【网络】linux网口bond的链路检测及恢复机制
近期的项目中遇到了这样一个问题,引发了笔者对linux bond和lacp协议的一些研究:
情景:
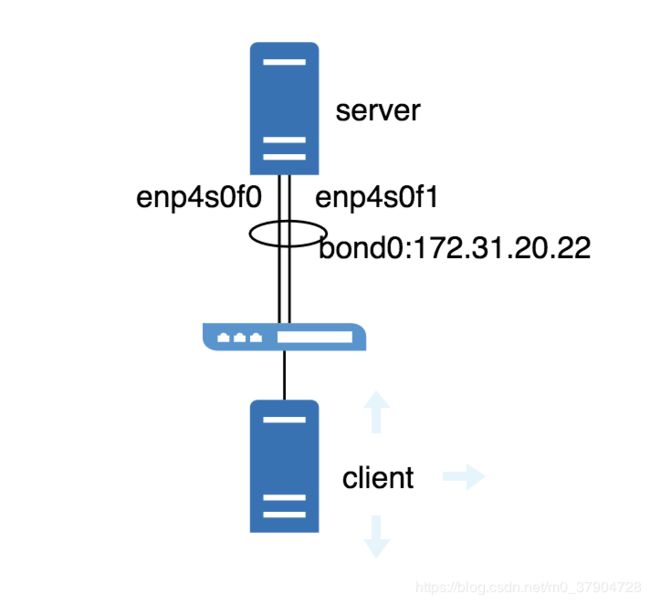
如上图所示,server有两张网卡配置了bond0, 工作在mode4负载均衡模式下, 现在从client对server进行持续的ping测试,发现:
- 插拔server端物理网口的网线时, ping一直正常,无丢包;
- 用ifconfig down enp4s0f0/1 来关闭物理网口时,ping会丢包,且持续1分多钟,之后恢复正常;
这个测试结果实在是非常的令人发指,bond技术的初衷就是为了链路冗余和增加带宽,现在却发现在人为关闭其中一个物理网口后,竟然会造成如此长时间的网络中断,不得不教人对其深究一二了,为了解决这个问题,我们必须搞清楚以下几个问题:
- 插拔网线时,网络正常,说明bond保证了链路冗余,是如何做到的?
- ifconfig down关闭网口时,网络中断,说明bond没有保证链路冗余,为什么?
- 网络中断后,是怎么自动恢复的?
- 在bond无法保证链路冗余时,为何中断时间这么长?
此处贴上server上的网卡配置文件,注意倒数第2,3行的注释信息,这将是本文讨论的重点内容:
# This file describes the network interfaces available on your system
# and how to activate them. For more information, see interfaces(5).
# The loopback network interface
auto lo
iface lo inet loopback
auto enp4s0f0
iface enp4s0f0 inet manual
bond-master bond0
auto enp4s0f1
iface enp4s0f1 inet manual
bond-master bond0
# mgmt network
auto bond0
iface bond0 inet static
address 172.31.20.22
mtu 1550
netmask 255.255.255.0
gateway 172.31.20.254
dns-nameservers 172.31.20.64
bond-mode 4
bond-miimon 100 # mii对slave网口的检测周期,为100ms
bond-lacp-rate 1 # lacpud发送周期为1s,配置为0则为30s
bond-slaves enp4s0f0 enp4s0f1问题1:插拔网线时,网络正常,说明bond保证了链路冗余,是如何做到的?
解答:bond为了保证链路高可用,提供了两种链路检测机制,分别是MII检测和ARP检测,上述配置中,`bond-miimon 100`表示bond进行MII检测的周期为100ms,在拔掉网线时,bond的MII检测会发现相应网口的链路故障,从而将流量引导到健康的网口上,关于MII检测的深入信息,与本文关系不大,可以参考IBM的相关文档。
问题2:既然bond可以检测到链路故障,为何在ifconfig down关闭网口时不能呢?
解答:bond的去读取/proc/net/bonding/bond0这个文件,去获取bond相关接口的状态信息,来达到检测的目的,正常情况下,该文件如下, 可以看到(已省去不必要的信息),bond0以及两个物理网口下,`MII Status: up`:
root@tr02n12:~# cat /proc/net/bonding/bond0
Ethernet Channel Bonding Driver: v3.7.1 (April 27, 2011)
Bonding Mode: IEEE 802.3ad Dynamic link aggregation
Transmit Hash Policy: layer2 (0)
MII Status: up
...
...
Slave Interface: enp4s0f0
MII Status: up
...
...
Slave Interface: enp4s0f1
MII Status: up
...
...如果拔掉enp4s0f0对应的网口,则会发现,enp4s0f0下会发生改变 `MII Status: down`, bond由此知道了该接口故障,将流量引导到enp4s0f1;
root@tr02n12:~# cat /proc/net/bonding/bond0
Ethernet Channel Bonding Driver: v3.7.1 (April 27, 2011)
Bonding Mode: IEEE 802.3ad Dynamic link aggregation
Transmit Hash Policy: layer2 (0)
MII Status: up
...
...
Slave Interface: enp4s0f0
MII Status: down
...
...
Slave Interface: enp4s0f1
MII Status: up
...
...那么如果使用命令关闭网口呢,让我们测试一下, 发现该文件中enp4s0f1的相关信息被删去了,因此bond不能获取到enp4s0f1的MII Status,也就无法检测到该条链路故障,也无法保证链路高可用了:
root@tr02n12:~# ifdown enp4s0f1
root@tr02n12:~# cat /proc/net/bonding/bond0
Ethernet Channel Bonding Driver: v3.7.1 (April 27, 2011)
Bonding Mode: IEEE 802.3ad Dynamic link aggregation
Transmit Hash Policy: layer2 (0)
MII Status: up
...
...
Slave Interface: enp4s0f0
MII Status: up问题3:网络中断后,是怎么自动恢复的?
解答:既然在运行命令关闭网口的情形下,bond无法做到故障检测,那么网络在一段时间后是如何自动恢复的呢?从bond的配置文件中,我们可以看到`bond-mode 4`, 这个模式也叫做802.3ad模式,可基于LACP协议保证链路的高可用,在故障时自动恢复,因此,这个问题的答案就是,网络中断是因为bond没有检测到链路故障,而LACP检测到了链路故障并进行了自动恢复,LACP是如何进行链路恢复的呢,这将在下一个问题中进行说明。
问题4:在bond无法保证链路冗余时,为何中断时间这么长?
解答:LACP链路聚合的两端设备的网口间,通过LACPDU与对端交换信息,首先让我们来看一下LACP报文的格式,其中:
LACP_Timeout:代表链路接收LACPDU报文的周期,有两种,快周期1s和慢周期30s,超时时间为周期的3倍。短超时被编码为1,长超时被编码为0。这一字段规定了超时时间,如果在超时时间内没有收到对端发送的LACPDU, 则认为链路故障,进行链路切换。在链路两端设备的LACP_Timeout值不一致时,以长的一方为准。鉴于我们的情景中,网络中断的时间足有1分多钟,有理由怀疑是因为此处超时时间协商为了90s,从配置文件中, `lacp-rate fast`表示server的bond口该字段配置的是短超时,那么问题有可能出现在对端交换机的聚合口配置上,让我们用tcpdump抓包验证一下(在enp4s0f0上抓取1个二层协议类型为0x8809,即LACP协议的包,并显示详细信息):
root@tr02n12:~# tcpdump -e ether -i enp4s0f0 proto 0x8809 -vv -c 1
tcpdump: listening on enp4s0f0, link-type EN10MB (Ethernet), capture size 262144 bytes
17:54:03.486988 ec:0d:9a:9c:99:56 (oui Unknown) > 01:80:c2:00:00:02 (oui Unknown), ethertype Slow Protocols (0x8809), length 124: LACPv1, length 110
Actor Information TLV (0x01), length 20
System ec:0d:9a:9c:99:56 (oui Unknown), System Priority 65535, Key 15, Port 3, Port Priority 255
State Flags [Activity, Timeout, Aggregation, Synchronization, Collecting, Distributing]
Partner Information TLV (0x02), length 20
System 5c:83:8f:4b:eb:c1 (oui Unknown), System Priority 32768, Key 126, Port 283, Port Priority 32768
State Flags [Activity, Aggregation, Synchronization, Collecting, Distributing]
Collector Information TLV (0x03), length 16
Max Delay 0
Terminator TLV (0x00), length 0
1 packet captured
1 packet received by filter
0 packets dropped by kernel通过对比enp4s0f0的mac地址,可以确定上面这个包为从enp4s0f0发送给对端LACP接口的LACPDU包,按照LACP报文的格式中的信息,可以看出,对端没有置位Timeout位,因此是设置的长超时,也就是90s,因此链路恢复的时间才会如此长。要解决该问题,则需要在交换机上对应的聚合端口也配置lacp超时时间为短超时,这样的话,在手动关闭网口后的恢复时间应会变成3s左右。
小结
本文通过一个手动关闭端口引发的bond口中断故障,进行分析,阐明了bond的链路检测及高可用原理,验证LACP的超时时间参数效果。解释了bond下插拔网线和命令关闭端口造成结果不同的原因。