深入浅出讲解语言模型
转载自 深入浅出讲解语言模型
深入浅出讲解语言模型
1、什么是语言模型呢?
简单地说,语言模型就是用来计算一个句子的概率的模型,也就是判断一句话是否是人话的概率?
那么如何计算一个句子的概率呢?给定句子(词语序列)
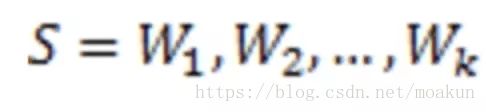
它的概率可以表示为:

可是这样的方法存在两个致命的缺陷:
-
參数空间过大:条件概率P(wn|w1,w2,..,wn-1)的可能性太多,无法估算,不可能有用;
-
数据稀疏严重:对于非常多词对的组合,在语料库中都没有出现,依据最大似然估计得到的概率将会是0。
2、马尔科夫假设
为了解决參数空间过大的问题。引入了马尔科夫假设:随意一个词出现的概率只与它前面出现的有限的一个或者几个词有关。
如果一个词的出现与它周围的词是独立的,那么我们就称之为unigram也就是一元语言模型:
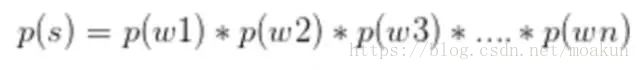
如果一个词的出现仅依赖于它前面出现的一个词,那么我们就称之为bigram:

假设一个词的出现仅依赖于它前面出现的两个词,那么我们就称之为trigram:

一般来说,N元模型就是假设当前词的出现概率只与它前面的N-1个词有关。而这些概率参数都是可以通过大规模语料库来计算,比如三元概率有:
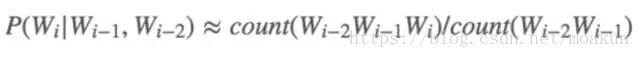
在实践中用的最多的就是bigram和trigram了,高于四元的用的非常少。
因为训练它须要更庞大的语料,并且数据稀疏严重,时间复杂度高,精度却提高的不多。
下面我们详细介绍一下一元语言模型,二元语言模型来帮助大家理解语言模型。
3、一元语言模型
一元语言模型中,我们的句子概率定义为: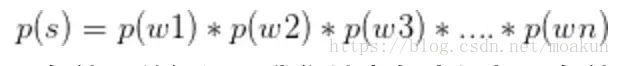
,在这里,这个式子成立的条件是有一个假设,就是条件无关假设,我们认为每个词都是条件无关的。
那好,刚刚说了语言模型是得到一个句子的概率,此时我们句子的概率计算公式已经有了,那么如何估计

![]() 这些值呢?
这些值呢?
首先介绍一下,这里的参数种类是![]() 一种 ,但是参数实例有V个(V是我们的词典大小)
一种 ,但是参数实例有V个(V是我们的词典大小)
我们应该如何得到每个参数实例的值。
用的是极大似然估计法。
比如我们说我们的训练语料是下面这个简单的语料。

那么我们的字典为:“星期五早晨,我特意起了个大早为的就是看天空。” 22个不同词,每个词语的概率直接用极大似然估计法估计得到。
如:p(星)=1/27,p(期)=1/27,一直算到后面的空为1/27.
于是我们就需要存储我们学习得到的模型参数,一个向量,22维,每个维度保存着每个单词的概率值。
那么有同学就需要问了,来了一句话,我们应该怎么估计呢?
下面我举一个简单的例子来模拟一下如何用语言模型估计一句话的概率,比如:
p(我看看早晨的天空)=p(我)*p(看)*p(看)*p(早)*p(晨)*p(的)*p(天)*p(空)=1/27*1/27*1/27*....*1/27就能够直接运算出来。
于是我们得出,只要将每句话拆开为每个单词然后用累积形式运算,这样我们就能算出每句话的概率来了。
但是这样是不是就解决我们所有的问题呢?并没有,下面我们介绍二元语言模型。
4、二元语言模型
介绍二元语言模型之前,我们首先来看两句话,he eats pizza与he drinks pizza,我们需要用语言模型来判断这两句话出现的概率。
好,那么我们现在用一元语言模型来分别计算这两个句子的概率大小。
p(he eats pizza) = p(he)*p(eats)*p(pizza)
p(he drinks pizza) = p(he)*p(drinks)*p(pizza)
我们可以看出,其实通过一元语言模型的计算公式,我们看不出上面两个句子的概率有多大差别。
但是我们很明显知道第一句话比第二句话的概率要大的多,因为正确的表达应该就是吃披萨,而不是喝披萨。
但是由于我们用了一元语言模型,假设每个词都是条件无关的,这样的话就会导致我们考虑不到两个词之间的关系搭配。
比如在这个例子中,很明显应该判断的是p(pizza|eats)与p(pizza|drinks)的概率大小比较。
这也就是二元语言模型需要考虑的问题。
我们需要计算p(pizza|eats)与p(pizza|drinks)的概率,我们首先给出二元语言模型的定义
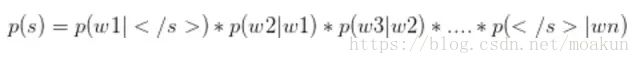
下面我们举出一个例子(例子来源于https://class.coursera.org/nlp/):
这个例子来自大一点的语料库,为了计算对应的二元模型的参数,即P(wi | wi-1),我们要先计数即c(wi-1,wi),然后计数c(wi-1),再用除法可得到这些条件概率。
可以看到对于c(wi-1,wi)来说,wi-1有语料库词典大小(记作|V|)的可能取值,wi也是,所以c(wi-1,wi)要计算的个数有|V|^2。
c(wi-1,wi)计数结果如下:
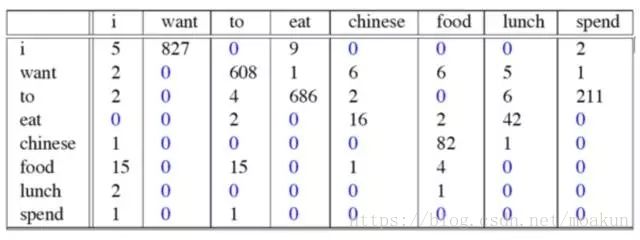
c(wi-1)的计数结果如下:

那么二元模型的参数计算结果如下:

比如计算其中的P(want | i) = 0.33如下:
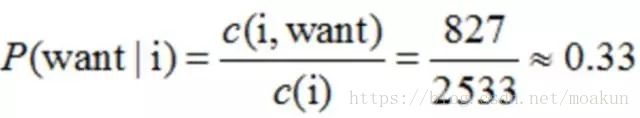
那么针对这个语料库的二元模型建立好了后,我们可以计算我们的目标,即一个句子的概率了,一个例子如下:
P( I want english food ) = P(I|) × P(want|I) × P(english|want) × P(food|english) × P(|food) = 0.000031
那么我们就能通过一个二元语言模型能够计算所需要求的句子概率大小。
二元语言模型也能比一元语言模型能够更好的get到两个词语之间的关系信息。
比如在p(pizza|eats)与p(pizza|drinks)的比较中,二元语言模型就能够更好的get到它们的关系,比如我们再看一下该二元模型所捕捉到的一些实际信息:

图片来自于:http://blog.csdn.net/a635661820/article/details/43906731(图片放大看比较能看清楚红色字)