Deep Facial Expression Recogniton: A survey笔记
这篇文章是北邮的邓伟洪教授关于Deep Facial Expression Recognition,DFER的一篇综述性文章,该文章被计算机视觉顶会CVPR收录。
目前,FER(Facial Expression Recogniton)主要存在两个问题:一个就是缺少大量的数据来训练表情识别网络,一旦网络训练数据量过少,就会发生过拟合的现象,这点目前还没有有效的解决办法;另一个问题就是由于年龄、性别、道德背景等的差异,导致个体间的差异比较明显。除此之外,光照和姿态也会对FER产生较大的影响。
这篇文章详细介绍了解决FER目前存在的问题的一些方法。其中文章section1介绍了FER的发展历程,section2介绍了FER实验常用的数据集,section3介绍了FER系统识别的三个主要步骤,section4提供了一些主流的网络架构以及训练技巧,section5则讨论了一些其他相关的问题,section6主要论述了一下FER未来的挑战和机遇。下面以章节划分逐一介绍。
section2 FACIAL EXPRESSION DATABASES
该部分列举了FER可用的数据库。
主要有CK+、MMI、JAFFE、TED、FER2013、AFEW、SFEW、Multi-PIE、BU-3DFE、Oulu-CASIA、RaFD、KDEF、EmotionNet、RAF-DB、AffectNet、ExpW这些数据库。
section3 DEEP FACIAL EXPRESSION RECOGNITION
deep FER主要有三个步骤,预处理、特征学习、特征分类。
预处理
由于背景、光照、姿态等非相关因素的影响,在训练网络之前,需要进行一定的预处理,主要有人脸对齐和标准化。
Face alignment
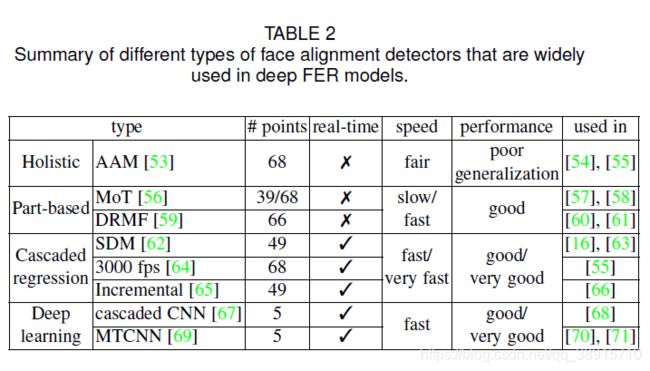
表格2列举了deep FER中广泛使用的人脸关键点检测算法,并对其效率和性能作了比较。其中MTCNN取得了最好的效果。
Data augmentation
深度神经网络需要大量的训练数据来提高网络的泛化能力。但是目前并没有足够的数据用于FER神经网络的训练。因此,数据增强对于deep FER成了至关重要的一步。数据增强一般可分为两类:在线数据增强和离线数据增强。
深度学习库一般包含在线数据增强,以减轻过拟合。常用的有裁剪,水平翻转。
离线数据增强常用的有随机扰动,图像变换(旋转、平移、翻转、缩放和对齐),添加噪声(椒盐噪声和斑点噪声),以及调整亮度和饱和度,以及在眼睛之间添加2维高斯分布的噪声,以及GAN网络生成人脸。
Face normalization
光照和头部姿态的变化会引起图像的巨大变化,从而影响FER的性能。因此,我们引入了两种典型的人脸归一化方法来改善这些变化:光照归一化和姿态归一化(正面化)。
光照归一化除了直观的调整亮度以外,还有对比度调整。常见的对比度调整方法有直方图归一化、DCT归一化、Dog归一化。同时相关研究表明,直方图均衡化和光照归一化相结合的人脸识别性能优于单独使用光照归一化的人脸识别性能。
姿态归一化在非限制性环境下是常见且难以对付的问题。常见的解决方法有2D的landmark对齐,3Dlandmark对齐。比较新的模型都是基于GAN的,有FF-GAN、TP-GAN和DR-GAN
基于深度网络的特征学习
深度学习最近成为一个热门的研究课题,并在各种应用中取得了最先进的性能。深度学习试图通过多重非线性转换和表示的层次结构捕获高级抽象。在本节中,简要介绍了一些应用于FER的深度学习技术。这些深度神经网络的传统结构如图2所示。
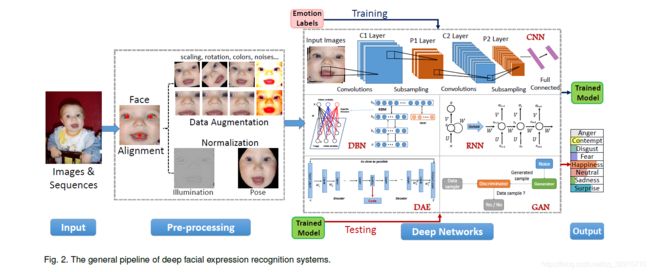
图二显示了目前FER系统的普遍流程。
主要应用的深度网络有CNN、DBN、DAE、RNN、GAN
Facial expression classification
在学习了人脸的深层特征后,FER的最后一步是将人脸分类为基本的情感类别之一.
与传统的特征提取步骤和特征分类步骤相互独立的方法不同,深度网络可以端到端执行FER。具体地说,在网络的末端利用损失来进行误差反向传播;然后,网络可以直接输出每个样本的预测概率。在CNN中,softmax loss是最常用的函数,它最小化了估计类概率与groundtruth分布之间的交叉熵损失。另外,证明了使用线性支持向量机(SVM)进行端到端训练的好处,该方法最大限度地减少了基于边缘的损失,而不是交叉熵。同样,研究了深层神经森林(NFs)的适应性,该神经森林用NFs取代了softmax loss layer,并为FER取得了良好的结果。
section4 THE STATE OF THE ART
在这一节中,我们回顾了现有的为FER设计的新型深度神经网络,以及为解决特定表达问题而提出的相关训练策略。根据数据类型的不同,我们将文献中的工作分为两大类:静态图像的深FER网络和动态图像序列的深FER网络。然后,我们就网络体系结构和性能方面对当前的深度FER系统进行了概述。由于部分被评估的数据集没有提供明确的数据组用于训练、验证和测试,相关研究可能会在不同的实验条件下使用不同的数据进行实验,因此我们总结了表达识别性能以及数据选择和分组方法的信息。
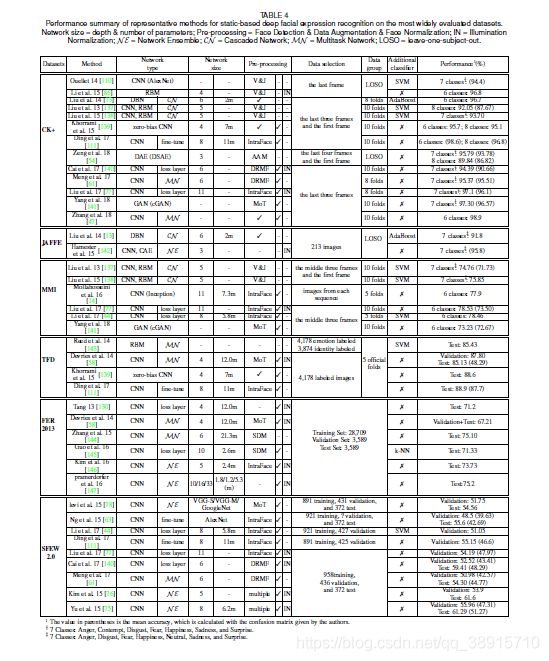
对于每一个最频繁评估的数据集,表4显示了该领域中目前最先进的方法,这些方法显式地在独立于人的协议中执行(培训集和测试集中的对象是分开的)。
本节中列举的常用方法有Pre-training and fine-tuning、Diverse network input、Auxiliary blocks&layers、Network ensemble、Muitisask networks、Cascaded networks、Generative adversarial networks.
Deep FER networks for dynamic image sequences
以往的人脸识别模型大多侧重于静态图像,但人脸表情识别可以从序列中连续帧的时间相关性中获益。我们首先介绍现有的帧聚合技术,这些技术战略性地结合了从基于静态的FER网络中学习到的深层特性。然后,考虑到在视频流中人们通常以不同的强度显示相同的表达式,我们进一步回顾了在不同的表达强度状态下使用图像进行强度不变FER的方法。最后,我们介绍了考虑视频帧时空运动模式的深度FER网络,以及从时间结构中获得的特征。对于每个最频繁评估的数据集,表7显示了当前在独立于人的协议中执行的最先进的方法。
Frame aggression
由于给定视频剪辑中的帧可能在表达强度上有所不同,直接测量每帧的误差并不能获得令人满意的性能。为了提高网络的性能,提出了各种方法来聚合每个序列帧的网络输出。我们将这些方法分为两组:决策级框架聚合和特征级框架聚合.
我们考虑了两种聚合方法来为每个序列生成固定长度的特征向量:帧平均和帧扩展。另一种不需要固定帧数的方法是应用统计编码。平均、最大值、平方的平均值、最大抑制向量的平均值等可用于总结每个序列的每帧概率。对于特征级帧聚合,序列中帧的学习特征是聚合的。该方案可以应用多种基于统计的编码模块。一种简单有效的方法是将所有帧的特征的均值、方差、最小值和最大值串联起来。另外,基于矩阵的模型如特征向量、协方差矩阵和多维高斯分布也可以用于聚集。此外,还探索了视频级表示的多实例学习,利用辅助图像数据计算聚类中心,得到每个视频帧包的单词表示。
Expression intensity network
大多数方法关注于识别峰值高强度表情,而忽略了细微的低强度表达式,在这个部分引入了表情强度不变网络,它从强度变化的序列中,以不同强度的训练样本作为输入去利用表达式之间的内在相关性。
在表情强度不变的网络中,采取带有强度标签的图片帧进行训练。在测试期间,表情强度改变的数据用于检验网络强度不变的能力。
Deep spatio-temporal FER network
虽然帧聚合可以将帧集成到视频序列中,但是关键的时间依赖性并没有被显式地利用。相比之下,时空FER网络在不事先知道表达强度的情况下,将时间窗口中的一系列帧作为单个输入,并利用纹理和时间信息对更细微的表达进行编码。
RNN利用连续数据的特征向量在语义上是连通的,因此是相互依赖的,从而能从序列中鲁棒地提取信息。它的升级版本,LSTM,能够灵活地处理变长序列数据,且计算量小。
相关的心理学研究表明,表情是由某些面部部位(如眼睛、鼻子和嘴巴)的动态运动所激发的,这些部位包含了表达表情的最具描述性的信息。为了获得更精确的人脸运动,提出了一种基于连续帧的人脸地标轨迹模型。
ADDITIONAL RELATED ISSUES
除了上述最受欢迎的基本表情分类任务外,我们还进一步介绍了一些依赖于深层神经网络和典型表情相关知识的相关问题。
Occlusion and non-frontal head pose(遮挡和非正面头部姿势)
遮挡和非正面的头部姿态可能改变原始面部表情的视觉外观,是自动FER的两个主要障碍,尤其是在真实场景中。