RNN
RNN
ANN 和 CNN 都是假设:元素之间是相互独立的,输入与输出也是相互独立的,但是现实中很多东西是有先后顺序的,比如时间序列,语句等,因此其输出依赖于输入与记忆,一句话解释RNN,就是重复使用一个单元结构;RNN 中多少个输入就有多少层
RNN是一个序列到序列的模型,设 X t X_t Xt:表示 t 时刻的输入, o t o_t ot:表示 t 时刻的输出, S t S_t St:表示 t 时刻的记忆
当前时刻的输出取决于当前时刻的输入和记忆
S t = f ( U ∗ X t + W ∗ S t − 1 ) S_t = f(U*X_t + W*S_{t-1}) St=f(U∗Xt+W∗St−1)
f f f 为激活函数,激活函数其实就是对信息做一个过滤,过滤到不重要的信息
RNN 模型训练:BPTT
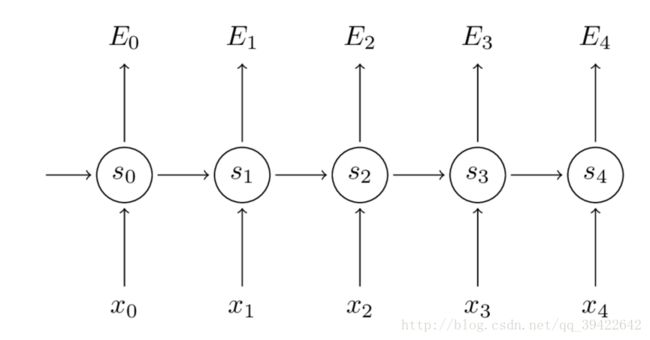
要预测 t 时刻的输出,必须利用上一时刻(t-1)的记忆与当前时刻的输入,设 t 时刻的记忆:
s t = t a n h ( U x t + W s t − 1 ) s_t = tanh(Ux_t + Ws_{t-1}) st=tanh(Uxt+Wst−1)
利用当前时刻的记忆,通过 softmax 输出每个词出现的概率
y ^ t = s o f t m a x ( V s t ) \hat{y}_t = softmax(Vs_t) y^t=softmax(Vst)
所以需要找到最优的参数 ( U , W , V ) (U, W, V) (U,W,V),为了找到最优的参数,我们需要知道通过参数会计算得到什么结果,于是定义损失函数,为交叉熵损失函数:
t 时 刻 的 损 失 : E t ( y t , y ^ t ) = − y t l o g y ^ t t时刻的损失:E_t(y_t,\hat{y}_t) = -y_t log\hat{y}_t t时刻的损失:Et(yt,y^t)=−ytlogy^t
其中,t 时刻的输出,是一个独热向量,只有一个维度为 1,其他为 0;总损失等于所有时刻的损失之和:
E ( y t , y ^ t ) = ∑ t E t ( y t , y ^ t ) = − ∑ t y t l o g y ^ t E(y_t,\hat{y}_t) = \sum\limits_t E_t(y_t,\hat{y}_t) = -\sum\limits_t y_tlog\hat{y}_t E(yt,y^t)=t∑Et(yt,y^t)=−t∑ytlogy^t
当前时刻梯度的计算,与BP算法相比,BP算法是只取决于当前的前一个梯度,而BPTT是取决于当前时刻之间的所有时刻的梯度之和
来源:https://blog.csdn.net/qq_39422642/article/details/78676567
梯度消失问题
RNN 有梯度消失和梯度爆炸的问题,使得其不适合长文本的训练,梯度消失和爆炸的问题不仅存在于 RNN 中,所有深层的网络中都会有这些问题
造成的问题:
- 梯度消失使得模型停止了学习
- 梯度爆炸使得模型无法获得最优参数
神经网络的训练是依赖于梯度的,当发生梯度消失时,模型的权重将无法更新,当发生梯度爆炸时,模型更新权重的步伐将会很大,使得模型不稳定,甚至于造成结果溢出(梯度消失和梯度爆炸只会造成浅层的网络无法更新,因为反向传播)
造成梯度消失的原因
此处举例,有一个每层只有一个神经元的神经网络,且每层的激活函数都为 s i g m o i d sigmoid sigmoid 函数,有
y i = σ ( z i ) = σ ( w i x i + b i ) y_i = \sigma(z_i) = \sigma(w_ix_i+ b_i) yi=σ(zi)=σ(wixi+bi)
当我需要更新某个深层的网络权重的时候,如此处的 b 1 b_1 b1

∂ C ∂ y 4 . . . \frac{\partial C}{\partial y_4}... ∂y4∂C...
而 s i g m o i d ( x ) sigmoid(x) sigmoid(x) 的导数为 x ( 1 − x ) x(1-x) x(1−x),其导数的最大值是 1/4 ,并且权重初始化的时候一般会使用小于 1 的值,显然,对于深层的网络,其梯度在反向传播到达浅层的时候会越来越小,如果我们想通过将初始化 w 的权重为更大的值来解决这个问题,也是不可行的,这样会使得权重的更新非常不稳定,类似梯度爆炸的状态,造成梯度消失和爆炸的本质原因是反向传播时求梯度的链式求导的连乘计算
来源:https://zhuanlan.zhihu.com/p/44163528
语言模型构建
构建流程:
- 读取数据
- 建立字符索引 dict(词:index)
- 时序数据采样
时序数据采样
对时序数据进行采样的目的是,从时序数据中采样出多个样本,及样本对应的标签,可以设置一个滑动窗口,将滑动窗口内的文本作为特征,滑动窗口的下一个字符作为标签
- 随机采样
- 相邻采样
随机采样
所采样得到的相邻两个样本的序列不是连续的,比如
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-zyVvLmgH-1596164812348)(C:\Users\Liang\AppData\Roaming\Typora\typora-user-images\1595974729560.png)]
def data_iter_random(corpus_indices, batch_size, num_steps, device=None):
"""
corpus_indices:待采样文本序列转换为字符索引的序列
batch_size:每个小批量的样本数
num_steps:滑动窗口的大小:每个样本包含的字符数
"""
num_examples = (len(corpus_indices) - 1) // num_steps
epoch_size = num_examples // batch_size
example_indices = list(range(num_examples))
random.shuffle(example_indices)
# 返回从pos开始的长为num_steps的序列
def _data(pos):
return corpus_indices[pos: pos + num_steps]
if device is None:
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
for i in range(epoch_size):
# 每次读取batch_size个随机样本
i = i * batch_size
batch_indices = example_indices[i: i + batch_size]
X = [_data(j * num_steps) for j in batch_indices]
Y = [_data(j * num_steps + 1) for j in batch_indices]
yield torch.tensor(X, dtype=torch.float32, device=device), torch.tensor(Y, dtype=torch.float32, device=device)
相邻采样
所采样得到的相邻两个样本的序列是连续的
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-DPZskLLC-1596164812349)(C:\Users\Liang\AppData\Roaming\Typora\typora-user-images\1595974829267.png)]
def data_iter_consecutive(corpus_indices, batch_size, num_steps, device=None):
if device is None:
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
corpus_indices = torch.tensor(corpus_indices, dtype=torch.float32, device=device)
data_len = len(corpus_indices)
batch_len = data_len // batch_size
indices = corpus_indices[0: batch_size*batch_len].view(batch_size, batch_len)
epoch_size = (batch_len - 1) // num_steps
for i in range(epoch_size):
i = i * num_steps
X = indices[:, i: i + num_steps]
Y = indices[:, i + 1: i + num_steps + 1]
yield X, Y
循环神经网络的使用
将输入转换为独热向量
要文本数据转换为数值表示
- 独热向量
- 词嵌入
def one_hot(x, n_class, dtype=torch.float32):
x = x.long()
res = torch.zeros(x.shape[0], n_class, dtype=dtype, device=device)
res.scatter_(1, x.view(-1, 1), 1)
return res
def to_onehot(X, n_class):
return [one_hot(X[:, i], n_class) for i in range(X.shape[1])]
通常使用困惑度来评价模型的好坏, 惑度是对交叉熵损失函数做指数运算后得到的值
- 最佳情况下,模型总是把标签类别的概率预测为1,此时困惑度为1;
- 最坏情况下,模型总是把标签类别的概率预测为0,此时困惑度为正无穷;
- 基线情况下,模型总是预测所有类别的概率都相同,此时困惑度为类别个数。
num_hiddens = 256
rnn_layer = nn.RNN(input_size=vocab_size, hidden_size=num_hiddens)
此处 rnn_layer 的输入形状为 (时间步数, 批量大小, 输入个数),它在进行前向计算后会返回输出和隐藏状态,