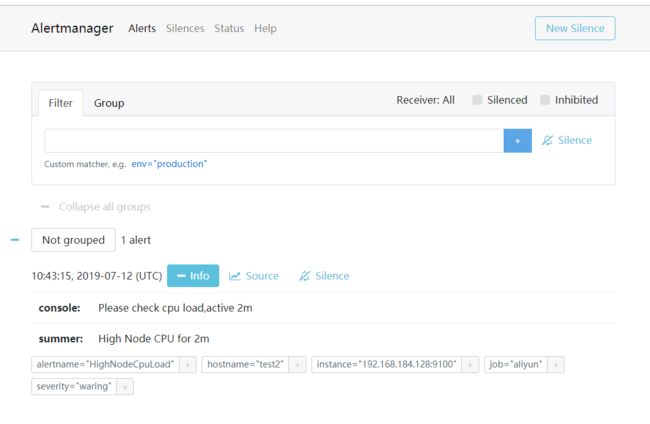
发现已经接受到告警
添加一条服务器down机规则
1)修改配置文件
[root@node1 rules]# cat node_alerts.yml
groups:
- name: node_alerts
rules:
- alert: HighNodeCpuLoad
expr: node_load1{job=~"aliyun"} > 1
for: 2m
labels:
severity: waring
annotations:
summer: High Node CPU for 2m
console: Please check cpu load,active 2m
#一下内容添加
- alert: HostDown
expr: up{job="aliyun"} == 0
for: 1m
labels:
severity: critical
annotations:
summary: Host {{ $labels.instance }} of {{ $labels.job }} is Down!
console: '110 吗?服务器挂了!!!!'2)关闭一台被监控的节点
3)查看prometheus alert页面
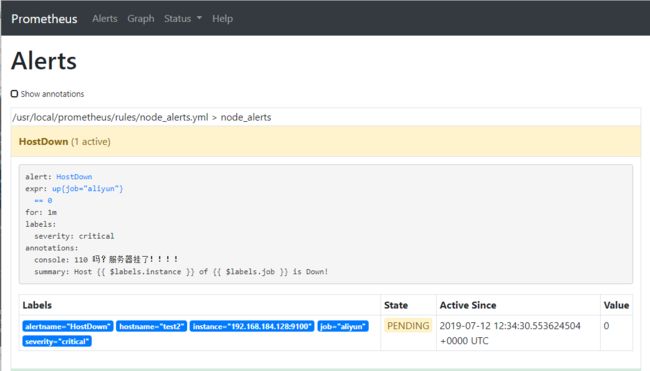
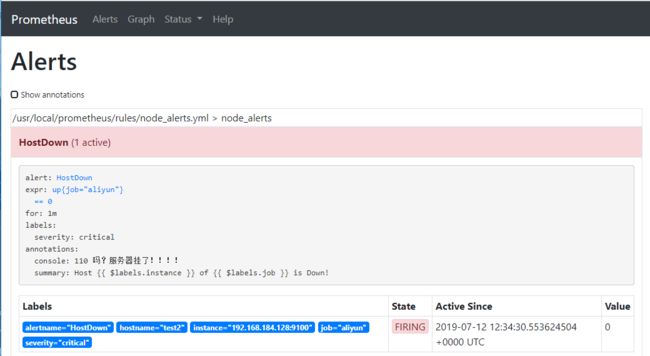
4)查看Alertmanager告警页面

11 查看邮件
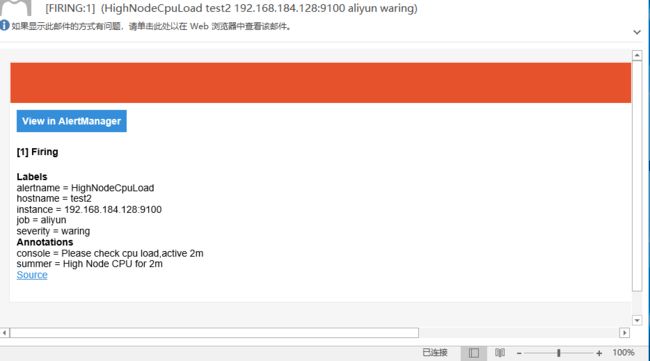
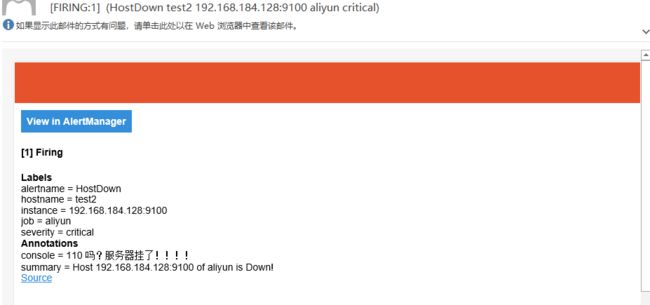
12 Alertmanager路由
路由匹配
每一个告警都会从配置文件中顶级的route进入路由树,需要注意的是顶级的route必须匹配所有告警(即不能有任何的匹配设置match和match_re),每一个路由都可以定义自己的接受人以及匹配规则。默认情况下,告警进入到顶级route后会遍历所有的子节点,直到找到最深的匹配route,并将告警发送到该route定义的receiver中。但如果route中设置continue的值为false,那么告警在匹配到第一个子节点之后就直接停止。如果continue为true,报警则会继续进行后续子节点的匹配。如果当前告警匹配不到任何的子节点,那该告警将会基于当前路由节点的接收器配置方式进行处理。其中告警的匹配有两种方式可以选择。一种方式基于字符串验证,通过设置match规则判断当前告警中是否存在标签labelname并且其值等于labelvalue。第二种方式则基于正则表达式,通过设置match_re验证当前告警标签的值是否满足正则表达式的内容。如果警报已经成功发送通知, 如果想设置发送告警通知之前要等待时间,则可以通过repeat_interval参数进行设置。
告警分组
Alertmanager可以对告警通知进行分组,将多条告警合合并为一个通知。这里我们可以使用group_by来定义分组规则。基于告警中包含的标签,如果满足group_by中定义标签名称,那么这些告警将会合并为一个通知发送给接收器。有的时候为了能够一次性收集和发送更多的相关信息时,可以通过group_wait参数设置等待时间,如果在等待时间内当前group接收到了新的告警,这些告警将会合并为一个通知向receiver发送。而group_interval配置,则用于定义相同的Gourp之间发送告警通知的时间间隔。
我们可以通过instance job 等标签进行分组并根据定义的告警的级别将告警发送给不同级别人员经行处理。编辑
1)编辑配置文件
[root@node1 alertmanager]# cat alertmanager.yml
global:
resolve_timeout: 5m
smtp_smarthost: '[email protected]:25'
smtp_from: '[email protected]'
smtp_auth_username: 'xxx'
smtp_auth_password: '!xxxxx'
smtp_require_tls: false
route:
group_by: ['instance']
group_wait: 30s
group_interval: 1m
repeat_interval: 5m
receiver: 'lv1'
routes:
- match:
severity: critical
receiver: lv1
- match_re:
severity: ^(critical|warning)$
receiver: lv2
receivers:
- name: 'lv1'
email_configs:
- to: '[email protected]'
- name: 'lv2'
email_configs:
- to: '[email protected]'
group_by: 根据 labael(标签)进行匹配,如果是多个,就要多个都匹配
group_wait: 30s 等待该组的报警,看有没有一起合伙搭车的
group_interval: 5m 下一次报警开车时间
repeat_interval: 3h 重复报警时间
注意:
新报警报警时间: 上一次报警之后的 group_interval 时间
重复的报警,下次报警时间为:group_interval + repeat_interval
其中 severity 级别分类是rules告警规则配置文件中定义的 在路由中进行分类
[root@node1 local]# cat prometheus/rules/node_alerts.yml
groups:
- name: node_alerts
rules:
- alert: HighNodeCpuLoad
expr: node_load1{job=~"aliyun"} > 1
for: 2m
labels:
severity: waring
annotations:
summer: High Node CPU for 2m
console: Please check cpu load,active 2m
- alert: HostDown
expr: up{job="aliyun"} == 0
for: 1m
labels:
severity: critical
annotations:
summary: Host {{ $labels.instance }} of {{ $labels.job }} is Down!
console: '110 吗?服务器挂了!!!!'2)测试
目前我们监控了两台主机,我们将一台主机的cpu做一个压测,另外一台将器关机
查看proetheus alerts和alertmanager收到的告警信息
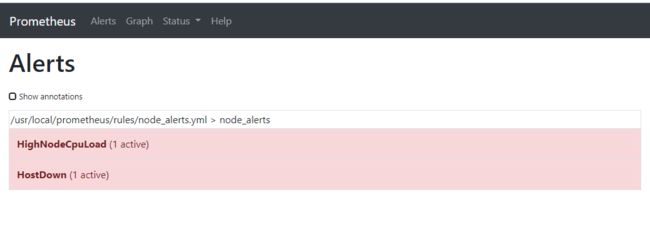
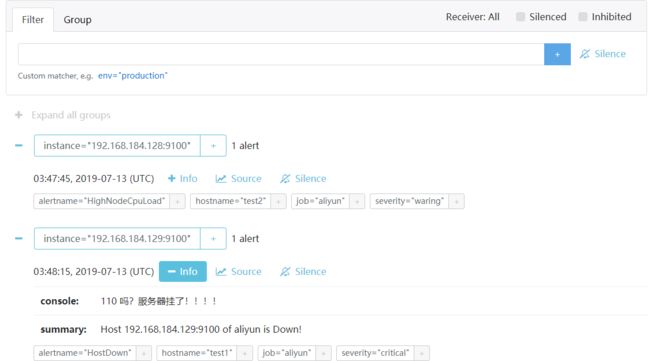
查看邮箱是否接受到邮件


如果在过一段时间观察发现如果告警没有恢复将会重复告警。
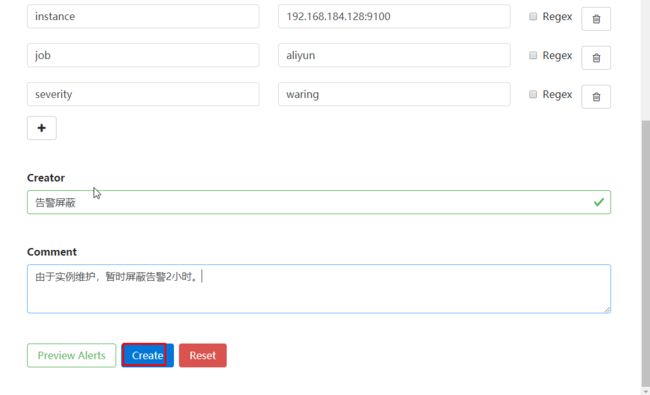
13 告警静默设置
静默可以理解为屏蔽告警,当我们需要维护某一个被监控的实例由于一些操作可能会触发 监控告警,但是我们不需要接收到这些告警此时我们可以设置告警静默。
告警静默可以再UI页面上设置也可以通过命令行设置,我们这里只演示再页面上设置告警静默