Day2 《青春有你2》Python 爬虫 和人像动漫体验
前言
爬取《青春有你2》小MM是第二天训练训练营的任务。之前也没有写过爬虫,滚摸爬了一个下午,非常感谢群里小伙伴的解疑。另外体验了一番 调用百度产品接口- 人像动漫化,感觉十分有趣。整体来说这天百度训练营的学习内容还是趣味挺足。在下面一一分享给大家
1. 《青春有你》
这天的学习作业是爬取《青春有你》女神照片。:数据获取:https://baike.baidu.com/item/青春有你第二季
基本原理
- 上网全过程
打开浏览器→往目标站点发送请求 → 接收响应数据 → 渲染到页面上 - 爬虫程序:
模拟浏览器 → 往目标站点发送请求 → 接收响应数据 → 提取有用的数据 → 保存到本地/数据库 - 爬虫过程:
- 发送请求(requests 模块) requests.get(url) 发送一个http get 请求,返回服务器响应内容
- 获取响应数据(服务器返回)
- 解析并提取数据(beautifulSoup 查找或是正则)
- 保存数据
- 分析过程
进入网址后选择开发者模式(这里用的是chrome浏览器)选择右上方的箭头然后点击“参赛学员”的位置,观察右方对应位置的代码部分。每一位选手的名字都有对应个人网站。
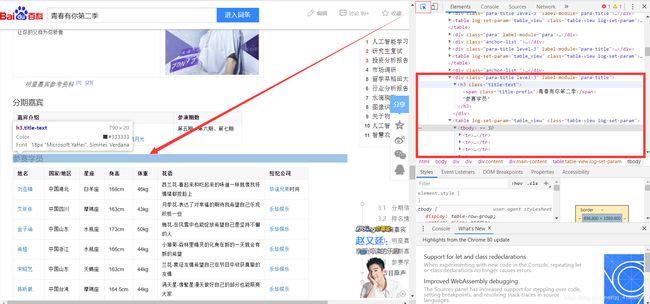
点击名字,还是选择“开发者模式”,点击右上方的箭头,鼠标放在图册的位置,观察右方对应位置的代码部分。当然,我们也并不是需要爬取封面的图片,而是爬取图册里的所有图片。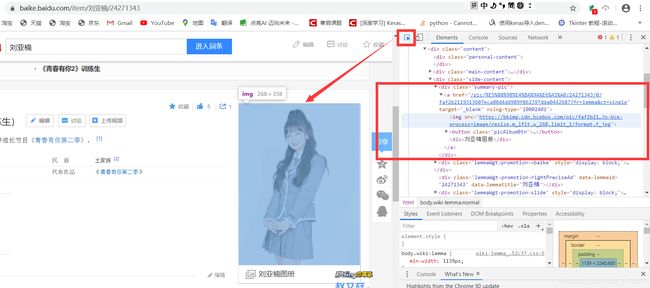
显然在pic-list里面包括图册里的所有图片获取的信息。

经过上面的简单分析,获取img的src网站信息就可以下载对应的图片。需要request 3次。
- 进入学员的百科页
- 进入学员个人百科页
- 进入学员图册
实践
- 首先导入必要库(没有可以pip 下载)
import json
import re
import requests
import datetime
from bs4 import BeautifulSoup
import os
#获取当天日期并进行格式化,用于后面文件命名
today=datetime.date.today().strftime('%Y%m%d')
用到两个基本模块
request模块:
requests.get(url)可以发送一个http get请求,返回服务器响应内容。
BeautifulSoup库:
BeautifulSoup 是一个可以从HTML或XML文件中提取数据的Python库。网址:https://beautifulsoup.readthedocs.io/zh_CN/v4.4.0
BeautifulSoup(markup, "html.parser")或者BeautifulSoup(markup, "lxml"),推荐使用lxml作为解析器,因为效率更高。
- 爬取参赛选手信息,返回页面数据
def crawl_wiki_data():
"""爬取百度百科中《青春有你2》中所有参赛选手信息,返回页面数据"""
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'
} #模拟浏览器
url='https://baike.baidu.com/item/青春有你第二季'#爬取的网站
try:
response=requests.get(url=url,headers=headers)
print(response.status_code)#节点状态#
#将一段文档传入beatifulSoup的构造方法,得到一个文件对象,可以传入一段字符串
soup=BeautifulSoup(response.text,'lxml')#lxml 解析器
#返回的是class为table-view log-set-param的所有标签
tables=soup.find_all('table',{'class':'table-view log-set-param'})
crawl_table_title="参赛学员"
for table in tables:
#对当前节点前面的标签和字符串进行查找
table_titles=table.find_previous('div').find_all('h3')#[青春有你第二季明星嘉宾
]
#找前一个节点
for title in table_titles:
if (crawl_table_title in title):
return table
except Exception as e:
print(e)
- 解析页面数据,保存为json文件
def parse_wiki_data(table_html):
"""解析页面数据,并保存为JSON文件"""
bs = BeautifulSoup(str(table_html), 'lxml')
all_trs = bs.find_all('tr')#是个列表
error_list = ['\'', '\"']
stars = []
for tr in all_trs[1:]:
all_tds = tr.find_all('td')
star = {}
# 姓名
star["name"] = all_tds[0].text
# 个人百度百科链接
star["link"] = 'https://baike.baidu.com' + all_tds[0].find('a').get('href')
# 籍贯
star["zone"] = all_tds[1].text
# 星座
star["constellation"] = all_tds[2].text
# 身高
star["height"] = all_tds[3].text
# 体重
star["weight"] = all_tds[4].text
# 花语,去除掉花语中的单引号或双引号
flower_word = all_tds[5].text
for c in flower_word:
if c in error_list:
flower_word = flower_word.replace(c, '')
star["flower_word"] = flower_word
# 公司
if not all_tds[6].find('a') is None:
star["company"] = all_tds[6].find('a').text #有些公司有链接
else:
star["company"] = all_tds[6].text
stars.append(star)
json_data = json.loads(str(stars).replace("\'", "\""))
with open(today + '.json', 'w', encoding='UTF-8') as f:
json.dump(json_data, f, ensure_ascii=False) #不是以ascii码取存储的
- 爬取图片并保存
一开始直接获取img src 作为url 爬取的多半是缩略图(尺寸,质量肯定没有原图这么好),作为新手的一个小坑吧(┭┮﹏┭┮,也是试过了才知道)。建议是来自群里的一个伙伴提供的一个解决方法。
def crawl_pic_urls():
"""爬取每个选手的百度百科图片并保存"""
with open(today+".json",'r',encoding='UTF-8') as file:
json_array=json.loads(file.read())
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'
}#模拟浏览器, 浏览器信息
for star in json_array:
name=star['name']
link=star['link']#获取每位明星的链接 url
# try:
response=requests.get(url=link,headers=headers) #第二次
soup=BeautifulSoup(response.text,'lxml')#获得文件对象
content=soup.find_all('div',{'class':'summary-pic'})#'side-content'
href="https://baike.baidu.com"+content[0].find('a').get('href') #这里用find 因为当是一个单独的对象的时候应该使用find
response2=requests.get(url=href,headers=headers) #第三次
child_soup=BeautifulSoup(response2.text,'lxml')#获得文件对象
pic_urls=[]
pic_lists=child_soup.find_all('a',{"class":"pic-item"})#'pic-item'
if pic_lists!=[]:#find_all() 方法没有找到目标是返回空列表, find() 方法找不到目标时,返回 None .
for pic in pic_lists:
try:
pic_urls.append(pic.find('img').get('src').split("?")[0]) #解决的方法是在这里实现的
except AttributeError:
print(name)
continue
if pic_urls!=[]:
down_pic(name,pic_urls)
解决思路:去掉把“?”号后面内容就可以啦~

- 下载图片
def down_pic(name,pic_urls):
"""根据图片链接列表pic_urls ,pic_urls 是一个列表"""
path=os.path.join(os.getcwd(),'pics/'+name+'/')
if not os.path.exists(path):
os.makedirs(path)
for i ,pic_url in enumerate(pic_urls):
try:
pic=requests.get(pic_url,timeout=15)
string=str(i+1)+'.jpg'
with open(path+string,'wb')as f:
f.write(pic.content)
print("成功下载第%s张图片:%s"%(str(i+1),str(pic_url)))
except Exception as e:
print('下载第%s张图片时失败:%s'%(str(i+1),str(pic_url)))
print(e)
continue
- 显示信息
def show_pic_path(path):
"""遍历爬取的每张图片,并打印所图片的绝对路径"""
pic_num=0
for (dirpath,dirnames,filenames) in os.walk(path):
for filename in filenames:
pic_num+=1
print("第%d张图片:%s"%(pic_num,os.path.join(dirpath,filename)))
print("共爬取《青春有你2》选手的%d照片"%pic_num)
- 代码执行
if __name__=='__main__':
#爬取百度百科中参赛选手信息,并返回html
html=crawl_wiki_data()
# 解析html数据保存为json文件
parse_wiki_data(html)
crawl_pic_urls()
# 从每个选手的百度百科页面上爬取图片,并保存
crawl_pic_urls()
# 打印所爬取的选手图片路径
show_pic_path(os.path.join(os.getcwd(),'pics'))
print("所有信息爬取完成!")
最终结果

2. 接口调用:人物动漫化
这部分分享如何用python调用接口,还是挺有趣的体验(其他语言可以看官方API文档)大家有空尝试下:https://cloud.baidu.com/doc/IMAGEPROCESS/s/Mk4i6olx5#%E8%BF%94%E5%9B%9E%E8%AF%B4%E6%98%8E

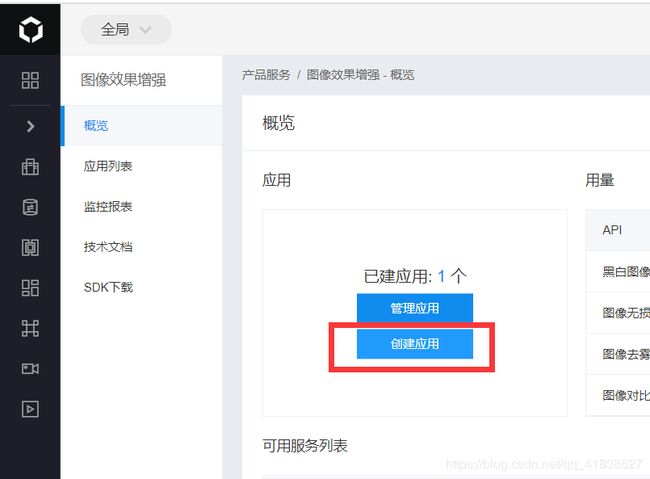
- 登录账号,选择创建应用,吧啦吧啦填好一些内容就可以了。
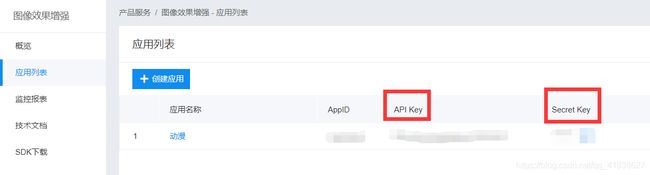
- 应用列表,API key 和Secrent Key 都是一会要用到的
- 获取Access Token ,替换代码 【APIKey】【Secret Key】,复制 ‘access_token’ 对应的内容
import requests
import base64
host = 'https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id=【APIkey】&【Secret Key】'
response = requests.get(host)
if response:
print(response.json())
- 调用接口,返回数据
request_url = "https://aip.baidubce.com/rest/2.0/imageprocess/v1/selfie_anime"
# 二进制方式打开图片文件
f = open('xxx.jpg', 'rb') #图片路径
img = base64.b64encode(f.read())
params = {"image":img}
access_token = 【access_token】#将之前输出内容复制在上面
request_url = request_url + "?access_token=" + access_token
headers = {'content-type': 'application/x-www-form-urlencoded'}
response = requests.post(request_url, data=params, headers=headers)
if response:
print (response.json())
- 转化数据并保存
#输出内容
# info={'log_id': 6796446859332290391,
# 'image': base64编码数据}
img=base64.b64decode(info['image'])
file=open('125.jpg','wb') #自己起名字
file.write(img)
file.close()
效果还是挺有趣(●ˇ∀ˇ●),唯一不足的嘛,感觉测试女生比男生好点(吐槽一点放了男神的图片,就是没有真人那么英俊的啦,害;我觉得眼睛好看点就没啥哈哈 O(∩_∩)O ),

分享就这样,明天继续加油(万年懒虫捡起的第一篇blog)