云服务器搭建 Prometheus 与实战(上)
1.前言
背景
衡量一个公司技术成熟与否的重要因素是一个公司的运维系统的水准,运维系统的核心便是监控与报警,诸多初创公司或传统行业区别于成熟大厂的主要方面便是难以建立快速有效的监控与质量体系抑或是他们本身便不够重视。今天我们要讨论的便是一款优秀的监控报警框架。
Prometheus
Prometheus 是什么?简而言之,Prometheus 是一款基于 Google 内部 Borgmon 监控系统理念衍生出的一种非 Google 官方的开源的监控报警框架。
然而这款“非官方”的报警框架,在 2015 年正式加入 Cloud Native Computing Foundation(云原生计算基金会),摇身一变成为一款炙手可热的“生态级”监控框架,与 K8s,gRPC,Docker 结合,变成了实现“坚持和整合开源技术来编排容器作为微服务架构”这一愿景不可或缺的一环。
Prometheus 有什么区别于其他基于 TSDB(时序数据库)的监控产品之处呢?选择 Prometheus 的原因又是什么?
经过几天的搭建调研,笔者总结出以下几点:
- 灵活而强大的查询语句(PromQL):在同一个查询语句,可以对多个 Metrics 进行乘法、加法、连接、取分数位等操作
- 易于管理: Prometheus Server 是一个单独的二进制文件,可直接在本地工作,不依赖于分布式存储
- 高效:平均每个采样点仅占 3.5 bytes,且一个 Prometheus Server 可以处理数百万的 Metrics
- 使用 pull 模式采集时间序列数据,代码侵入低
- 低成本实现高配置化 Metics 配置(Push Gateway),这是我认为最为主要的一点,Metics 的个性化推送有相应的 SDK,支持 Golang、Java、Python 等语言
- 低成本部署,第一次搭建完成 Prometheus 之后,我们会发现,原来部署是如此的 easy,所有的组件都是一个二进制文件,并且原生支持 Docker 容器化部署,易于扩展
其余优点或不足,需各位在使用之余慢慢发现了。
附官网:https://prometheus.io/
无需赘言,我们现在开始从 0 搭建一套 Prometheus 系统,为大家演示一下其用法与接入流程。
2. Prometheus 工作流程
引用官方一张图

简单来说,其工作流程与所有监控系统类似:收集的 Client->处理的 Sever->报警系统/ UI 展示系统。
Client
其中收集的 Client 可以分为两大类:
- PushGateway
- 其他的 Exporter
为何如此区分,PushGateway 可以理解为一个通用的 Metics 接收的 Sever,其不止承担由 Sever 端 pull 各种 Metics 的作用,同样可以接收由各种渠道(脚本,业务系统)发送来的 point,这种场景非常适合于进行业务监控。PushGateway 的用法笔者将在下文详述。
而其他的 Exporter 是指 Prometheus 官方推出的各种Exporter,例如,节点硬件监控(CPU,内存等)-node_exporter,MySQL 监控 -MySQL Server Exporter 等等,或是由一些第三方推出的监控客户端等。具体的 Exporter 种类可见:https://prometheus.io/docs/instrumenting/exporters/
Sever
Prometheus 的 Sever 本质上只有一个二进制文件,部署十分方便,同时由一个 yml 配置文件来管控 Sever 的所有行为,Prometheus 的 Sever 需要从各个 Client 拉取 Metics,这个过程支持服务发现,同时把拉取到的点录入时序数据库,并输出一个 API 以供查询和 UI 展示
报警/UI
Prometheus 官方推出的报警系统名为 AlertManager,这个模块不做具体的报警规则的配置和录入,只是实现从 Sever 端接收到 alert 之后将报警信息通过配置的报警手段和聚合策略,将报警信息聚合之后发送,支持电邮、Webhook 等手段。具体的报警的阈值与规则的录入仍在 Sever 端的配置文件中。
Prometheus 的 Sever 在启动时会自带一个 Bootstrap 风格的 UI 用于展现,但此 UI 可谓相当丑陋,难用,只能支持基本功能,而 Prometheus 支持将数据录入 Grafana,这真是极好的。
3. Prometheus 的部署与演示验证
1. 硬件准备
为了更贴近于生产环境与多节点等环境,笔者没有选择在 macOS 系统下操作而是在滴滴云上选取了两台按时长计费的云服务器进行验证。
配置为:
- Centos-7.4 4C8G 40G-HDD云盘 1M带宽 IP地址:116.85.10.244 用于搭建 Sever 端
- Centos-7.4 4C8G 40G-HDD云盘 1M带宽 IP地址:116.85.10.243 用于搭建 Exporter 与模拟业务服务
2. 初级实战
事实上,仅搭建一个 Sever 端,即可跑通整个 Prometheus 的流程,因为 Sever 默认会从本机收取 Sever 自我本身运行的状态,自监控,同时 Sever 端会默认提供一个 UI。
那么,初级实战,便是先搭起一个 Sever。
Prometheus 官方提供了很多种部署的方法。比较常用的有三种:
- 直接下载 tar 包、解压缩、执行、开箱即用
mkdir test-for-prometheus
cd test-for-prometheus
wget https://github.com/prometheus/prometheus/releases/download/v2.6.0-rc.0/prometheus-2.6.0-rc.0.linux-amd64.tar.gz
tar xf prometheus-2.6.0-rc.0.linux-amd64.tar.gz
cd prometheus-2.6.0-rc.0.linux-amd64
./prometheus --config.file=prometheus.yml
- 下载源码,编译后执行(适用于想撸源码的人)
yum clean all
#需求 1.5 版本以上的 Go
yum install -y go
mkdir -p $GOPATH/src/github.com/prometheus
cd $GOPATH/src/github.com/prometheus
git clone https://github.com/prometheus/prometheus.git
cd prometheus
make build
./prometheus --config.file=prometheus.yml
- 拉取 Docker 镜像,使用容器的方式启动,Docker 仓库为:https://hub.docker.com/r/prom/
yum clean all
#对 Docker 版本无硬性要求,滴滴云的 yum 源默认装 1.13 的,这个版本不算新,但注意测试的时候的 Docker 版本需要和线上一致
yum install -y docker
service docker start
docker pull prom/prometheus
docker docker run -d -p 9090:9090 --name prometheus prom/prometheus
无论采用哪种方法,很容易便可以将一个简易的 Sever 搭建成功,并采用系统默认的配置项。
系统默认的配置文件如下:
#全局配置
global:
scrape_interval: 15s #默认抓取间隔, 15秒向目标抓取一次数据。
evaluation_interval: 15s #Evaluate rules every 15 seconds. The default is every 1 minute.
#scrape_timeout is set to the global default (10s).
#这个标签是在本机上每一条时间序列上都会默认产生的,主要可以用于联合查询、远程存储、Alertmanger时使用。
external_labels:
monitor: 'codelab-monitor'
#Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
# - "first.rules"
# - "second.rules"
# 这里就表示抓取对象的配置
# 这里是抓去promethues自身的配置
scrape_configs:
#job name 这个配置是表示在这个配置内的时间序例。
- job_name: 'prometheus'
#metrics_path defaults to '/metrics'
#scheme defaults to 'http'.
#重写了全局抓取间隔时间,由15秒重写成5秒。
scrape_interval: 5s
static_configs:
- targets: ['localhost:9090']
注意:缩进必须合规(下层比上层缩进2个空格)
配置文件分为两大块,global 与 scrape_configs 具体的注释在上文也有解释,读者可详细阅读理解。
默认的配置文件中有针对 Prometheus 进程本身的监控收集配置,默认收集地址是 localhost:9090,事实上,默认 UI 的访问地址亦是如此,我们尝试使用地址访问默认 UI。

默认 UI 已打开,选取下拉框可以看到:
已经有自身进程监控的相关信息可以查询了。
3. 中级实战
当然,只搭建一个 Sever 是毫无意义的,没有任何有价值的信息产出,我们需要一些有价值的监控信息,上文提到 Prometheus 官方提供有很多不同类型的 Exporter,笔者选取最简单的 node_exporter 进行部署,使其能够产生数据,并能够被 Sever 收集。
node_exporter 的部署与 Sever 部署步骤相仿,仍然是上述三大方法,此处略去。
笔者选用直接开箱方式部署(部署机器 116.85.10.243):
wget https://github.com/prometheus/node_exporter/releases/download/v0.14.0/node_exporter-0.14.0.linux-amd64.tar.gz
tar -xvzf node_exporter-0.14.0.linux-amd64.tar.gz
cd node_exporter-0.14.0.linux-amd64
./node_exporter &
好了,一个简单的 node_exporter 部署成功,默认的拉取端口为 9100,我们测试一下,手动执行:
curl http://localhost:9100/metrics
得到一长串类似于“node_vmstat_nr_mlock 0”的结果,代表我们已经部署成功。
接下来需要修改 Sever 的配置文件:
#全局配置
global:
scrape_interval: 15s #默认抓取间隔, 15秒向目标抓取一次数据。
evaluation_interval: 15s #Evaluate rules every 15 seconds. The default is every 1 minute.
#scrape_timeout is set to the global default (10s).
#这个标签是在本机上每一条时间序列上都会默认产生的,主要可以用于联合查询、远程存储、Alertmanger时使用。
external_labels:
monitor: 'codelab-monitor'
#Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
# - "first.rules"
# - "second.rules"
# 这里就表示抓取对象的配置
# 这里是抓去promethues自身的配置
scrape_configs:
#job name 这个配置是表示在这个配置内的时间序例。
- job_name: 'prometheus'
#metrics_path defaults to '/metrics'
#scheme defaults to 'http'.
#重写了全局抓取间隔时间,由15秒重写成5秒。
scrape_interval: 5s
static_configs:
- targets: ['localhost:9090']
#下列新增
- job_name: 'node' # 一定要全局唯一, 采集对应节点的 metrics,需要在对应节点安装 node_exporter
scrape_interval: 10s
static_configs:
- targets: ['116.85.10.243:9100'] #需采集node 的 endpoint,我的收集节点在另外一个机器上
OK,修改完毕之后将进程杀掉或者替换 Docker 目录 /etc/prometheus 下的配置文件,笔者的方法是直接挂载目录,docker run 的命令变为:
docker run -d -p 9090:9090 -v /root/test-for-prometheus:/etc/prometheus --name prometheus prom/prometheus
其中 /root/test-for-prometheus 为笔者存放配置文件的位置。
这里有一个让我困惑不解的地方在于,如果未接入服务发现,每接入一个类似的监控,都需要更改配置文件并重启服务,至少目前笔者未发现更好方式。
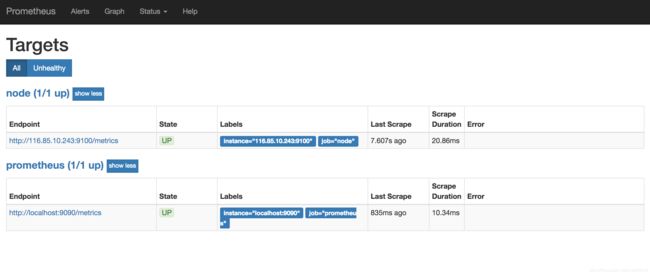
重启服务后,重新访问 UI。在 status-target 下会发现多出了一个 Node 的节点,则代表部署成功。
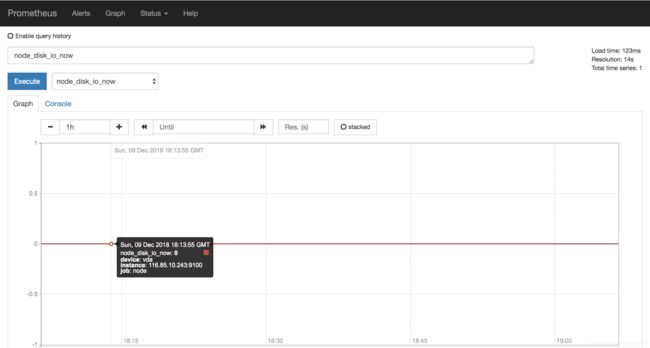
同时在 Graph 页面下拉框中多出了很多关于 Node 的监控项,并在选取后可以看到相应的取值。

4. 进阶实战
一个成熟的监控系统自然是不满足于只监控机器的状态和 HTTP 码等硬性指标的,要想监控业务指标,我们还需要一个神奇的组件 – PushGateway。
上文有提到过,PushGateway 用于接收业务自定义的 Metics 打点,并而且 Prometheus 已经提供了针对于各种语言的 SDK,那我们来实验一下。
首先,需要将 PushGateway 服务打起来,与上述两个服务的搭建相仿,这次笔者采用的是 Docker 部署形式,由于 PushGateway 明显带有 Sever 的一些特质,所以笔者将其部署在 Sever 机器(116.85.10.244)上。
docker pull prom/pushgateway
docker run -p 9091:9091 prom/pushgateway
docker ps
成功启动 PushGateway。同样的,更改 Sever 端的配置文件,在文件底部加上如下配置:
- job_name: 'gateway'
scrape_interval: 10s
static_configs:
- targets: ['116.85.10.244:9091']
重启服务后,重新访问 UI,发现 targets 内多出了一个收集项:

Gateway 搭建成功。
接下来要做的是向 Gateway 中推送数据。因笔者使用的是 Go 语言,所以便打算用 Go 语言实现了一个简单的 Sever。PushGateway 所有语言的 SDK 在 https://prometheus.io/docs/instrumenting/pushing/ 可以找到。
首先做好先期准备:
go get github.com/prometheus/client_golang/prometheus
这是 Prometheus 的 Golang Client 仓库,内含信息十分庞大,有完整的 API 文档,在此不再细说。
然后需要搭建一个简单业务,并嵌入 SDK,笔者采用了 Martini 框架搭建一个简单的 Web 服务,读者完全可以采用自己的方式,这里主要详述 PushGateway 的 SDK 使用方法,代码如下:
package main
import (
"fmt"
"github.com/prometheus/client_golang/prometheus"
"github.com/prometheus/client_golang/prometheus/push"
)
func main() {
//构建一个业务接口
r := Custom()
r.Post("/prometheus/collect", postPrometheusData)
r.m.RunOnAddr(":9001")
}
func postPrometheusData() {
completionTime := prometheus.NewGauge(prometheus.GaugeOpts{
Name: "db_backup_last_completion_timestamp_seconds",
Help: "The timestamp of the last successful completion of a DB backup.",
})
completionTime.SetToCurrentTime()
err := push.New("http://116.85.10.244:9091", "db_backup").
Collector(completionTime).Grouping("db", "customers").Push()
fmt.Println(err)
}
注意这里用到了
github.com/prometheus/client_golang/prometheus
github.com/prometheus/client_golang/prometheus/push
这两个包,前者是定义各种 Prometheus 数据类型的基础包,后者是专门用于推送的包,Prometheus 还提供 Promhttp 包,可直接基于此对外提供 HTTP 服务,个人觉得适用性不高所以未做尝试,读者感兴趣可详细阅读 https://godoc.org/github.com/prometheus/client_golang/prometheus 中的各种用法。
执行 build&run,运行我们的业务服务并测试调用:
curl -X POST 116.85.10.243:9001/prometheus/collect
发现接口无恙,同时观察监控 UI,发现在下拉框中多出了一个名为 db_backup_last_completion_timestamp_seconds 的监控项:

并且点开图表之后显示出值即是我们写入的值:

自此,大功告成,一个简易的业务+硬核监控已经搭建成功。
后记
通过搭建 Prometheus 的整个流程,笔者有一个非常深切的感受,搭建成本真的是非常的低。Prometheus 深度拥抱 Docker 与极简配置主义,对硬件差异适应性非常之好,有一定基础之人,花费半天至一天的时间,便可以从零搭建成功,很适合一些初创公司和快速上线的项目,是一个值得深入研究的优秀开源项目。
下次笔者会和大家分享 Prometheus 接入服务发现、Grafana、PromQL 与其报警系统 AlertManager 的故事,我们下次不见不散。