Neo4j单机图数据
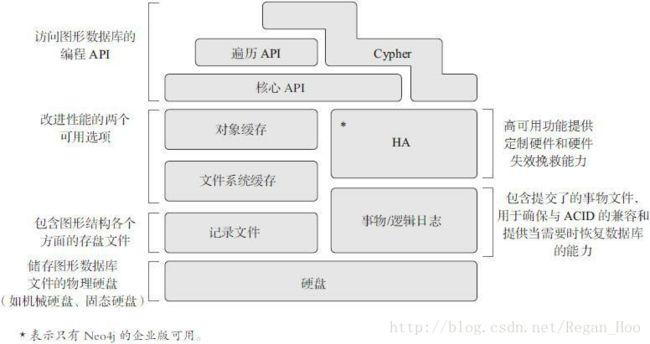
Neo4j模块
存储结构
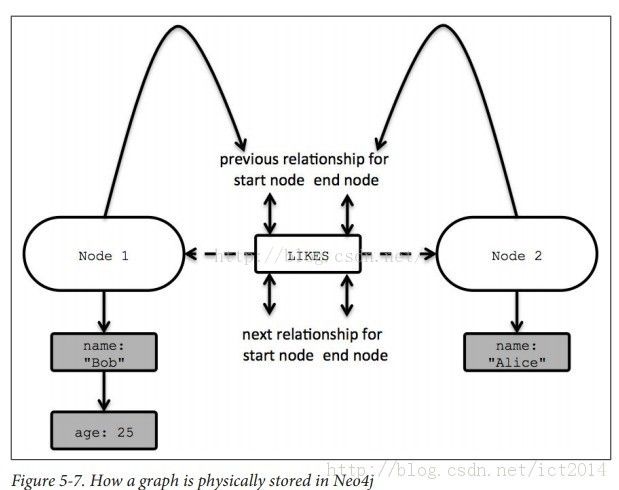
节点存储

节点是否可用+最近一个关系的Id(-1表示无)+最近一个属性的Id(-1表示无) Node[0,used=true,rel=9,prop=-1] Node[1,used=true,rel=1,prop=0] Node[2,used=true,rel=2,prop=2] Node[3,used=true,rel=2,prop=4] Node[4,used=true,rel=4,prop=6] Node[5,used=true,rel=5,prop=8] Node[6,used=true,rel=5,prop=10] Node[7,used=true,rel=7,prop=12] Node[8,used=true,rel=8,prop=14] Node[9,used=true,rel=8,prop=16] Node[10,used=true,rel=10,prop=18] Node[11,used=true,rel=11,prop=20] Node[12,used=true,rel=11,prop=22]
关系存储

是否可用+关系的头节点+关系的尾节点+关系类型+头节点的前一个关系Id+头节点的后一个关系id+尾节点的前一个关系Id+尾节点的后一个关系Id+关系的最近属性Id Relationship[0,used=true,source=1,target=0,type=0,sPrev=1,sNext=-1,tPrev=3,tNext=-1,prop=1] Relationship[1,used=true,source=2,target=1,type=1,sPrev=2,sNext=-1,tPrev=-1,tNext=0,prop=3] Relationship[2,used=true,source=3,target=2,type=2,sPrev=-1,sNext=-1,tPrev=-1,tNext=1,prop=5] Relationship[3,used=true,source=4,target=0,type=0,sPrev=4,sNext=-1,tPrev=6,tNext=0,prop=7] Relationship[4,used=true,source=5,target=4,type=1,sPrev=5,sNext=-1,tPrev=-1,tNext=3,prop=9] Relationship[5,used=true,source=6,target=5,type=2,sPrev=-1,sNext=-1,tPrev=-1,tNext=4,prop=11] Relationship[6,used=true,source=7,target=0,type=0,sPrev=7,sNext=-1,tPrev=9,tNext=3,prop=13] Relationship[7,used=true,source=8,target=7,type=1,sPrev=8,sNext=-1,tPrev=-1,tNext=6,prop=15] Relationship[8,used=true,source=9,target=8,type=2,sPrev=-1,sNext=-1,tPrev=-1,tNext=7,prop=17] Relationship[9,used=true,source=10,target=0,type=0,sPrev=10,sNext=-1,tPrev=-1,tNext=6,prop=19] Relationship[10,used=true,source=11,target=10,type=1,sPrev=11,sNext=-1,tPrev=-1,tNext=9,prop=21] Relationship[11,used=true,source=12,target=11,type=2,sPrev=-1,sNext=-1,tPrev=-1,tNext=10,prop=23]
属性存储
是否可用+前一个属性Id+后一个属性Id+属性块32个字节 Property[10,used=true,prev=-1,next=9,PropertyBlock[INT,key=7,value=5]]
文件结构
- 节点和关系存储文件只关心图的基本存储结构而不是属性数据,这两种记录都是固定大小,从而达到高性能遍历的关键设计决策.节点记录和关系记录都是相当轻量级的,由指向联系和属性列表的指针构成
- 一个节点的所有属性被记录到一个单向链表上面.只有指向下一个属性的指针,没有指向上一个属性的指针
- 两个节点之间的所有关系被记录到一个双向链表上面,既有指向上一个关系的指针,也有指向下一个关系的指针
- 节点存储文件和关系存储文件都是固定长度,只关心结构,不关心属性数据,属性存储文件也是固定长度,只关心数据,不关心结构.当长度不足时,会去申请动态存储,将超出的数据长度存放在动态存储里面,并将地址存放在属性存储文件中.查找的时候进行拼接
性能测试
测试环境:
1. 操作系统: Mac OS X 10.10.5
2. 内存: 8G
3. CPU参数: 8核8线程
4. 编程语言: python 2.7
5. Neo4j 版本: 3.3.0
6. 服务器节点数: 单点
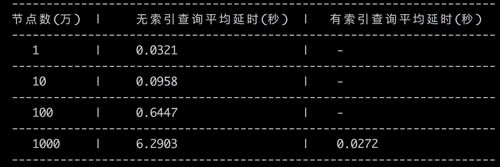
测试内容: 节点数分别在1万, 10万, 100万,1000万情况下,在节点设置索引和不设置索引的情况下查找节点的平均延时。测试结果如下:
7.1000万节点的情况下有索引和无索引插入延时测试:

查询优化策略
- Neo4j HA:(High Availability)即 neo4j 的高可用特性(不过这个特征只能在neo4j 企业版中可用,手动搭建需要自己进行).
- 增加缓存:通过修改配置文件中dbms. query_ cache_ size参数进行调整.
- 索引查询优化
- Neo4j和KV(Key-Value)数据库联合使用:通常在图库和 KV 数据库联合使用时, 特别是经常需要通过属性来查询实体时需要设置 neo4j schema Index,即将neo4j中与 KV 数据库关联的值设置索引。
查询语法Cypher
https://blog.csdn.net/qq_37242224/article/details/81325625
https://neo4j.com/developer/guide-sql-to-cypher/
SELECT p.ProductName, p.UnitPrice FROM products as p ORDER BY p.UnitPrice DESC LIMIT 10;
MATCH (p:Product) RETURN p.productName, p.unitPrice ORDER BY p.unitPrice DESC LIMIT 10;
运算符
- 数学运算符:+、-、*、/、%、^
- 比较运算符:=、<>、<、>、<=、>=、IS NULL、IS NOT NULL
- 布尔运算符:AND、OR、XOR、NOT
- 字符串运算符:+、=~
- 列表运算符:+、IN
语句
- 读语句:MATCH、OPTIONAL MATCH、WHERE、START、Aggregation、LOAD CSV
- 写语句:CREATE、MERGE、SET、DELETE、REMOVE、FOREACH、CREATE UNIQUE
- 通用语句:RETURN、ORDER BY、LIMIT、SKIP、WITH、UNWIND、UNION、CALL
- 字符串匹配:STARTS WITH、ENDS WITH、CONTAINS
函数
- 断言函数all、any、none、single、exists
- 标量函数size、length、type、id、coalesce
- 列表函数
- 数学函数
- 字符串函数
- 自定义函数
LOAD CSV
检索架构
一、有大量存量数据(亿级以上)(并长期有增量数据进入)
1、使用NEO4J + ELASTICSEARCH(Neo4j提供ES插件,类似还有Apache Spark、MongoDB、Cassandra插件等)
二、无大量存量数据或者少量存量数据(或全部为增量数据)
1、建立全文检索之后,设置索引同步更新即可(对于大量数据的索引重建比较费时)。
2、建立全文检索之后(使用自定义支持中文的全文索引过程),设置增量入库数据同步更新到索引即可(索引的重建如果做不好优化将会比较费时)。
应用集成
- Java
org.springframework.boot spring-boot-starter-data-neo4j
- .NET
- JavaScript
- Python
- Go
- Ruby
- PHP
- Erlang & Elixir
- Perl
可视化界面
- Neo4j DeskTop

- Neo4j Browser