AI修图!pix2pix网络介绍
语言翻译是大家都知道的应用。但图像作为一种交流媒介,也有很多种表达方式,比如灰度图、彩色图、梯度图甚至人的各种标记等。在这些图像之间的转换称之为图像翻译,是一个图像生成任务。
多年来,这些任务都需要用不同的模型去生成。在GAN出现之后,这些任务一下子都可以用同一种框架来解决。这个算法的名称叫做Pix2Pix,基于对抗神经网络实现。话不多说,先上一张图。
- 将街景标注图像变成真实图像
- 将建筑标注图像转换为真实图像
- 将卫星图像转换为地图
- 将白天的图片转换为夜晚的图像
- 将边缘轮廓线转为真实物体
本文是文献Image-to-image translation with conditional adversarial networks的笔记。
虽然论文是去年11月份的,比较古老,但作为一篇很经典的论文,值得一读。
引入
卷积神经网络, CNN 出现以来,各种图像任务都在飞速的发展。但CNN虽然能够自动学习出一些东西,仍然需要人的指导。设计对的损失函数便是其中的一种方式,对于图像翻译等图像生成任务来说,告诉CNN去学习什么非常的重要。如果告诉CNN去学习一种错误的Loss,那么也不会得到什么好的结果。以欧式距离为例,CNN学习欧氏距离就会得到一张比较模糊的图像。而对于图像翻译任务来说,我们需要让CNN学习能够输出真实的清晰的图像。
pix2pix模型原理
生成网络G
pix2pix网络是GAN网络中的一种,主要是采用cGAN网络的结构,它依然包括了一个生成器和一个判别器。生成器采用的是一个U-net的结构,其结构有点类似Encoder-decoder,总共包含15层,分别有8层卷积层作为encoder,7层反卷积层(关于反卷积层的概念可以参考这篇博客:反卷积原理不可多得的好文)作为decoder,与传统的encoder-decoder不同的是引入了一个叫做“skip-connect”的技巧,即每一层反卷积层的输入都是:前一层的输出+与该层对称的卷积层的输出,从而保证encoder的信息在decoder时可以不断地被重新记忆,使得生成的图像尽可能保留原图像的一些信息。

上图中,首先U-Net也是Encoder-Decoder模型,其次,Encoder和Decoder是对称的。
所谓的U-Net是将第i层拼接到第n-i层,这样做是因为第i层和第n-i层的图像大小是一致的,可以认为他们承载着类似的信息。
判别网络D
对于判别器,pix2pix采用的是一个6层的卷积网络,其思想与传统的判别器类似,只是有以下两点比较特别的地方:
- 将输入图像与目标图像进行堆叠:pix2pix的判别器的输入不仅仅只是真实图像与生成图像,还将输入图像也一起作为输入的一部分,即将输入图像与真实图像、生成图像分别在第3通道进行拼接,然后一起作为输入传入判别器模型。
- 引入PatchGAN的思想:传统的判别器是对一张图像输出一个softmax概率值,而pix2pix的判别器则引入了PatchGAN的思想,将一张图像通过多层卷积层后最终输出了一个比较小的矩阵,比如30*30,然后对每个像素点输出一个softmax概率值,这就相当于对一张输入图像切分为很多小块,对每一小块分别计算一个输出。作者表示引入PatchGAN其实可以起到一种类似计算风格或纹理损失的效果。
其具体的结构如下图所示:

- G目标是生成样本欺骗D
- D的目标是尽可能将真实的样本、G生成的样本分开
损失函数
依上所述,Pix2Pix的损失函数为
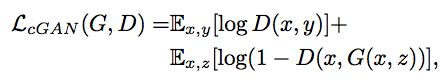
为了做对比,同时再去训练一个普通的GAN,即只让D判断是否为真实图像。
对于图像翻译任务而言,G的输入和输出之间其实共享了很多信息,比如图像上色任务,输入和输出之间就共享了边信息。因而为了保证输入图像和输出图像之间的相似度。还加入了L1 Loss

那么,汇总的损失函数为

训练细节
- 梯度下降,G、D交替训练
- 使用Adam算法训练
- 在inference的时候,与train的时候一样,这和传统CNN不一样,因为传统上inference时dropout的实现与train时不同。
- 在inference的时候,使用test_batch的数据。这也和传统CNN不一样,因为传统做法是使用train set的数据。
- batch_size = 1 or 4,为1时batch normalization 变为instance normalization
实验
评测
使用AMT和FCN-score两种手段来做评测。
- AMT,一种人工评测平台,在amazon上。
- FCN-8,使用预训练好的语义分类器来判断图片的可区分度,这是一种不直接的衡量方式。
Loss function实验
使用三种不同的损失函数,cGAN, L1和cGAN+L1,得到结果如下:
可以看到,只用L1得到模糊图像,只用cGAN得到的会多很多东西。而L1+cGAN会得到较好的结果。
当然普通的GAN损失函数也被尝试。只不过这个损失函数只关注生成的图像是否真实,丝毫不管是否对应。所以训练时间长了以后会导致只输出一个图像。
色彩实验
衡量了不同的损失函数下生成的图像色彩与ground truth的区别。
发现,L1有更窄的色彩区间,表明L1鼓励生成的图像均值化、灰度化。而cGAN会鼓励生成的图像有更多的色彩。
Patch对比
D是基于Patch的,Patch的大小也是一个可以调整的参数。
不同的size产生了不同的结果。1x1的patch就是基于Pixel的D,从结果上看,没带来清晰度的提升,但是却带来了更多的颜色。也证明了上一个实验的结论。
16x16的Patch已经可以达到更好的效果,但是多很多东西(一些乱七八糟的点)。70x70可以消除这些。再变大到286x286,就没有多大的效果提升了。
U-Net
U-Net中使用了skip-connection,而使用与不使用也做了对比实验
可以看到,使用普通的Encoder-Decoder导致了很大的模糊。
效果图
总结
本文将Pix2Pix论文中的所有要点都表述了出来,主要包括:
cGAN,输入为图像而不是随机向量
U-Net,使用skip-connection来共享更多的信息
Pair输入到D来保证映射
Patch-D来降低计算量提升效果
L1损失函数的加入来保证输入和输出之间的一致性。
Reference
[1]. Image-to-image translation with conditional adversarial networks
[2]. 对抗神经网络
[3]. 卷积神经网络