字体反爬
原理: 个别字符使用网站自定义的字体文件,导致部分源码显示出现乱码的情况 ;前端通过@font-face定义字体文件
目标网站
1. F12打开开发者调试工具; 部分字符无法正常显示

2. 源码查找@font-face 字体文件; 发现通过base64转码

3. 通过base64编码后的字符获取字体文件和对应的xml文件
# base64解码获取字体文件
import base64
base64_str = 'd09GRgABAAAAAAjgAAsAAAAADMQAAQAAAAAAAAAAAAAAAAAAAAAAAAAAAABHU1VCAAABCAAAADMAAABCsP6z7U9TLzIAAAE8AAAARAAAAFZW7laLY21hcAAAAYAAAAC3AAACTEyD4y5nbHlmAAACOAAABFoAAAVAGY5QymhlYWQAAAaUAAAALwAAADYXCzqSaGhlYQAABsQAAAAcAAAAJAeKAzlobXR4AAAG4AAAABIAAAAwGp4AAGxvY2EAAAb0AAAAGgAAABoIMAa6bWF4cAAABxAAAAAfAAAAIAEZAEduYW1lAAAHMAAAAVcAAAKFkAhoC3Bvc3QAAAiIAAAAWAAAAI/3SQzFeJxjYGRgYOBikGPQYWB0cfMJYeBgYGGAAJAMY05meiJQDMoDyrGAaQ4gZoOIAgCKIwNPAHicY2BksmCcwMDKwMHUyXSGgYGhH0IzvmYwYuRgYGBiYGVmwAoC0lxTGBwYKr5zMuv812GIYdZhuAIUZgTJAQDbkAsdeJzFkj0OgzAMhV8ayk/p0LGHQOJ6nKAn6MYR2Dr1FGwwIyE2oowZ6TNmqQRr+6IvUl4sO3IM4AzAkoJEgHnDQPSia1bf4rL6ER4833Gjk6IamqmYR1e61vW+9l2wIVsWRhzf7Mkw496SmxNy1o6RsbblS1MktOODTD+Q+V/pb13X/bmdclJt8IlDo7B/mApFYuZRkf90pcLuwrUK+wzXKzILvlZkPnynyLwEq/A/EDIFyQejakSoAHicTZTPb9tkGMff107stHV+NY6dH00aJ6ntOD/9O7+TtmnTtU3XrmuzbkVr2Cq1KisMhsRUxg5dDxyYuHHgioSEhBDSJiQuaEJoFxAS1SR2QTtw4ID4D8h442SAn4tf+/Xjz/N8v88LIAAv/wQKoAEGgKn66SgtAnSh1ctzbAJ7ChJABQDyAp+IkwTpgv46VKPQT6MFQaLHumYarMEyLKQZllEV0zA1ay/8jJ2YSetcmnU6ude0nfuRNF+q394sr7Xe3mkLVP9jcSqXzGph10bhQkbCxnSWZ2Pl6JaWz2Onh62qrDIEcWnjybO9y06nnN/v/5LtMkwud3Flx4gjxgH7rxiF/QRMxD74uWEaumaRmgprqApaDbEF9AbtGHGjrX5En4gLvHAWDibNKq+LUo2RxgnchpWvNYtaRAyuesuV7SpK4kkos8kktVA56jVWqEedeJycyayqYsrRwbFqQ25Ox1qe3YJCEOHAVbke4ll7Kb90UJkva71XvXyO0dj3YAK4AbALdh2qPpUU3DAMcRau2PtPYadBHU9ujB1Q2IsX/s/xVfhHf2bL9rUT2uB2/zHxX55J7GeQAiVUcRQiONMKAZU9qkjnkR7KoEQGqWXVCA1+8NZPs4zJoBY9pGqyVCcTFGGbdMOgnC1utuvOtdmbi++FEvZE9O7qrm5OwGP8cqkmyNL0cl1MfVI3+FjMCE1NhR12Qmfp2bnr9+Y7js5m7ezh5qUrhUIXzq1dm5iQ8+tLUoYkVWFlpNFzzIs9AcmRRkgUQ7B4SMFn93Mk8pOC7EOPBPlwnM/U9KuwyC1k4nRiqwjf7/9e4Bbir69qtnL77n696fhyMZzaX9zOZNxuHy164APH9g8sOzd3eKN5Q2ls/usNN/YtCALgEzjLrcMQeHPUNdOu2eBveIGJi4I35Im4ui52zBOruQtcvP8p9sZak6tmy+1GY/HKiSut1fST2xU5q1Kj/H/BB2g+XANFfS5I6lZOnfXB0+tU9khcLidsfAX34lglVfN0E7xMSk7n38URmw19mwNgxm83BMP8X7yyLMJULJ8Owg2HNxjeD/hsAQcRoSIhqSqKjNSpzQoC3MWXa+cnlN2bCUynxfkgRY258Oq2K5ehAjFPIBzmxDwfLR0sB7T2+GFRfbebEwWV5WKKGPJSFOUEALe0ciKuIBBAGfXNGm40Sgwam4Gj6KHDNMMkkGLWtPGIFUfGspQ163B4TrCPj0ul3l65cqs1JZ3d2V9oLMl2gZtPJrnWYSwemaQTCSmm+0UsXVKbUsYH30nd6vEqLi11juIRWZ7fu9+s3Wz3vjCmOYri4rlCK5brfyQGc+NRhhZPJUlKFUYz8SM2hp0DFvAD4kEH1cFxxJCMdV4JBCJmEaEyPBwGdDIRCunG+p3ZgNdjsxGEa+pg/c3i0q6Uuiel06kPZnIUvHjW6Mpp6jA9V3urmWqK61uYe6f3zPaNubigPvpOqWgXvgL/AMuS9QwAAHicY2BkYGAA4nerBD7G89t8ZeBmYQCBm19/VyPo/2dYGJguA7kcDEwgUQB+Ag2AAHicY2BkYGDW+a/DEMPCAAJAkpEBFfAAADNiAc14nGNhAIIUBgYmS+IwAEI2ArcAAAAAAAAADABeALIA1gEwAWwBnAG6AgYCYAKgAAB4nGNgZGBg4GGwZmBmAAEmIOYCQgaG/2A+AwAPlgFhAHicZZG7bsJAFETHPPIAKUKJlCaKtE3SEMxDqVA6JCgjUdAbswYjv7RekEiXD8h35RPSpcsnpM9grhvHK++eOzN3fSUDuMY3HJyee74ndnDB6sQ1nONBuE79SbhBfhZuoo0X4TPqM+EWungVbuMGb7zBaVyyGuND2EEHn8I1XOFLuE79R7hB/hVu4tZpCp+h49wJt7BwusJtPDrvLaUmRntWr9TyoII0sT3fMybUhk7op8lRmuv1LvJMWZbnQps8TBM1dAelNNOJNuVt+X49sjZQgUljNaWroyhVmUm32rfuxtps3O8Hort+GnM8xTWBgYYHy33FeokD9wApEmo9+PQMV0jfSE9I9eiXqTm9NXaIimzVrdaL4qac+rFWGMLF4F9qxlRSJKuz5djzayOqlunjrIY9MWkqvZqTRGSFrPC2VHzqLjZFV8af3ecKKnm3mCH+A9idcsEAeJxtyDsOgCAURNE3+EER90IwaCiVz15s7ExcvoFn6TQnd0gQT9H/NAQatOjQQ2LACIUJGjPhkfd1JrMf1ezZGFfu6LhtLubN+M+F/5CqIXE7G4heMREYAg=='
data = base64.decodebytes(base64_str.encode())
with open('maoyan.woff', 'wb') as f:
f.write(data)
# 获取字体对应的xml文件
import base64
from fontTools.ttLib import TTFont
from io import BytesIO
base64_str = 'd09GRgABAAAAAAjgAAsAAAAADMQAAQAAAAAAAAAAAAAAAAAAAAAAAAAAAABHU1VCAAABCAAAADMAAABCsP6z7U9TLzIAAAE8AAAARAAAAFZW7laLY21hcAAAAYAAAAC3AAACTEyD4y5nbHlmAAACOAAABFoAAAVAGY5QymhlYWQAAAaUAAAALwAAADYXCzqSaGhlYQAABsQAAAAcAAAAJAeKAzlobXR4AAAG4AAAABIAAAAwGp4AAGxvY2EAAAb0AAAAGgAAABoIMAa6bWF4cAAABxAAAAAfAAAAIAEZAEduYW1lAAAHMAAAAVcAAAKFkAhoC3Bvc3QAAAiIAAAAWAAAAI/3SQzFeJxjYGRgYOBikGPQYWB0cfMJYeBgYGGAAJAMY05meiJQDMoDyrGAaQ4gZoOIAgCKIwNPAHicY2BksmCcwMDKwMHUyXSGgYGhH0IzvmYwYuRgYGBiYGVmwAoC0lxTGBwYKr5zMuv812GIYdZhuAIUZgTJAQDbkAsdeJzFkj0OgzAMhV8ayk/p0LGHQOJ6nKAn6MYR2Dr1FGwwIyE2oowZ6TNmqQRr+6IvUl4sO3IM4AzAkoJEgHnDQPSia1bf4rL6ER4833Gjk6IamqmYR1e61vW+9l2wIVsWRhzf7Mkw496SmxNy1o6RsbblS1MktOODTD+Q+V/pb13X/bmdclJt8IlDo7B/mApFYuZRkf90pcLuwrUK+wzXKzILvlZkPnynyLwEq/A/EDIFyQejakSoAHicTZTPb9tkGMff107stHV+NY6dH00aJ6ntOD/9O7+TtmnTtU3XrmuzbkVr2Cq1KisMhsRUxg5dDxyYuHHgioSEhBDSJiQuaEJoFxAS1SR2QTtw4ID4D8h442SAn4tf+/Xjz/N8v88LIAAv/wQKoAEGgKn66SgtAnSh1ctzbAJ7ChJABQDyAp+IkwTpgv46VKPQT6MFQaLHumYarMEyLKQZllEV0zA1ay/8jJ2YSetcmnU6ude0nfuRNF+q394sr7Xe3mkLVP9jcSqXzGph10bhQkbCxnSWZ2Pl6JaWz2Onh62qrDIEcWnjybO9y06nnN/v/5LtMkwud3Flx4gjxgH7rxiF/QRMxD74uWEaumaRmgprqApaDbEF9AbtGHGjrX5En4gLvHAWDibNKq+LUo2RxgnchpWvNYtaRAyuesuV7SpK4kkos8kktVA56jVWqEedeJycyayqYsrRwbFqQ25Ox1qe3YJCEOHAVbke4ll7Kb90UJkva71XvXyO0dj3YAK4AbALdh2qPpUU3DAMcRau2PtPYadBHU9ujB1Q2IsX/s/xVfhHf2bL9rUT2uB2/zHxX55J7GeQAiVUcRQiONMKAZU9qkjnkR7KoEQGqWXVCA1+8NZPs4zJoBY9pGqyVCcTFGGbdMOgnC1utuvOtdmbi++FEvZE9O7qrm5OwGP8cqkmyNL0cl1MfVI3+FjMCE1NhR12Qmfp2bnr9+Y7js5m7ezh5qUrhUIXzq1dm5iQ8+tLUoYkVWFlpNFzzIs9AcmRRkgUQ7B4SMFn93Mk8pOC7EOPBPlwnM/U9KuwyC1k4nRiqwjf7/9e4Bbir69qtnL77n696fhyMZzaX9zOZNxuHy164APH9g8sOzd3eKN5Q2ls/usNN/YtCALgEzjLrcMQeHPUNdOu2eBveIGJi4I35Im4ui52zBOruQtcvP8p9sZak6tmy+1GY/HKiSut1fST2xU5q1Kj/H/BB2g+XANFfS5I6lZOnfXB0+tU9khcLidsfAX34lglVfN0E7xMSk7n38URmw19mwNgxm83BMP8X7yyLMJULJ8Owg2HNxjeD/hsAQcRoSIhqSqKjNSpzQoC3MWXa+cnlN2bCUynxfkgRY258Oq2K5ehAjFPIBzmxDwfLR0sB7T2+GFRfbebEwWV5WKKGPJSFOUEALe0ciKuIBBAGfXNGm40Sgwam4Gj6KHDNMMkkGLWtPGIFUfGspQ163B4TrCPj0ul3l65cqs1JZ3d2V9oLMl2gZtPJrnWYSwemaQTCSmm+0UsXVKbUsYH30nd6vEqLi11juIRWZ7fu9+s3Wz3vjCmOYri4rlCK5brfyQGc+NRhhZPJUlKFUYz8SM2hp0DFvAD4kEH1cFxxJCMdV4JBCJmEaEyPBwGdDIRCunG+p3ZgNdjsxGEa+pg/c3i0q6Uuiel06kPZnIUvHjW6Mpp6jA9V3urmWqK61uYe6f3zPaNubigPvpOqWgXvgL/AMuS9QwAAHicY2BkYGAA4nerBD7G89t8ZeBmYQCBm19/VyPo/2dYGJguA7kcDEwgUQB+Ag2AAHicY2BkYGDW+a/DEMPCAAJAkpEBFfAAADNiAc14nGNhAIIUBgYmS+IwAEI2ArcAAAAAAAAADABeALIA1gEwAWwBnAG6AgYCYAKgAAB4nGNgZGBg4GGwZmBmAAEmIOYCQgaG/2A+AwAPlgFhAHicZZG7bsJAFETHPPIAKUKJlCaKtE3SEMxDqVA6JCgjUdAbswYjv7RekEiXD8h35RPSpcsnpM9grhvHK++eOzN3fSUDuMY3HJyee74ndnDB6sQ1nONBuE79SbhBfhZuoo0X4TPqM+EWungVbuMGb7zBaVyyGuND2EEHn8I1XOFLuE79R7hB/hVu4tZpCp+h49wJt7BwusJtPDrvLaUmRntWr9TyoII0sT3fMybUhk7op8lRmuv1LvJMWZbnQps8TBM1dAelNNOJNuVt+X49sjZQgUljNaWroyhVmUm32rfuxtps3O8Hort+GnM8xTWBgYYHy33FeokD9wApEmo9+PQMV0jfSE9I9eiXqTm9NXaIimzVrdaL4qac+rFWGMLF4F9qxlRSJKuz5djzayOqlunjrIY9MWkqvZqTRGSFrPC2VHzqLjZFV8af3ecKKnm3mCH+A9idcsEAeJxtyDsOgCAURNE3+EER90IwaCiVz15s7ExcvoFn6TQnd0gQT9H/NAQatOjQQ2LACIUJGjPhkfd1JrMf1ezZGFfu6LhtLubN+M+F/5CqIXE7G4heMREYAg=='
data = base64.decodebytes(base64_str.encode())
font = TTFont(BytesIO(data))
font.saveXML('maoyan.xml')
4. .woff字体文件须通过FontCreator工具打开(可自行百度下载); 如图所示
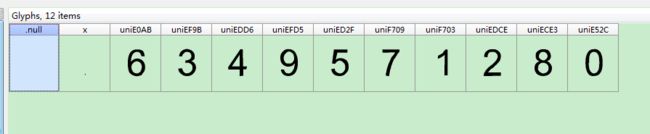
5. 解析xml文件, 可直接通过正则获取code和name属性之间的关系; code对应网页源码显示内容,name对应FontCreator 工具显示内容
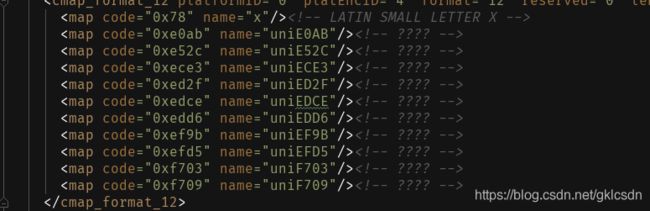
# 获取code和name之间的关系
import re
with open('maoyan.xml', 'r', encoding='utf-8') as f:
data = f.read()
items = {}
data_list = re.findall(r'', data)
for i in data_list:
items[i[0]] = i[1]
print(items)
{'0x78': 'x', '0xe0ab': 'uniE0AB', '0xe52c': 'uniE52C', '0xece3': 'uniECE3', '0xed2f': 'uniED2F', '0xedce': 'uniEDCE', '0xedd6': 'uniEDD6', '0xef9b': 'uniEF9B', '0xefd5': 'uniEFD5', '0xf703': 'uniF703', '0xf709': 'uniF709'}
6. 将code和name的关系转换成code和对应数字之间的关系,只保留0-910个数字,如下
{'': 6, '': 0, '': 8, '0xed2f': 5, '': 2, '': 4, '': 3, '': 9, '': 1, '0xf709': 7}
7. 由于每次刷新页面name和code的关系都会发生变化,我的解决办法是先保存网页源码到本地文件,然后替换特殊字符
8. 源码参考
import re
import base64
import requests
from io import BytesIO
from fontTools.ttLib import TTFont
class Spider(object):
"""
保存网页源码,获取woff字体文件,获取字体对应的xml文件
"""
def __init__(self):
self.url = 'https://piaofang.maoyan.com/rankings/year?year=2019&limit=100&tab=1'
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36'
}
def get_base64_unicode(self):
"""
获取base64编码和Unicode数据并保存网页源码
:return:
"""
response = requests.get(self.url, headers=self.headers).text
with open('maoyan.html', 'w') as f:
f.write(response)
base64_str = re.findall(r'base64,(.*?)\)', response)[0]
unicode_str = re.findall(r'&#(.*?);', response)
return base64_str, unicode_str
def make_xml(self, base64_str):
"""
生成xml文件和字体文件
:return:
"""
data = base64.decodebytes(base64_str.encode())
with open('maoyan.woff', 'wb') as f:
f.write(data)
font = TTFont(BytesIO(data))
font.saveXML('maoyan.xml')
def get_relationship(self):
"""
解析xml文件,获取Unicode和name属性之间的关系
:return:
"""
# unicode 和 name 属性之间的对应关系
unicode_name_dict = {}
with open('maoyan.xml', 'r') as f:
data = f.read()
unicode_name = re.findall(r'', data)
for i in unicode_name:
unicode_name_dict[i[0]] = i[1]
return unicode_name_dict
def run(self):
base64_str, unicode_str = self.get_base64_unicode()
self.make_xml(base64_str)
unicode_name_dict = self.get_relationship()
print(unicode_name_dict)
if __name__ == '__main__':
s = Spider()
s.run()
# 数据持久化
import json
from lxml import etree
# 字典每次运行都会变化
unicode_dict = {'': 1, '': 3, '': 9, '': 4, '': 5, '': 7, '': 0, '': 8, '': 2, '': 6}
keys = list(unicode_dict.keys())
with open('maoyan.html', 'r') as f:
data = f.read()
new_data = data.replace(keys[0], str(unicode_dict[keys[0]]))
new_data = new_data.replace(keys[1], str(unicode_dict[keys[1]]))
new_data = new_data.replace(keys[2], str(unicode_dict[keys[2]]))
new_data = new_data.replace(keys[3], str(unicode_dict[keys[3]]))
new_data = new_data.replace(keys[4], str(unicode_dict[keys[4]]))
new_data = new_data.replace(keys[5], str(unicode_dict[keys[5]]))
new_data = new_data.replace(keys[6], str(unicode_dict[keys[6]]))
new_data = new_data.replace(keys[7], str(unicode_dict[keys[7]]))
new_data = new_data.replace(keys[8], str(unicode_dict[keys[8]]))
new_data = new_data.replace(keys[9], str(unicode_dict[keys[9]]))
page = etree.HTML(new_data)
node_list = page.xpath('//ul[@class="row"]')
for node in node_list[1:]:
rank = node.xpath('./li[1]/text()')[0]
name = node.xpath('./li[2]/p[@class="first-line"]/text()')[0]
play_time = node.xpath('./li[2]/p[@class="second-line"]/text()')[0]
money = node.xpath('./li[3]/i/text()')[0] + '万元'
avg_price = node.xpath('./li[4]/i/text()')[0] + '万元'
avg_people = node.xpath('./li[5]/i/text()')[0]
items = {
'排名': rank,
'电影名': name,
'播放时间': play_time,
'票房': money,
'平均票价': avg_price,
'均场人次': avg_people
}
print(items)
with open('maoyan.json', 'a', encoding='utf-8') as f:
f.write(json.dumps(items, ensure_ascii=False) + '\n')
9. 结果如下

10. 不足之处
unicode_dict = {'': 1, '': 3, '': 9, '': 4, '': 5, '': 7, '': 0, '': 8, '': 2, '': 6}
字典每次都需要手动修改, 暂时没有好的解决办法