目标检测(YOLO,SSD,Efficientdet,RCNN系列)
文章目录
- 前言
- 一、YOLO 系列
- 1.1 yolo v3
- yolo v3 网络
- yolo v3 预测流程
- yolo v3 训练流程(暂时没梳理出来)
- 1.2 yolo v4
- 二、SSD 系列
- SSD网络
- SSD预测流程
- SSD训练流程
- SSD GitHub源码
- 三、Retinanet(后面更新)
- 四、Efficientdet(后面更新)
- 五、RCNN 系列
- 5.1 Faster R-CNN
- Faster R-CNN 网络
- Faster R-CNN 预测
- Faster R-CNN 源码
- 5.2 Mask R-CNN
- Mask R-CNN 网络
- Mask R-CNN 预测
- Mask R-CNN 训练
- 5.3 Cascade R-CNN
- 5.4 Keypoint R-CNN
前言
目标检测现在已经发展有几年了,自己接触目标检测网络也有很长一段时间了,现在就在这里总结一下我所使用过的目标检测的网络模型,以及他们的优缺点。
一、YOLO 系列
YOLO系列到现在为止已经更新到YOLO V4(V5应该不算吧?)。由于YOLO系列都是一步步升级而来,所以本文直接从V3、V4开始介绍。
1.1 yolo v3
yolo v3 网络
Yolov3是2018年发明提出的,这成为了目标检测one-stage中非常经典的算法,包含Darknet-53网络结构、anchor锚框、FPN等非常优秀的结构。

Yolo的整个网络,吸取了Resnet、Densenet、FPN的精髓,可以说是融合了目标检测当前业界最有效的全部技巧(YOLO V4没出来以前)
-
Yolov3中,只有卷积层,通过调节卷积步长控制输出特征图的尺寸。所以对于输入图片尺寸没有特别限制。流程图中,输入图片以416x416作为样例。
-
Yolov3借鉴了金字塔特征图思想,小尺寸特征图用于检测大尺寸物体,而大尺寸特征图检测小尺寸物体。特征图的输出维度为N x N x[3x (4+ 1+80)],N x N为输出特征图格点数,一共3个Anchor框,每个框有4维预测框数值tr,ty,tw,th , 1维预测框置信度, 80维物体类别数(COCO数据集)。所以第一层特 征图的输出维度为13 x 13 x 255。
-
Yolov3总共输出3个特征图,第一个特征图下采样32倍 ,第二个特征图下采样16倍 ,第3个下采样8倍。输入图像经过Darknet53 (无全连接层),再经过Yoloblock生成的特 征图被当作两用,第一用为经过3 x 3卷积层、1 x 1卷积之后生成特征图一 ,第二用为经过1 x 1卷积层加上采样层,与DarkNet53网络的中间层输出结果进行拼接,产生特征图二。同样的循环之后产生特征图三。
-
concat操作与加和操作的区别:加和操作来源于ResNet思想,将输入的特征图,与输出特征图对应维度进行相加,即y= f(x) + x ; 而concat操作源于DenseNet网络的设计思路,将特征图按照通道维度直接进行拼接,例如8 x 8 x 16的特征图与8 x 8 x 16的特征图拼接后生成8 x 8 x 32的特征图。
-
上采样层(upsample):作用是将小尺寸特征图通过插值等方法,生成大尺寸图像。例如使用最近邻插值算法,将13 x 13的图像变换为26 x 26。上采样层不改变特征图的通道数。
其实际情况就是,由于我们使用得是Pytorch,它的通道数默认在第一位,输入N张416x416的图片,在经过多层的运算后,会输出三个shape分别为(N,255,13,13),(N,255,26,26),(N,255,52,52)的数据,对应每个图分为13x13、26x26、52x52的网格上3个先验框的位置。
yolo v3 预测流程


yolo v3 训练流程(暂时没梳理出来)
1.2 yolo v4
YOLOV4是YOLOV3的改进版,在YOLOV3的基础上结合了非常多的小Tricks。尽管没有目标检测上革命性的改变,但是YOLOV4依然很好的结合了速度与精度。YOLOV4在YOLOV3的基础上,在FPS不下降的情况下,mAP达到了44,提高非常明显。

主干提取网络

YOLOV4改进的部分(不完全)
-
主干特征提取网络:DarkNet53 => CSPDarkNet53
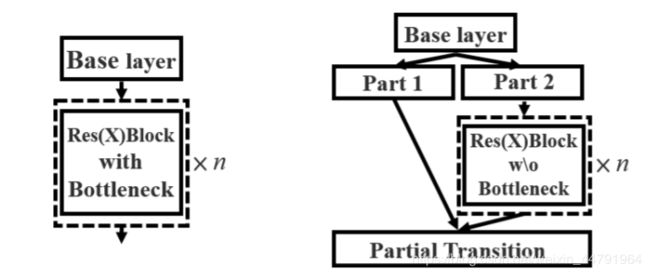
CSPnet结构并不算复杂,就是将原来的残差块的堆叠进行了一个拆分,拆成左右两部分:主干部分继续进行原来的残差块的堆叠;另一部分则像一个残差边一样,经过少量处理直接连接到最后。因此可以认为CSP中存在一个大的残差边。 -
特征金字塔:SPP,PAN:
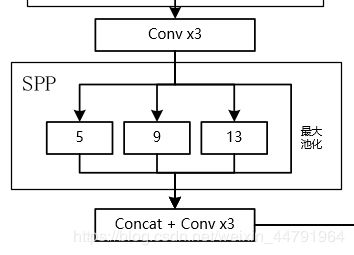
SPP结构参杂在对CSPdarknet53的最后一个特征层的卷积里,在对CSPdarknet53的最后一个特征层进行三次DarknetConv2D_BN_Leaky卷积后,分别利用四个不同尺度的最大池化进行处理,最大池化的池化核大小分别为13x13、9x9、5x5、1x1(1x1即无处理)。它能够极大地增加感受野,分离出最显著的上下文特征。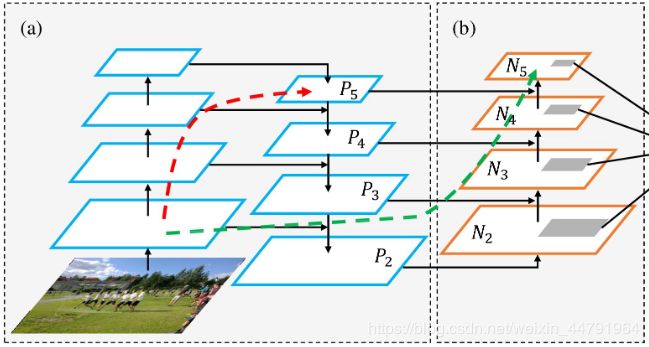
PANet是2018的一种实例分割算法,其具体结构由反复提升特征的意思。上图为原始的PANet的结构,可以看出来其具有一个非常重要的特点就是特征的反复提取。在(a)里面是传统的特征金字塔结构,在完成特征金字塔从下到上的特征提取后,还需要实现(b)中从上到下的特征提取。
-
分类回归层:YOLOv3(未改变)
-
激活函数:由LeakyReLU修改成了Mish,卷积块由DarknetConv2D_BN_Leaky变成了DarknetConv2D_BN_Mish。
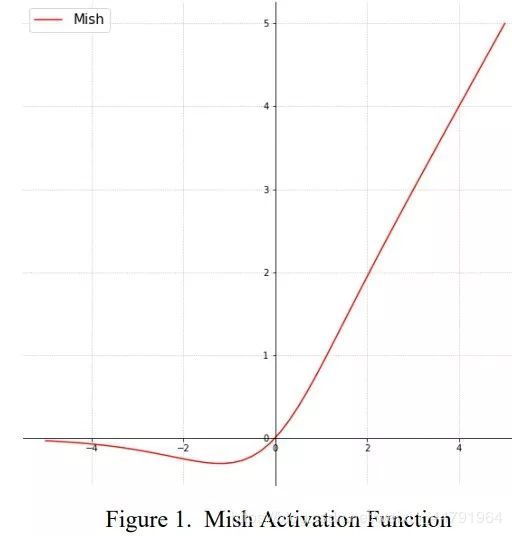
-
训练用到的小技巧:CutMix和Mosaic数据增强、DropBlock正则化、Label Smoothing平滑、CIoU-loss、学习率余弦退火衰减
二、SSD 系列
SSD网络
SSD是一种非常优秀的one-stage目标检测方法,one-stage算法就是目标检测和分类是同时完成的,其主要思路是利用CNN提取特征后,均匀地在图片的不同位置进行密集抽样,抽样时可以采用不同尺度和长宽比,物体分类与预测框的回归同时进行,整个过程只需要一步,所以其优势是速度快。但是均匀的密集采样的一个重要缺点是训练比较困难,这主要是因为正样本与负样本(背景)极其不均衡,导致模型准确度稍低。
SSD采用的主干网络是VGG网络:

这里的VGG网络相比普通的VGG网络有一定的修改,主要修改的地方就是:
- 将VGG16的FC6和FC7层转化为卷积层。
- 去掉所有的Dropout层和FC8层;
- 新增了Conv6、Conv7、Conv8、Conv9。

由上图我们可以知道,SSD网络的输入一般是 300x300x3的原始图片矩阵、n个坐标标签和n个分类标签,其中n代表每幅图中目标物体的个数。其特征提取网络直接由卷积网络得到最终的预测值,共使用了6种不同尺寸的特征图:38x38、19x19、10x10、5x5、3x3、1x1,最终得到8732个预测框。
其中:
num_priors x 4的卷积 用于预测 该特征层上 每一个网格点上 每一个先验框的变化情况。(为什么说是变化情况呢,这是因为ssd的预测结果需要结合先验框获得预测框,预测结果就是先验框的变化情况。)num_priors x num_classes的卷积 用于预测 该特征层上 每一个网格点上 每一个预测框对应的种类。每一个有效特征层对应的先验框对应着该特征层上 每一个网格点上 预先设定好的多个框。
所有的特征层对应的预测结果的shape如下:
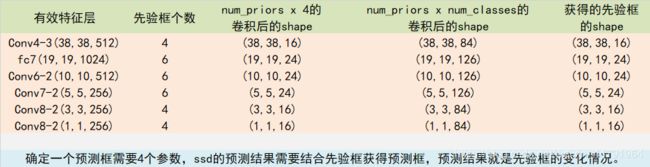
SSD预测流程
- 准备数据(图片,视频,摄像头)
- 数据处理(300x300x3或512x512x3 , 归一化)
- 数据输入至SSD网络,输出:

所有先验框对应预测框的分类得分pred_cls(feat_size,feat_size,num_anchors,num_classes)
所有先验框的位置信息pre_locs(feat_size,feat_size,num_anchors,loc_offsets) - 得到先验框 anchor_layers : 每一种 feat_size 上,在每个位置都生成数量为 num_anchors 的先验框,先验框的表示为 (x,y,w,h)。
- 解码过程Decode:将网络输出 pred_locs 和 anchors 结合起来,得到真实值。
- 先对每一类得分大于threshold的框和得分取出来,利用非极大值抑制(NMS)得到结果(200个),再利用框的位置和得分进行非极大抑制得到最终结果。
- 将结果resize到原图,可视化最终结果。
SSD训练流程
从预测部分我们知道,每个特征层的预测结果,用于预测 该特征层上 每一个网格点上 每一个先验框的变化情况。也就是说,我们直接利用SSD网络预测到的结果,并不是预测框在图片上的真实位置,需要解码才能得到真实位置。
而在训练的时候,我们需要计算loss函数,这个loss函数是相对于SSD网络的预测结果的。我们需要把图片输入到当前的SSD网络中,得到预测结果;同时还需要把真实框的信息,进行编码,这个编码是把真实框的位置信息格式转化为SSD预测结果的格式信息。
也就是,我们需要找到 每一张用于训练的图片的每一个真实框对应的先验框,并求出如果想要得到这样一个真实框,我们的预测结果应该是怎么样的。从预测结果获得真实框的过程被称作解码,而从真实框获得预测结果的过程就是编码的过程。
-
准备数据(labelme或labelimg):
image/labels/bboxes(每张图至少有一个检测目标,有几个检测目标对应几个 label 和 bbox ) -
加载数据以及数据预处理
-
搭建SSD网络结构
-
网络结构输出:
- 网络输出 (要注意的是: locs 对应的四个值是dx/dy/dw/dh)
pred_cls(feat_size,feat_size,num_anchors,num_classes)
pre_locs(feat_size,feat_size,num_anchors,loc_offsets) - 先验框 anchor_layers : 每一种 feat_size 上,在每个位置都生成数量为 num_anchors 的先验框,先验框的表示为 (x,y,w,h)
- 网络输出 (要注意的是: locs 对应的四个值是dx/dy/dw/dh)
-
groundtruth 与 anchors 之间的 encode:
在训练过程中,groundtruth 的坐标形式是(y1,x1,y2,x2),而网络输出的坐标形式是(dx,dy,dw,dh),两者之间的表示形式不同,因此要将 groundtruth 和 anchors 结合,来表示anchor_layers 上每个位置的分类 label 和坐标偏移 loc(即网络的输出),即 encode 过程:
- 得到每个anchor的(左上,右下)坐标
- 得到每个anchor的分类和偏移(计算 groundtruth_bboxes 与 每个anchors 的 IOU,作为 scores。每个 anchor 取与其IOU最大的groundtruth_bbox作为基准来计算偏移。)
- 将坐标形式转换成偏移量的形式(与网络的输出 pred_locs 计算损失,坐标形式为(dx,dy,dw,dh))
-
计算损失:经过上一步,groundtruth 已经和 pred_locs 的形式相同,可以用 smoth_L1 loss 计算坐标偏移之间的损失。分类损失分为 pos_cross_entropy 和 neg_cross_entropy ,正负样本数目为 1:3。
SSD GitHub源码
GitHub源码
三、Retinanet(后面更新)
四、Efficientdet(后面更新)
五、RCNN 系列
这里不会讨论任何关于R-CNN家族的历史,分析清楚最新的Faster R-CNN就够了,并不需要追溯到那么久。实话说我也不了解R-CNN,更不关心。有空不如看看新算法。
5.1 Faster R-CNN
Faster R-CNN 网络

Faster R-CNN 预测
-
输入图片,获取图片的W,H,C(例如L:3X1024X1024)
-
数据处理,图片resize到3X600X600
-
Resnet_50网络进行特征提取得到feature_map(512X37X37)
-
RPN网络处理,该网络用于生成region proposals。该层通过softmax判断anchors属于positive或者negative,再利用bounding box regression修正anchors获得精确的proposals。

softmax:512X37X37----->18X37X37----->reshape----->2X333(9X37)X37----->softmax----->2X333X37----->reshape-----18X3737bbox-reg:512X37X37----->36X37X37proposals:Anchor生成----->回归偏移调整Anchor---->分类得分排序筛选12000个Anchor----->NMS----->再选2000个Anchor----->IOU得出256个ROI
-
Roi Pooling。该层收集输入的feature maps和proposals,综合这些信息后提取proposal feature maps,送入后续全连接层判定目标类别。256个RoI经过池化之后得到固定维度为512×7×7的特征。
-
Classification。利用proposal feature maps计算proposal的类别,同时再次bounding box regression获得检测框最终的精确位置。

注:为了输出类别与回归的预测,将上述特征分别接入分类与回归的全连接网络。在此默认为21类物体,因此分类网络输出维度为21,回归网络则输出每一个类别下的4个位置偏移量,因此输出维度为84。
-
将结果resize到原图,可视化最终结果。
Faster R-CNN 源码
GitHub源码
5.2 Mask R-CNN
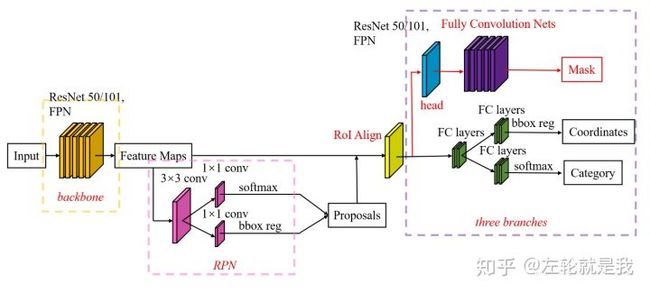
基于Faster RCNN,何凯明进一步提出了新的实例分割网络Mask RCNN,该方法在高效地完成物体检测的同时也实现了高质量的实例分割,获得了ICCV 2017的最佳论文。
Mask R-CNN 网络
Mask RCNN的网络结构如图所示,可以看到其结构与FasterRCNN非常类似,但有3点主要区别:
- 在基础网络中采用了较为优秀的ResNet-FPN结构,多层特征图有利于多尺度物体及小物体的检测。
- 提出了RoI Align方法来替代RoI Pooling,原因是RoI Pooling的取整做法损失了一些精度,而这对于分割任务来说较为致命。
- 得到感兴趣区域的特征后,在原来分类与回归的基础上,增加了一个Mask分支来预测每一个像素的类别。