机器学习实战——第七章(分类):利用AdaBoost元算法提升分类器性能
前言
接着上一篇继续学习。
首先感谢博主:Jack-Cui
主页:http://blog.csdn.net/c406495762
AdaBoost博文地址:https://blog.csdn.net/c406495762/article/details/78212124
这篇博文对书上的内容很形象的进行了表达,通俗易懂,用自己的实例来进行讲解,比书上讲的清楚太多,于是我才开始了学习,感激不尽,真心推荐。
我这篇博文大多从它的博文中摘抄,但也是我一个字一个敲出来的,算法我也是自己算过的,算是学完它的博文的一个总结吧,如果还看不明白的可以直接看他的吧。
明天我会继续按照它的博客学习。
进入正题。
提升分类器性能利器-AdaBoost
前面已经介绍了五种不同的分类器,我们可以很自然地将不同的分类器组合起来,而这种组合结果则被称为集成方法或者元算法。使用集成方法时会有多种形式:可以是不同算法的集成,也可以是同一种算法在不同设置下的集成,还可以是数据集不同部分分配给不同分类器之后的集成。
集成方法
集成方法通过组合多个学习器来完成学习任务。
基分类器一般采用的是弱可学习分类器,通过集成方法,组合成一个强可学习分类器。
-
弱可学习分类器就是学习之后分类器的正确率很低,略优于猜的正确率。
-
强可学习分类器是指学习之后分类器的正确率较高。
集成方法主要包括Bagging和Boosting两种方法,Bagging和Boosting都是将已有的分类或回归算法通过一定方式组合起来,形成一个性能更加强大的分类器,更准确的说这是一种分类算法的组装方法,即将弱分类器组装成强分类器的方法。
Bagging
自举汇聚法,即有放回地采样数据。
从原始样本数据集中每轮抽取n个训练样本(随机抽取,抽完放回去,所以下次还可能抽同样的,而且也可能有一次都没被抽过的),抽k轮,得到了k个训练集(相互独立的)。
然后给k个分类器(分类算法不确定),每次使用一个训练集得到一个模型,k个训练集就是k个模型。
分类问题:采用投票的方式对k个模型得到分类结果。
回归问题:就计算上述模型的均值作为最后结果。
Boosting
boosting:重赋权法迭代地训练基分类器。
对每一轮的训练数据赋予一个权重,并且每一轮样本的权重值分布依赖于上一轮的分类结果。基分类器之间采用序列式的线性加权方式进行组合。
Bagging、Boosting二者之间的区别
样本选择上:
Bagging:训练集是在原始集中有放回选取的,从原始集中选出的各轮训练集之间是独立的。
Boosting:每一轮的训练集不变,只是训练集中每个样例在分类器中的权重发生变化。而权值是根据上一轮的分类结果进行调整。
样例权重:
Bagging:使用均匀取样,每个样例的权重相等。
Boosting:根据错误率不断调整样例的权值,错误率越大则权重越大。
预测函数:
Bagging:所有预测函数的权重相等。
Boosting:每个弱分类器都有相应的权重,对于分类误差小的分类器会有更大的权重。
并行计算:
Bagging:各个预测函数可以并行生成。
Boosting:各个预测函数只能顺序生成,因为后一个模型参数需要前一轮模型的结果。
总结
这两种方法都是把若干个分类器整合为一个分类器的方法,只是整合的方式不一样,最终得到不一样的效果,将不同的分类算法套入到此类算法框架中一定程度上提高了原单一分类器的分类效果,但是也增大了计算量。
下面是将决策树与这些算法框架进行结合所得到的新的算法:
- Bagging + 决策树 = 随机森林
- AdaBoost + 决策树 = 提升树
- Gradient Boosting + 决策树 = GBDT
集成方法众多,主要关注Boosting方法中的一种最流行的版本,即AdaBoost。
AdaBoost
AdaBoost算法是基于Boosting思想的机器学习算法,AdaBoost是自适应提升算法,其运行过程如下:
- 1.计算样本权重
对训练数据中的每个样本,赋予其权重,即样本权重,用向量D表示,这些权重都初始化成相等值。假设有n个样本的训练集:
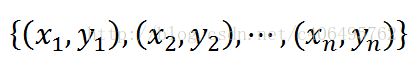
设定每个样本的权重都是相等的,即1/n
- 2.计算错误率
利用第一个弱学习算法h1对其进行学习,学习完成后对错误率ε的统计:

- 3.计算弱学习算法权重
弱学习算法也有一个权重,用向量α表示,利用错误率计算权重α:
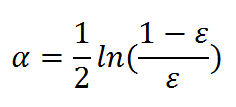
- 4.更新样本权重
在一次学习完成之后,需要重新调整样本的权重,以使得在第一分类中被错分的样本的权重在接下来的学习中可以重点对其进行学习。
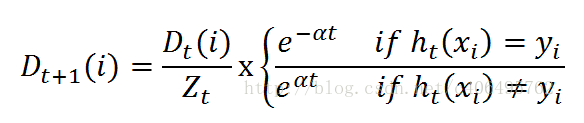
其中,h_t(x_i) = y_i表示对第i个样本训练正确,不等于则表示分类错误。
Z_t是一个归一化因子:
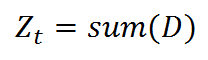
这个公式我们可以继续化简,将两个公式进行合并,化简如下:

- 5.AdaBoost算法
重复进行学习,这样经过t轮的学习后,就会得到t个弱学习算法、权重、弱分类器的输出以及最终AdaBoost算法的输出,分别如下:

其中,sign(x)是符号函数。
具体过程如下:

图英文翻译如下:
AdaBoost算法总结
直接对应的上面步骤。

基于单层决策树构建弱分类器
建立AdaBoost算法之前,我们必须先建立弱分类器,并保存样本的权重。
弱分类器使用单层决策树,也称决策树桩,它是一种简单的决策树,通过给定的阈值,进行分类。
数据集可视化
为了训练单层决策树,我们需要创建一个训练集,编写代码如下:
# -*-coding:utf-8 -*-
import numpy as np
import matplotlib.pyplot as plt
def loadSimpData():
"""
创建单层决策树的数据集
Returns:
dataMat - 数据矩阵
classLabels - 数据标签
"""
datMat = np.matrix([[ 1. , 2.1],
[ 1.5, 1.6],
[ 1.3, 1. ],
[ 1. , 1. ],
[ 2. , 1. ]])
classLabels = [1.0, 1.0, -1.0, -1.0, 1.0]
return datMat,classLabels
def showDataSet(dataMat, labelMat):
"""
数据可视化
Parameters:
dataMat - 数据矩阵
labelMat - 数据标签
Returns:
无
"""
data_plus = [] #正样本
data_minus = [] #负样本
for i in range(len(dataMat)):
if labelMat[i] > 0:
data_plus.append(dataMat[i])
else:
data_minus.append(dataMat[i])
data_plus_np = np.array(data_plus) #转换为numpy矩阵
data_minus_np = np.array(data_minus) #转换为numpy矩阵
plt.scatter(np.transpose(data_plus_np)[0], np.transpose(data_plus_np)[1]) #正样本散点图
plt.scatter(np.transpose(data_minus_np)[0], np.transpose(data_minus_np)[1]) #负样本散点图
plt.show()
if __name__ == '__main__':
dataArr,classLabels = loadSimpData()
showDataSet(dataArr,classLabels)
运行结果如下所示:

可以看到,如果想要试着从某个坐标轴上选择一个值(即选择一条与坐标轴平行的直线)来将所有的蓝色圆点和橘色圆点分开,这显然是不可能的。
这就是单层决策树难以处理的一个著名问题。
通过使用多颗单层决策树,我们可以构建出一个能够对该数据集完全正确分类的分类器。
构建单层决策树
我们设置一个分类阈值,比如现在横向进行切分,如下图:
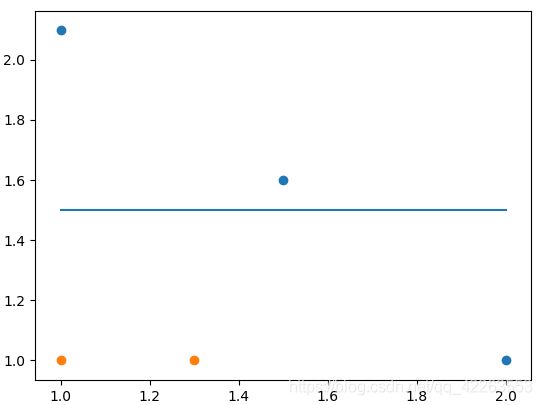
蓝色横线上面是一个类别,下面是另一个类别。
显然,有一个蓝色点分类错误,计算此时的分类误差,误差为1/5 = 0.2。
这个横线与坐标轴的y轴的交点,就是我们设置的阈值,通过不断改变阈值的大小,找到使单层决策树的分类误差最小的阈值。
同理,竖线也是如此,找到最佳分类的阈值,就找到了最佳单层决策树,编写代码如下:
# -*-coding:utf-8 -*-
import numpy as np
import matplotlib.pyplot as plt
def loadSimpData():
"""
创建单层决策树的数据集
Parameters:
无
Returns:
dataMat - 数据矩阵
classLabels - 数据标签
"""
datMat = np.matrix([[ 1. , 2.1],
[ 1.5, 1.6],
[ 1.3, 1. ],
[ 1. , 1. ],
[ 2. , 1. ]])
classLabels = [1.0, 1.0, -1.0, -1.0, 1.0]
return datMat,classLabels
def stumpClassify(dataMatrix,dimen,threshVal,threshIneq):
"""
单层决策树分类函数
Parameters:
dataMatrix - 数据矩阵
dimen - 第dimen列,也就是第几个特征
threshVal - 阈值
threshIneq - 标志
Returns:
retArray - 分类结果
"""
retArray = np.ones((np.shape(dataMatrix)[0],1)) #初始化retArray为1
if threshIneq == 'lt':
retArray[dataMatrix[:,dimen] <= threshVal] = -1.0 #如果小于阈值,则赋值为-1
else:
retArray[dataMatrix[:,dimen] > threshVal] = -1.0 #如果大于阈值,则赋值为-1
return retArray
def buildStump(dataArr,classLabels,D):
"""
找到数据集上最佳的单层决策树
Parameters:
dataArr - 数据矩阵
classLabels - 数据标签
D - 样本权重
Returns:
bestStump - 最佳单层决策树信息
minError - 最小误差
bestClasEst - 最佳的分类结果
"""
dataMatrix = np.mat(dataArr); labelMat = np.mat(classLabels).T
m,n = np.shape(dataMatrix)
numSteps = 10.0; bestStump = {}; bestClasEst = np.mat(np.zeros((m,1)))
minError = float('inf') #最小误差初始化为正无穷大
for i in range(n): #遍历所有特征
rangeMin = dataMatrix[:,i].min(); rangeMax = dataMatrix[:,i].max() #找到特征中最小的值和最大值
stepSize = (rangeMax - rangeMin) / numSteps #计算步长
for j in range(-1, int(numSteps) + 1):
for inequal in ['lt', 'gt']: #大于和小于的情况,均遍历。lt:less than,gt:greater than
threshVal = (rangeMin + float(j) * stepSize) #计算阈值
predictedVals = stumpClassify(dataMatrix, i, threshVal, inequal)#计算分类结果
errArr = np.mat(np.ones((m,1))) #初始化误差矩阵
errArr[predictedVals == labelMat] = 0 #分类正确的,赋值为0
weightedError = D.T * errArr #计算误差
print("split: dim %d, thresh %.2f, thresh ineqal: %s, the weighted error is %.3f" % (i, threshVal, inequal, weightedError))
if weightedError < minError: #找到误差最小的分类方式
minError = weightedError
bestClasEst = predictedVals.copy()
bestStump['dim'] = i
bestStump['thresh'] = threshVal
bestStump['ineq'] = inequal
return bestStump,minError,bestClasEst
if __name__ == '__main__':
dataArr,classLabels = loadSimpData()
D = np.mat(np.ones((5, 1)) / 5)
bestStump,minError,bestClasEst = buildStump(dataArr,classLabels,D)
print('bestStump:\n', bestStump)
print('minError:\n', minError)
print('bestClasEst:\n', bestClasEst)
结果如下:

代码不难理解,就是通过遍历,改变不同的阈值,计算最终的分类误差,找到分类误差最小的分类方式,即为我们要找的最佳单层决策树。
这里lt表示less than,表示分类方式,对于小于阈值的样本点赋值为-1,gt表示greater than,也是表示分类方式,对于大于阈值的样本点赋值为-1。
经过遍历,我们找到,训练好的最佳单层局册数的最小分类误差为0.2,就是对于该数据集,无论用什么样的单层决策树,分类误差最小就是0.2。
这就是我们训练好的弱分类器。
接下来,使用AdaBoost算法提升分类器性能,将分类误差缩小到0。
使用AdaBoost提升分类器性能
按照之前说过的AdaBoost算法的实现过程,使用AdaBoost算法提升分类器性能,编写如下代码:
# -*-coding:utf-8 -*-
import numpy as np
import matplotlib.pyplot as plt
"""
Author:
Jack Cui
Blog:
http://blog.csdn.net/c406495762
Zhihu:
https://www.zhihu.com/people/Jack--Cui/
Modify:
2017-10-10
"""
def loadSimpData():
"""
创建单层决策树的数据集
Parameters:
无
Returns:
dataMat - 数据矩阵
classLabels - 数据标签
"""
datMat = np.matrix([[ 1. , 2.1],
[ 1.5, 1.6],
[ 1.3, 1. ],
[ 1. , 1. ],
[ 2. , 1. ]])
classLabels = [1.0, 1.0, -1.0, -1.0, 1.0]
return datMat,classLabels
def stumpClassify(dataMatrix,dimen,threshVal,threshIneq):
"""
单层决策树分类函数
Parameters:
dataMatrix - 数据矩阵
dimen - 第dimen列,也就是第几个特征
threshVal - 阈值
threshIneq - 标志
Returns:
retArray - 分类结果
"""
retArray = np.ones((np.shape(dataMatrix)[0],1)) #初始化retArray为1
if threshIneq == 'lt':
retArray[dataMatrix[:,dimen] <= threshVal] = -1.0 #如果小于阈值,则赋值为-1
else:
retArray[dataMatrix[:,dimen] > threshVal] = -1.0 #如果大于阈值,则赋值为-1
return retArray
def buildStump(dataArr,classLabels,D):
"""
找到数据集上最佳的单层决策树
Parameters:
dataArr - 数据矩阵
classLabels - 数据标签
D - 样本权重
Returns:
bestStump - 最佳单层决策树信息
minError - 最小误差
bestClasEst - 最佳的分类结果
"""
dataMatrix = np.mat(dataArr); labelMat = np.mat(classLabels).T
m,n = np.shape(dataMatrix)
numSteps = 10.0; bestStump = {}; bestClasEst = np.mat(np.zeros((m,1)))
minError = float('inf') #最小误差初始化为正无穷大
for i in range(n): #遍历所有特征
rangeMin = dataMatrix[:,i].min(); rangeMax = dataMatrix[:,i].max() #找到特征中最小的值和最大值
stepSize = (rangeMax - rangeMin) / numSteps #计算步长
for j in range(-1, int(numSteps) + 1):
for inequal in ['lt', 'gt']: #大于和小于的情况,均遍历。lt:less than,gt:greater than
threshVal = (rangeMin + float(j) * stepSize) #计算阈值
predictedVals = stumpClassify(dataMatrix, i, threshVal, inequal)#计算分类结果
errArr = np.mat(np.ones((m,1))) #初始化误差矩阵
errArr[predictedVals == labelMat] = 0 #分类正确的,赋值为0
weightedError = D.T * errArr #计算误差
print("split: dim %d, thresh %.2f, thresh ineqal: %s, the weighted error is %.3f" % (i, threshVal, inequal, weightedError))
if weightedError < minError: #找到误差最小的分类方式
minError = weightedError
bestClasEst = predictedVals.copy()
bestStump['dim'] = i
bestStump['thresh'] = threshVal
bestStump['ineq'] = inequal
return bestStump, minError, bestClasEst
def adaBoostTrainDS(dataArr, classLabels, numIt = 40):
weakClassArr = []
m = np.shape(dataArr)[0]
D = np.mat(np.ones((m, 1)) / m) #初始化权重
aggClassEst = np.mat(np.zeros((m,1)))
for i in range(numIt):
bestStump, error, classEst = buildStump(dataArr, classLabels, D) #构建单层决策树
print("D:",D.T)
alpha = float(0.5 * np.log((1.0 - error) / max(error, 1e-16))) #计算弱学习算法权重alpha,使error不等于0,因为分母不能为0
bestStump['alpha'] = alpha #存储弱学习算法权重
weakClassArr.append(bestStump) #存储单层决策树
print("classEst: ", classEst.T)
expon = np.multiply(-1 * alpha * np.mat(classLabels).T, classEst) #计算e的指数项
D = np.multiply(D, np.exp(expon))
D = D / D.sum() #根据样本权重公式,更新样本权重
#计算AdaBoost误差,当误差为0的时候,退出循环
aggClassEst += alpha * classEst
print("aggClassEst: ", aggClassEst.T)
aggErrors = np.multiply(np.sign(aggClassEst) != np.mat(classLabels).T, np.ones((m,1))) #计算误差
errorRate = aggErrors.sum() / m
print("total error: ", errorRate)
if errorRate == 0.0: break #误差为0,退出循环
return weakClassArr, aggClassEst
if __name__ == '__main__':
dataArr,classLabels = loadSimpData()
weakClassArr, aggClassEst = adaBoostTrainDS(dataArr, classLabels)
print(weakClassArr)
print(aggClassEst)
结果如下:

在第一轮迭代中,D中的所有值都相等。
于是,只有第一个数据点被错分了。因此在第二轮迭代中,D向量给第一个数据点0.5的权重。
这就可以通过变量aggClassEst的符号来了解总的类别。
第二次迭代之后,我们就会发现第一个数据点已经正确分类了,但此时最后一个数据点却是错分了。
D向量中的最后一个元素变为0.5,而D向量中的其他值都变得非常小。
最后,第三次迭代之后aggClassEst所有值的符号和真是类别标签都完全吻合,那么训练错误率为0,程序终止运行。
最后训练结果包含了三个弱分类器,其中包含了分类所需要的所有信息。一共迭代了3次,所以训练了3个弱分类器构成一个使用AdaBoost算法优化过的分类器,分类器的错误率为0。
一旦拥有了多个弱分类器以及其对应的alpha值,进行测试就变得想当容易了。编写代码如下:
# -*-coding:utf-8 -*-
import numpy as np
import matplotlib.pyplot as plt
"""
Author:
Jack Cui
Blog:
http://blog.csdn.net/c406495762
Zhihu:
https://www.zhihu.com/people/Jack--Cui/
Modify:
2017-10-10
"""
def loadSimpData():
"""
创建单层决策树的数据集
Parameters:
无
Returns:
dataMat - 数据矩阵
classLabels - 数据标签
"""
datMat = np.matrix([[ 1. , 2.1],
[ 1.5, 1.6],
[ 1.3, 1. ],
[ 1. , 1. ],
[ 2. , 1. ]])
classLabels = [1.0, 1.0, -1.0, -1.0, 1.0]
return datMat,classLabels
def showDataSet(dataMat, labelMat):
"""
数据可视化
Parameters:
dataMat - 数据矩阵
labelMat - 数据标签
Returns:
无
"""
data_plus = [] #正样本
data_minus = [] #负样本
for i in range(len(dataMat)):
if labelMat[i] > 0:
data_plus.append(dataMat[i])
else:
data_minus.append(dataMat[i])
data_plus_np = np.array(data_plus) #转换为numpy矩阵
data_minus_np = np.array(data_minus) #转换为numpy矩阵
plt.scatter(np.transpose(data_plus_np)[0], np.transpose(data_plus_np)[1]) #正样本散点图
plt.scatter(np.transpose(data_minus_np)[0], np.transpose(data_minus_np)[1]) #负样本散点图
plt.show()
def stumpClassify(dataMatrix,dimen,threshVal,threshIneq):
"""
单层决策树分类函数
Parameters:
dataMatrix - 数据矩阵
dimen - 第dimen列,也就是第几个特征
threshVal - 阈值
threshIneq - 标志
Returns:
retArray - 分类结果
"""
retArray = np.ones((np.shape(dataMatrix)[0],1)) #初始化retArray为1
if threshIneq == 'lt':
retArray[dataMatrix[:,dimen] <= threshVal] = -1.0 #如果小于阈值,则赋值为-1
else:
retArray[dataMatrix[:,dimen] > threshVal] = -1.0 #如果大于阈值,则赋值为-1
return retArray
def buildStump(dataArr,classLabels,D):
"""
找到数据集上最佳的单层决策树
Parameters:
dataArr - 数据矩阵
classLabels - 数据标签
D - 样本权重
Returns:
bestStump - 最佳单层决策树信息
minError - 最小误差
bestClasEst - 最佳的分类结果
"""
dataMatrix = np.mat(dataArr); labelMat = np.mat(classLabels).T
m,n = np.shape(dataMatrix)
numSteps = 10.0; bestStump = {}; bestClasEst = np.mat(np.zeros((m,1)))
minError = float('inf') #最小误差初始化为正无穷大
for i in range(n): #遍历所有特征
rangeMin = dataMatrix[:,i].min(); rangeMax = dataMatrix[:,i].max() #找到特征中最小的值和最大值
stepSize = (rangeMax - rangeMin) / numSteps #计算步长
for j in range(-1, int(numSteps) + 1):
for inequal in ['lt', 'gt']: #大于和小于的情况,均遍历。lt:less than,gt:greater than
threshVal = (rangeMin + float(j) * stepSize) #计算阈值
predictedVals = stumpClassify(dataMatrix, i, threshVal, inequal)#计算分类结果
errArr = np.mat(np.ones((m,1))) #初始化误差矩阵
errArr[predictedVals == labelMat] = 0 #分类正确的,赋值为0
weightedError = D.T * errArr #计算误差
# print("split: dim %d, thresh %.2f, thresh ineqal: %s, the weighted error is %.3f" % (i, threshVal, inequal, weightedError))
if weightedError < minError: #找到误差最小的分类方式
minError = weightedError
bestClasEst = predictedVals.copy()
bestStump['dim'] = i
bestStump['thresh'] = threshVal
bestStump['ineq'] = inequal
return bestStump, minError, bestClasEst
def adaBoostTrainDS(dataArr, classLabels, numIt = 40):
"""
使用AdaBoost算法提升弱分类器性能
Parameters:
dataArr - 数据矩阵
classLabels - 数据标签
numIt - 最大迭代次数
Returns:
weakClassArr - 训练好的分类器
aggClassEst - 类别估计累计值
"""
weakClassArr = []
m = np.shape(dataArr)[0]
D = np.mat(np.ones((m, 1)) / m) #初始化权重
aggClassEst = np.mat(np.zeros((m,1)))
for i in range(numIt):
bestStump, error, classEst = buildStump(dataArr, classLabels, D) #构建单层决策树
# print("D:",D.T)
alpha = float(0.5 * np.log((1.0 - error) / max(error, 1e-16))) #计算弱学习算法权重alpha,使error不等于0,因为分母不能为0
bestStump['alpha'] = alpha #存储弱学习算法权重
weakClassArr.append(bestStump) #存储单层决策树
# print("classEst: ", classEst.T)
expon = np.multiply(-1 * alpha * np.mat(classLabels).T, classEst) #计算e的指数项
D = np.multiply(D, np.exp(expon))
D = D / D.sum() #根据样本权重公式,更新样本权重
#计算AdaBoost误差,当误差为0的时候,退出循环
aggClassEst += alpha * classEst #计算类别估计累计值
# print("aggClassEst: ", aggClassEst.T)
aggErrors = np.multiply(np.sign(aggClassEst) != np.mat(classLabels).T, np.ones((m,1))) #计算误差
errorRate = aggErrors.sum() / m
# print("total error: ", errorRate)
if errorRate == 0.0: break #误差为0,退出循环
return weakClassArr, aggClassEst
def adaClassify(datToClass,classifierArr):
"""
AdaBoost分类函数
Parameters:
datToClass - 待分类样例
classifierArr - 训练好的分类器
Returns:
分类结果
"""
dataMatrix = np.mat(datToClass)
m = np.shape(dataMatrix)[0]
aggClassEst = np.mat(np.zeros((m,1)))
for i in range(len(classifierArr)): #遍历所有分类器,进行分类
classEst = stumpClassify(dataMatrix, classifierArr[i]['dim'], classifierArr[i]['thresh'], classifierArr[i]['ineq'])
aggClassEst += classifierArr[i]['alpha'] * classEst
print(aggClassEst)
return np.sign(aggClassEst)
if __name__ == '__main__':
dataArr,classLabels = loadSimpData()
weakClassArr, aggClassEst = adaBoostTrainDS(dataArr, classLabels)
print(adaClassify([[0,0],[5,5]], weakClassArr))
结果如下:
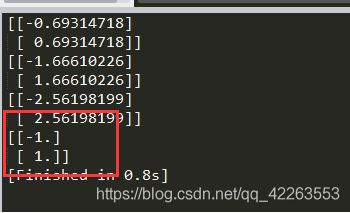
代码很简单,在之前代码的基础上,添加adaClassify()函数,该函数遍历所有训练得到的弱分类器,利用单层决策树,输出的类别估计值乘以该单层决策树的分类器权重alpha,然后累加到aggClassEst上,最后通过sign函数最终的结果。
可以看到,分类没有问题,测试(5,5)属于正类,(0,0)属于负类。
在一个数据集上应用AdaBoost
在Logistic回归那一章,我们使用Logistic回归方法训练马疝病的数据集,预测病马死亡率。当时训练结果如下图所示:

这个是使用Sklearn的LogisticRegression()训练的分类器,可以看到,正确率约为73.134%,也就是说错误率约为26.866%。
可以看到错误率还是蛮高的,现在我们使用AdaBoost算法,训练出一个更强的分类器,这里的数据集有所变化,之前的标签是0和1,现在将标签改为+1和-1,其他数据不变。
更改好的数据集下载地址:https://github.com/Jack-Cherish/Machine-Learning/tree/master/AdaBoost
使用上面的AdaBoost算法
使用自己的用Python写的AbaBoost算法进行训练,添加loadDataSet函数用于加载数据集。编写代码如下:
# -*-coding:utf-8 -*-
import numpy as np
import matplotlib.pyplot as plt
"""
Author:
Jack Cui
Blog:
http://blog.csdn.net/c406495762
Zhihu:
https://www.zhihu.com/people/Jack--Cui/
Modify:
2017-10-10
"""
def loadDataSet(fileName):
numFeat = len((open(fileName).readline().split('\t')))
dataMat = []; labelMat = []
fr = open(fileName)
for line in fr.readlines():
lineArr = []
curLine = line.strip().split('\t')
for i in range(numFeat - 1):
lineArr.append(float(curLine[i]))
dataMat.append(lineArr)
labelMat.append(float(curLine[-1]))
return dataMat, labelMat
def stumpClassify(dataMatrix,dimen,threshVal,threshIneq):
"""
单层决策树分类函数
Parameters:
dataMatrix - 数据矩阵
dimen - 第dimen列,也就是第几个特征
threshVal - 阈值
threshIneq - 标志
Returns:
retArray - 分类结果
"""
retArray = np.ones((np.shape(dataMatrix)[0],1)) #初始化retArray为1
if threshIneq == 'lt':
retArray[dataMatrix[:,dimen] <= threshVal] = -1.0 #如果小于阈值,则赋值为-1
else:
retArray[dataMatrix[:,dimen] > threshVal] = -1.0 #如果大于阈值,则赋值为-1
return retArray
def buildStump(dataArr,classLabels,D):
"""
找到数据集上最佳的单层决策树
Parameters:
dataArr - 数据矩阵
classLabels - 数据标签
D - 样本权重
Returns:
bestStump - 最佳单层决策树信息
minError - 最小误差
bestClasEst - 最佳的分类结果
"""
dataMatrix = np.mat(dataArr); labelMat = np.mat(classLabels).T
m,n = np.shape(dataMatrix)
numSteps = 10.0; bestStump = {}; bestClasEst = np.mat(np.zeros((m,1)))
minError = float('inf') #最小误差初始化为正无穷大
for i in range(n): #遍历所有特征
rangeMin = dataMatrix[:,i].min(); rangeMax = dataMatrix[:,i].max() #找到特征中最小的值和最大值
stepSize = (rangeMax - rangeMin) / numSteps #计算步长
for j in range(-1, int(numSteps) + 1):
for inequal in ['lt', 'gt']: #大于和小于的情况,均遍历。lt:less than,gt:greater than
threshVal = (rangeMin + float(j) * stepSize) #计算阈值
predictedVals = stumpClassify(dataMatrix, i, threshVal, inequal)#计算分类结果
errArr = np.mat(np.ones((m,1))) #初始化误差矩阵
errArr[predictedVals == labelMat] = 0 #分类正确的,赋值为0
weightedError = D.T * errArr #计算误差
# print("split: dim %d, thresh %.2f, thresh ineqal: %s, the weighted error is %.3f" % (i, threshVal, inequal, weightedError))
if weightedError < minError: #找到误差最小的分类方式
minError = weightedError
bestClasEst = predictedVals.copy()
bestStump['dim'] = i
bestStump['thresh'] = threshVal
bestStump['ineq'] = inequal
return bestStump, minError, bestClasEst
def adaBoostTrainDS(dataArr, classLabels, numIt = 40):
"""
使用AdaBoost算法提升弱分类器性能
Parameters:
dataArr - 数据矩阵
classLabels - 数据标签
numIt - 最大迭代次数
Returns:
weakClassArr - 训练好的分类器
aggClassEst - 类别估计累计值
"""
weakClassArr = []
m = np.shape(dataArr)[0]
D = np.mat(np.ones((m, 1)) / m) #初始化权重
aggClassEst = np.mat(np.zeros((m,1)))
for i in range(numIt):
bestStump, error, classEst = buildStump(dataArr, classLabels, D) #构建单层决策树
# print("D:",D.T)
alpha = float(0.5 * np.log((1.0 - error) / max(error, 1e-16))) #计算弱学习算法权重alpha,使error不等于0,因为分母不能为0
bestStump['alpha'] = alpha #存储弱学习算法权重
weakClassArr.append(bestStump) #存储单层决策树
# print("classEst: ", classEst.T)
expon = np.multiply(-1 * alpha * np.mat(classLabels).T, classEst) #计算e的指数项
D = np.multiply(D, np.exp(expon))
D = D / D.sum() #根据样本权重公式,更新样本权重
#计算AdaBoost误差,当误差为0的时候,退出循环
aggClassEst += alpha * classEst #计算类别估计累计值
# print("aggClassEst: ", aggClassEst.T)
aggErrors = np.multiply(np.sign(aggClassEst) != np.mat(classLabels).T, np.ones((m,1))) #计算误差
errorRate = aggErrors.sum() / m
# print("total error: ", errorRate)
if errorRate == 0.0: break #误差为0,退出循环
return weakClassArr, aggClassEst
def adaClassify(datToClass,classifierArr):
"""
AdaBoost分类函数
Parameters:
datToClass - 待分类样例
classifierArr - 训练好的分类器
Returns:
分类结果
"""
dataMatrix = np.mat(datToClass)
m = np.shape(dataMatrix)[0]
aggClassEst = np.mat(np.zeros((m,1)))
for i in range(len(classifierArr)): #遍历所有分类器,进行分类
classEst = stumpClassify(dataMatrix, classifierArr[i]['dim'], classifierArr[i]['thresh'], classifierArr[i]['ineq'])
aggClassEst += classifierArr[i]['alpha'] * classEst
# print(aggClassEst)
return np.sign(aggClassEst)
if __name__ == '__main__':
dataArr, LabelArr = loadDataSet('horseColicTraining2.txt')
weakClassArr, aggClassEst = adaBoostTrainDS(dataArr, LabelArr)
testArr, testLabelArr = loadDataSet('horseColicTest2.txt')
print(weakClassArr)
predictions = adaClassify(dataArr, weakClassArr)
errArr = np.mat(np.ones((len(dataArr), 1)))
print('训练集的错误率:%.3f%%' % float(errArr[predictions != np.mat(LabelArr).T].sum() / len(dataArr) * 100))
predictions = adaClassify(testArr, weakClassArr)
errArr = np.mat(np.ones((len(testArr), 1)))
print('测试集的错误率:%.3f%%' % float(errArr[predictions != np.mat(testLabelArr).T].sum() / len(testArr) * 100))
结果如下:

这里输出了AdaBoost算法训练好的分类器的组合,我们只迭代了40次,也就是训练了40个弱分类器。
最终,训练集的错误率为19.732%,测试集的错误率为19.403%,可以看到相对于Sklearn的罗辑回归方法,错误率降低了很多。
这个仅仅是我们训练40个弱分类器的结果,如果训练更多弱分类器,效果会更好。
但是当弱分类器数量过多的时候,你会发现训练集错误率降低很多,但是测试集错误率提升了很多,这种现象就是过拟合(overfitting)。
分类器对训练集的拟合效果好,但是缺失了普适性,只对训练集的分类效果好,这是我们不希望看到的。
使用Sklearn的AdaBoost算法
官方英文文档手册:http://scikit-learn.org/stable/modules/generated/sklearn.ensemble.AdaBoostClassifier.html
sklearn.ensemble模块提供了很多集成方法,AdaBoost、Bagging、随机森林等。本文使用的是AdaBoostClassifier
函数说明参考文档手册,代码如下所示:
# -*-coding:utf-8 -*-
import numpy as np
from sklearn.ensemble import AdaBoostClassifier
from sklearn.tree import DecisionTreeClassifier
"""
Author:
Jack Cui
Blog:
http://blog.csdn.net/c406495762
Zhihu:
https://www.zhihu.com/people/Jack--Cui/
Modify:
2017-10-11
"""
def loadDataSet(fileName):
numFeat = len((open(fileName).readline().split('\t')))
dataMat = []; labelMat = []
fr = open(fileName)
for line in fr.readlines():
lineArr = []
curLine = line.strip().split('\t')
for i in range(numFeat - 1):
lineArr.append(float(curLine[i]))
dataMat.append(lineArr)
labelMat.append(float(curLine[-1]))
return dataMat, labelMat
if __name__ == '__main__':
dataArr, classLabels = loadDataSet('horseColicTraining2.txt')
testArr, testLabelArr = loadDataSet('horseColicTest2.txt')
bdt = AdaBoostClassifier(DecisionTreeClassifier(max_depth = 2), algorithm = "SAMME", n_estimators = 10)
bdt.fit(dataArr, classLabels)
predictions = bdt.predict(dataArr)
errArr = np.mat(np.ones((len(dataArr), 1)))
print('训练集的错误率:%.3f%%' % float(errArr[predictions != classLabels].sum() / len(dataArr) * 100))
predictions = bdt.predict(testArr)
errArr = np.mat(np.ones((len(testArr), 1)))
print('测试集的错误率:%.3f%%' % float(errArr[predictions != testLabelArr].sum() / len(testArr) * 100))
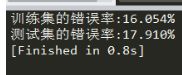
我们使用局册数分类器作为使用的弱分类器,使用AdaBoost算法训练分类器。可以看到训练集的错误率为16.054%,测试集的错误率为:17.910%。更改n_estimators参数,你会发现跟我们自己写的代码,更改迭代次数的效果是一样的。
n_enstimators参数过大,会导致过拟合。
非均衡分类问题(分类器性能评价)
在之前的笔记中,讲了很多分类器。我们都是假设所有类别的分类代价是一样的。比如在逻辑回归那篇文章中,我们构建了一个用于检测患疝病的马屁是否存活的系统。在那里,我们构建了分类器,但是并没有对分类后的情形加以讨论。假如某人给我们牵来一匹马,他希望我们能预测这匹马能否生存。我们说马会死,那么他们就可能会对马实施安乐死,而不是通过给马喂药来延缓其不可避免的死亡过程。我们的预测也许是错误的,马本来是可以继续活着的。毕竟,我们的分类器只有80%的精确率(accuracy)。如果我们预测错误,那么我们将会错杀一个如此昂贵的动物,更不要说人对马还存在情感上的依恋了。
再比如,如何过滤垃圾邮件呢?如果收件箱中会出现某些垃圾邮件,但合法邮件永远不会扔进垃圾邮件夹中,人们会是否会满意呢?显然,我们可以忍受收件箱中偶尔出现的垃圾邮件,但是绝不能忍受,合法邮件被误扔如垃圾邮件夹中,万一这是一封女神or男神的表白信,这岂不是因此错过了一段旷世姻缘?
很多时候,不同类别的分类代价并不相等,这就是非均衡分类问题。我们将会考察一种新的分类器性能度量方法,而不再是简单的通过错误率进行评价,并且通过图像技术来对上述非均衡问题下不同分类器性能进行可视化处理。
参考博主:Jack-Cui的博文:https://blog.csdn.net/c406495762/article/details/78212124
机器学习-分类总结
在学了这几种分类算法之后,我觉得自己只是了解了分类学习算法的一些算法流程,对数学推导并没有下太大功夫,而且代码方面也是问题,所以在后续我会自己寻找一些实例,并自己手写代码实现一下,其中数据集的收集、数据集处理、数学推导、代码流程等方面会下功夫,并回顾所学知识,对项目花几天时间去实现,并总结。另外包括实践一种分类算法在实例后,对非均衡分类问题会重新回顾,当下并没有太大兴趣想了解,希望自己在做实例的时候能回顾到这些问题,然后提高分类算法。