使用python的scrapy框架爬取动态网站智联招聘的岗位信息
最近正在找工作,经常登陆智联招聘,闲来无事就写了个代码,自动爬取岗位信息分文件夹保存在本地文件中.本来觉得很简单,然而完成还是费了一番手脚的,其中遇到一些比较有意思的坑,给大家分享一下.(文末附源码)
打开智联的官网,发现不用登陆也能爬取,哈哈,心里顿时乐开了花,so easy!
先简单观察了一下,两层页面结构,第一层是搜索后显示的招聘岗位列表,第二层是单个岗位的详细信息.
那么大致思路出来了
1,从搜索结果的页面开始搜索,获取每个岗位详情页的URL

2,在每个详情页提取具体信息
然而开局不顺...
在第一层网页检查源码,发现并没有发现岗位列表,更别提岗位的URL.
源码中没有,但却真真切切的显示在眼前,典型的异步加载.肯定会有一个通过js加载的列表
无奈,只能苦逼的通过抓包去一个个检查了.(tips:翻归翻,也要讲究点技术性,什么.png啥的就不要看了吧)
运气很好,翻的第二个json文件就是请求的数据,哈哈,我是不是很鸡贼.
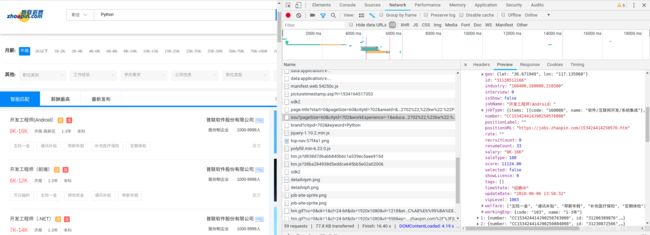
再来看看请求头

url指向了fe-api.zhaopin.com的服务器
让我们解码以下URL,得到了,以下可读版的URL
https://fe-api.zhaopin.com/c/i/sou?pageSize=60&cityId=702&workExperience=-1&education=-1&companyType=-1&employmentType=-1&jobWelfareTag=-1&kw=Python&kt=3&lastUrlQuery={"jl":"702","kw":"Python","kt":"3"}
再翻下页,第二页呢?
https://fe-api.zhaopin.com/c/i/sou?pageSize=60&cityId=702&workExperience=-1&education=-1&companyType=-1&employmentType=-1&jobWelfareTag=-1&kw=Python&kt=3&lastUrlQuery={"p":2,"jl":"702","kw":"Python","kt":"3"}
果然是有规律的,最后的字典中多了一对键值对p:2,反向试一波,改成p:1也是可行的,正好是第一页,说明p的默认值就是1.
翻页问题就简单多了,无非是改一下p的值就行了(第二页)
多次对比后,kw:代表的是你的搜索关键字,jl代表的是你的地区代号(代号在源码中博主给整理了一份)
随便改改就OK啦
那么根据json的格式,取出每个简历详情页的url,并设置回调函数下一步处理响应
def parse(self,response):
res_json = json.loads(response.text)
jobs_json = res_json["data"]["results"]
for job in jobs_json:
url = job["positionURL"]
url = str(url)
yield scrapy.Request(url,callback=self.content)
打开了每个详情页以后,检查源码,哈哈,这次总不是动态加载的了,所需信息都在源码中有
是时候请出我们的大腕--正则表达式了.
本来以为剩下总没有什么难点了吧,然而还是遇到了一个小问题
使用正则匹配不出数据,我又测试了一下源代码和我的正则,完全没有问题,那么问题出在哪里呢?
正则表达式既然没问题,那肯定又是源代码在搞鬼了,使用代码查看了以下响应回来的源码,终于找到了问题.
响应回来的源码是没有任何样式的,而刚开始我测试的源码是在动态加载了css以后的源码,好吧,找到问题,改了一下正则,问题顺利解决
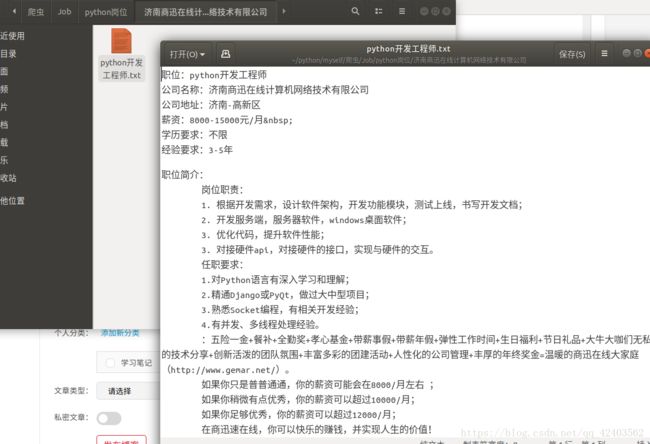
展示以下成果

最后贴上源码地址:
https://gitee.com/ldw295/Job_spider