信息检索19-20章
信息检索19-20章
19.Web 搜索基础
背景与历史
Web 的使用往往基于一个简单开放的客户端-服务器(client-server) 机制就可以实现:
- 服务器通过某个轻量级的协议(HTTP(Hypertext Transfer Protocol,超文本传输协议)和客户端通讯,该协议是异步的,并且可携带各种内容(开始是文本、图像,后来随着时间的推移出现了更丰富的包含 音频、视频在内的媒体格式),这些媒体通过一个简单的 HTML(Hypertext Markup Language,超文本标记语言)标记语言来编码;
- 客户端通常是浏览器。有关 Web 信息发现的早期尝试可以归成两类:(i)像 Altavista、Excite 和 Infoseek 一样的基于全文索引的搜索引擎;(ii) 诸如 Yahoo!的 Web 网页分类体系。前者在前台给用户提供了关键词搜索界面,而在后台则采用前面介绍的倒排索引和排序机制。后者可以允许用户沿树形结构的类别体系进行浏览。
Web的特性
Web最大的一个特点就是网页爆炸式的增长,其最根本原因在于无法集中控制的无中心的网页内容发布机制,其中静态网页(static web page),指的是那些内容不会因请求不同而不同的网页; 动态网页(dynamic page)通常是由应用服务器应答数据库的查询需求时产生的。
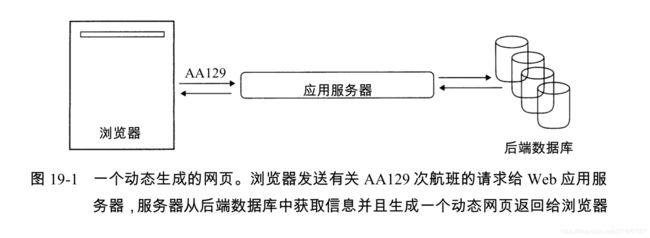
Web 图
我们可以将整个静态 Web 看成是静态HTML 网页通过超链接互相连接而成的有向图,其中每个网页是图的顶点,而每个超链接则代表一个有向边。
我们将指向某个网页的链接称为入链接(in-link),而从某个网页指出去的链接称为出链接(out-link)。一个网页的入链接数目被称为这个网页的入度(in-degree),同样,我们可以定义某个网页的出链接数目为其出度(out-degree)。
如果每个网页都是随机均匀地 选择链接目标时,那么链接到一个网页的链接数目应该满足泊松分布,但是实际中的数目并不满足预想的泊松分布。实际上,有大量研究表明这个分布满足幂分布定律(power law)。
另外,一些研究表明,整个Web有向图结构是个蝴蝶结(bowtie)形,其中主要包含三大类网页,分别是IN、OUT和SCC。Web冲浪者能够从IN中的任一网页出发通过超链接到达SCC的任一网页。同样,冲浪者可以从 SCC中的网页达到OUT中的任一网页。最后,从SCC中的任一网页可以到达SCC中的其他网页。 然而,不可能从SCC中的网页到达IN的任一网页,也不能从OUT中的网页到达SCC中的任一网页(当然此时也不能到达IN中的任一网页)。剩余的网页构成了所谓管道(tube),它由少部分 SCC 之外的网页组成,可以直接将 IN 和 OUT 中的网页相连。另外,还有一些不能从 IN 到达或者不能到达 OUT 的网页构成的所谓卷须(tendril)。
作弊网页
作弊网页是指通过一些手段来使网页以不合理的方式出现在搜索引擎排名更高的地方的网页。
- 第一代作弊网页:通过操作网页内容来达到在某些关键词的搜索结果中排名较高的目的。
- 伪装(cloaking):根据 http 请求是来自搜索引擎的采集器还是用户所使用的浏览器,作弊 Web 服务器会返回不同的网页结果。如果是前者,那么会返回一个包含欺骗性关键词的作弊网页供搜索引擎索引。

- 桥页(doorway page):包含了精心挑选的文字和元信息,通过这些信息能够针对某些选定的搜索关键词来提高排名。当某个浏览器请求访问桥页时,它会重定向到一个更具商业性的网页。
广告经济模型
在 Web 发展的早期,公司会将图形化的广告横幅放在流行的网站上。这些广告会按照 CPM(Cost per Mil,每千次显示会费)或者CPC(Cost per Click,每次点击付费)这两种机制付费。这种模式的搜索引擎在后来被称为赞助搜索(sponsored search)或者搜索广告(search advertising)。
搜索用户体验
Web搜索中的平均查询关键词个数大概是2到3个,并且用户很少使用语法操作符(布尔连接符、通配符等)。
为此Google 确定了2个原则:
- 关注相关性,特别是排名靠前的一些结果的正确率而不是召回率
- 用户体验要轻量级,也就是说查询页面和返回结果页面应该简洁整齐,并且这些页面上基本没有图像成分,而应该几乎全是文本内容。
用户查询需求
- 信息类查询(informational query)主要查找的是与某个宽泛主题相关的一般信息。
- 导航类查询(navigational query)查找的是用户心目中某个实体的网站或者主页。
- 事务类查询(transactional query)是用户在 Web 上进行事务处理的一个先导型查询,这些事务处理包括产品购买、文件下载或进行预订等。
索引规模及其估计
因为索引规模越大,搜索引擎的覆盖面也越大,所以估计一个搜索引擎的大小是有必要的。有许多方法可以粗略估计两个搜索引擎 E 1 E_{1} E1和 E 2 E_2 E2的索引规模的相对比值。这些方法背后的基本假设是每个搜索引擎都从 Web 中随机、独立、均匀地选择了部分网页进行索引。
捕获再捕获(capture–recapture method) 估计方法:
假定我们从 E 1 E_1 E1的索引中随机选取一个网页,并检验它是否属于 E 2 E_2 E2。同样也可以检验某个从 E 2 E_2 E2中随机选取的网页是否属于 E 2 E_2 E2。根据上述实验,可以得到两个分数 x x x和 y y y,其中 x x x表示从 E 1 E_1 E1中抽出的网页属于 E 2 E_2 E2的比例,而 y y y则表示从 E 2 E_2 E2中抽出的网页属于 E 1 E_1 E1的比例。因此,假定搜索引擎 E i E_i Ei规模用 ∣ E i ∣ |E_i| ∣Ei∣来表示的话,那么有
x ∣ E 1 ∣ ≈ y ∣ E 2 ∣ x|E_1| \approx y|E_2| x∣E1∣≈y∣E2∣
抽样方法——随机查询法 (random query)
- 我们首先需要收集一个 Web词典样本。这可以通过采集 Web 的一部分内容来实现,或者可以采集那些人工编辑的有代表性的 Web 子集考虑从这部词典中随机抽取的两个或者多个词组成的与查询。
- 通过发送一个随机查询给搜索引擎来(几乎)均匀随机地从搜索引擎的索引中选出一个页面。
- 给 E 1 E_1 E1提交一个随机的与查询,从返回页面的前 100 条结果中随机选择一个页面 p p p。然后,我们再从 p p p 中选出 6 到 8 个低频词项组成与查询提交 给 E 2 E_2 E2进行检测。上述过程可以重复多次以便提高估计的精度。
近似重复及 shingling
Web 上包含了大量具有相同内容的重复网页。检测重复最简单的方法就是为每个网页计算出一个指纹(fingerprint),它是整个网页文本的一个很精炼(比如说 64 位)的摘要。然后,一旦发现两篇文档的指纹一样,我们就会检查这两篇文档是否真的相同,如果相同,那么我们就认为其中一篇文档是另一篇文档的副本。但是,在面对 Web 上一个更广泛的被称为近似重复(near duplication) 的现象时,上述的简单方法却并不成功。在很多情况下,一个网页的内容并不会完全等同于另一个网页的内容,而是在某些字符上有点差异。
下面列出一个近似重复的解决方案,该方案主要基于一个被称为搭叠(shingling) 的技术:
- 给定正整数k及文档d的一个词项序列,可以定义文档d的k-shingle为d中 所有k个连续词项构成的序列。
- 例如,考虑文档 a rose is a rose is a rose,它的 4-shingle(在近似重复检测中,k = 4 是一个常用值)为“ a rose is a” 、“ rose is a rose” 及“ is a rose is” ,前两个 4-shingle在文本中都出现两次。直观上看,如果两个文档的shingle集合几乎一样,那么它们就满足近似重复。
下面我们将这种直观性精确化,并开发一种计算和比较所有Web网页之间shingle的高效算法。
令 S ( d j ) S(d_j) S(dj) 表示文档 d j d_j dj 中的 shingle 集合, 令 J a c c a r d Jaccard Jaccard 系数为 ∣ S ( d 1 ) ∩ S ( d 2 ) ∣ / ∣ S ( d 1 ) ∪ S ( d 2 ) ∣ |S(d_1)∩S(d_2)|/|S(d_1)∪ S(d_2)| ∣S(d1)∩S(d2)∣/∣S(d1)∪S(d2)∣记为 J ( S ( d 1 ) J(S(d_1) J(S(d1)
通过计算这种 J a c c a r d Jaccard Jaccard 系数就可以判断 d 1 d_1 d1和 d 2 d_2 d2 是否近似重复,如果该值超过某个预先给定的阈值(比如0.9),那么我们就可以认为它们是近似重复文档,在索引时就会去掉其中一篇文档。 此时我们需要简化 J a c c a r d Jaccard Jaccard 系数的计算复杂度:
- 我们使用某种哈希的形式。首先,我们将所有 shingle 都映射到一个大空间(比如 64 比特位)下的哈希值。令 H ( d j ) H(d_j) H(dj)为所有 S ( d j ) S(d_j) S(dj)中的 shingle 映射出的 64 比特位的哈希值集合,其中 j = 1 j = 1 j=1或 2 2 2。
- 下面我们将采用一个技巧来检测出哪些文档对的 H ( ) H( ) H()集合之间具有 较大的 J a c c a r d Jaccard Jaccard重叠度。 令 π π π 为从 64 比特位整数到
64 比特位整数的一个随机置换 1 1 1。 H ( d j ) H(d_j) H(dj)中所有哈希值的置换结果集合记为 Π ( d j ) Π (d_j) Π(dj),因此对每个 h ∈ H ( d j ) h∈H(dj) h∈H(dj),都存在一个相应值 π ( h ) ∈ Π ( d j ) π (h) ∈ Π (d_j) π(h)∈Π(dj)。 令 x π xπ xπ为 Π ( d ) Π (d) Π(d) 中最小的整数。于是有:
J ( S ( d 1 ) S ( d 2 ) ) = P ( x 1 π = x 2 π ) J(S(d_1)S(d_2))=P(x^ π_1=x^π_2) J(S(d1)S(d2))=P(x1π=x2π)

20.Web 采集及索引
概述
采集器必须提供的功能特点
鲁棒性:Web 中有些服务器会制造采集器陷阱(spider traps),采集器必须要能从这类陷阱中跳出来。
礼貌性:Web 服务器具有一些隐式或显式的政策来控制采集器访问它们的频率。设计采集器时必须要遵守这些代表礼貌性的访问策略。
采集器应该提供的功能特点
分布式:采集器应该可以在多机上分布式运行。
(规模)可扩展性:在增加额外的机器和带宽的情况下,采集器的架构应该允许实现采集率的提高。
性能和效率:采集器应该能够充分利用不同的系统资源,包括处理器、存储器和网络带宽等。
质量:在应答用户查询需求时,大部分 Web 网页的质量都很差,因此采集器应该优先考虑抓取“ 有用” 的网页。
新鲜度:在很多应用中,采集器都处于连续工作状态,也就是说它应该要对原来抓取的网页进行更新。采集器应该能够以接近网页更新的频率来采集网页。
(功能)可扩展性:采集器的设计要能支持其在很多方面方便地进行功能扩展。
采集
超文本采集器基本处理如下:
首先,设定一个或者多个 URL 为采集的种子集合(seed set)。接着,从种子集合中选择一个 URL 进行采集,然后对采集到的页面进行分析,并抽取出页面中的文本和链接(每个链接都链向其他的 URL)。抽取出的文本输给文本索引器,而抽取出的 URL 则加入到待采集 URL 池(URL frontier)中,任何时候 URL 池中放的都是所有待采集网页的 URL。一开始,种子集合会放入 URL 池中,一旦某个 URL 被采集,那么就从池中删除这个地址。整个采集过程可以看成是 Web 图的遍历过程。当然,在连续式采集中,一 个已采集的网页的 URL 还会被重新放到 URL 池中以等待下一次重新采集。
采集器架构
一个简单的采集器由多个模块构成,其中包括五种模块。
- 待采集 URL 池:它包含了当前待采集的 URL(在连续式采集中,某个已经采集过的 URL 可能还会放回到该采集池中以便进行重新采集)。
- DNS 解析模块:它在 URL 抓取网页时用于确定其对应的 Web 服务器的 IP 地址。
- 抓取(fetch)模块:利用 http 协议返回某个 URL 对应的网页。
- 分析(parse)模块:从采集到的网页中抽取文本及链接。
- URL 去重模块:确定某个抽取出的链接是否已在 URL 池中或者最近是否已抓取。
单个 URL 的采集流程
- URL 抓取:首先从 URL 池中选择一个 URL,然后抓取该 URL 对应的网页,抓取到的页面会被写入一个临时存储器中,该网页被分析,文本和链接都被抽取出来。文本(包含标签信息,如黑体词项)信息会传给索引器。
- 检测和过滤:每个抽出的链接信息要经过一系列的检测来判断该链接是否要加入到 URL 池 中。首先,采集线程会检查具有相同内容的另一个 URL 是否已经被采集。下一步,URL过滤器采用多个测试来确定某个抽取出的URL是否应该被URL池收录或排除。
- 规范化处理:URL 必须进行规范化(normalization)处理。
- 查重:如果某个 URL 已经在 URL 池中或者已经被采集(在非连续式采集的情况下),那么就不需要将它再放到 URL 池中。

分布式采集器
思路是在每个采集节点上复制一份 上图 20-1 所示的流程,但是与图 20-1 中的做法相比,这种做法有一点本质的不同,即在 URL 过滤之后,我们要使用一个主机划分器(host splitter)将通过过滤检测的 URL 分配到不同的采 集节点上去。也就说,要采集的主机对象会被分配到不同节点进行采集。修改后的采集流程如 图 20-2 所示。主机划分器的输出结果会输入到分布式系统每个采集节点的重复 URL 检测模块中去。
DNS 解析
每个Web服务器都有一个唯一的IP地址。每个IP地址是 4 个字节组成的序列,通常表示为通过点连接起来的 4 个整数。给定一个文本表示的URL(如www.wikipedia.org),将它转换成IP地址(这里就是207.142.131.248)的过程被称为DNS解析(DNS resolution)或DNS查询(DNS lookup)
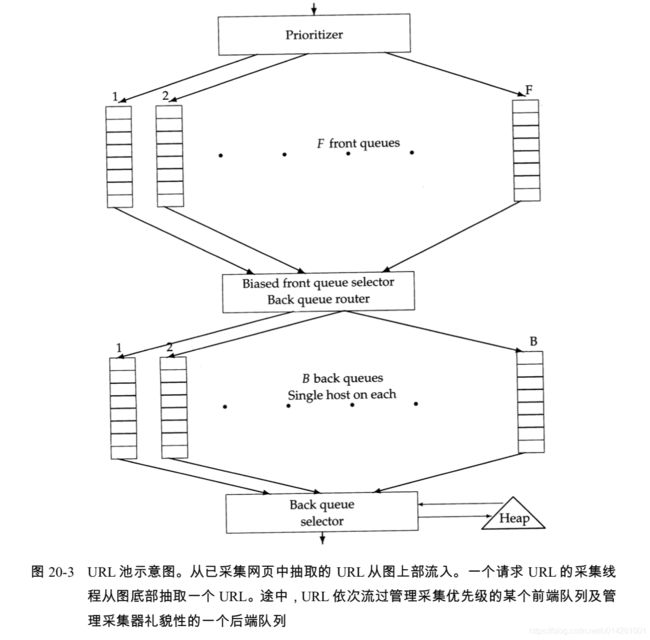
待采集 URL 池
采集进程或其他采集进程的主机分割器会将 URL 放入本节点的 URL 池中。 该采集池会维护一系列 URL,并在采集线程需要寻找 URL 时,以某种次序将 URL 输出。
URL 的输出次序必须要考虑到两个重要的方面:
- 优先性问题,即频繁改变的高质量网页应该优先考虑频繁采集。
- 礼貌问题,即我们必须避免在很短的时间间隔内反复访问同一主机。
下图中的两个主要子模块分别是:上图中的 F 个前端队列(front queues)集合,以及下图中 的 B 个后端队列(back queue)集合。前端队列主要是实现优先级访问功能,而后端队列实现礼貌性访问功能。在 URL 加入到采集池的流程中,会在前端队列和后端队列中走出一条通路。
- 首先,优先级分配器(prioritizer)会基于 URL 的抓取历史(考虑在以往的采集中本 URL 对应的 Web 网页的变化率)赋给该 URL 一个整数 i 表示 其优先级, 其中 i 的取值在 1 到 F 之间。现在,一个 URL 已经被赋予优先级 i,这个 URL 就会添加到第 i 个前端 队列中。
- B个后端队列中的每个队列维持下列固定情况:
- 当采集正在进行时,队列不会为空;
- 队列只包含来自单个主机的URL。
使用一个辅助表T(如图 20-4 所示)来维护从主机到后端队列的映射。当某个后端队列为空并从前端队列重新填充时,T必须进行相应的更新。

此外,我们还维护一个堆结构,其中的每个元素对应一个后端队列,元素值为该队列对应的主机重新访问的最早时间 t e t_e te。
流程如下:
- 某个采集线程在请求 URL 池的一个 URL 时,会从上述堆中取出其根节点,并且等待相应 的时间 t e t_e te。
- 然后,从根节点对应的后端队列 j j j中取出队列首部的 URL u u u,并执行 u u u 的抓取操作。 采集 u u u之后,调用线程会检查 j j j是否为空。如果为空,则选择一个前端队列并取出该队列的首部 URL v v v。在选择前端队列时会倾向于高优先级队列(通常有一个随机过程来实现),即保证高优先级 URL 能够更快地流入到后端队列中。
- 对于 URL v v v,我们会检查在某个后端队列中是否已经包含了来自同一主机的 URL。如果存在,那么 v v v 就会加入到该队列中,这样我们就需要重新回到前端队列来寻找另外一个候选 URL 插入到现在为空的队列 j j j中。该过程不断继续直到 j j j不 再为空。
- 任何情况下,对队列 j j j,线程都会基于其中上次采集的 URL 的属性在堆中插入一个新的最早访问时间 t e t_e te(比如上次访问主机的时间及上次抓取所花的时间),然后继续进行处理。
分布式索引
两种索引实施方法:
- 基于词项的划分(partitioning by terms)方法,也被称为全局的索引组织方法。
- 基于文档的划分(partitioning by documents)方法,也被称为局部的索引组织方法。
普遍使用的方法是按照文档划分:每个节点包含某个文档子集的索引。每个查询都会被分发到所有节点上,来自不同节点的结果在呈现给用户之前会进行合并。该策略在减少节点之间通讯量的同时需要更多的本地磁盘访问次数。
如何将文档划分到节点上去?基于上节所开发的采集器架构,一种简单的方法是将某个主机上的网页分配到一个节点上。这种划分和网页采集时的划分是一致的。
连接服务器
Web 搜索引擎中需要一个连接服务器 (connectivity server)来支持 Web 图连接查询(connectivity query)的快速处理。典型的连接查询包括“ 给定的URL被哪些URL所指向?” 及“ 给定URL指向了哪些URL?” 等。为此,我们在内存中存储了从 URL 到出链及 URL 到入链的映射表。
由于网页数目巨大,我们需要对数据进行压缩,我们的目标不仅仅是将 Web 图压缩到内存中,而且要支持连接查询的高效处理。
在按照词典对所有URL排序时,我们是将每个URL看成一个包含字母数字的字符串并对它们进行排序。图 20-5 给出了这样一种排序的片段。对每个 URL,我们将其在上述排序中的位置设为其唯一编码。
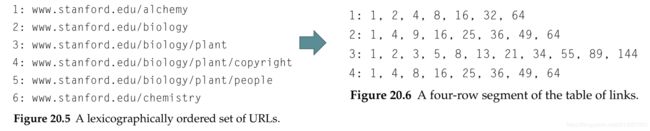
下面我们将利用大部分网站结构化的一些特点来获得相似性和局部性。
大部分网站都有这样一个特点,即网站中每个网页都有一系列链接指向网站中的一些固定页面(比如版权声明、 使用条件等等)。这种情况下,该网站在表格中的网页所对应的行之间就有很多公共元素。此外,在 URL 基于词典排序时,很可能来自同一网站的网页在表格内也会处于连续的行中。于是,我们就可以采用如下策略:
-
从上到下遍历表格,对每一行基于前面的 7 行来编码。这里只使用前 7 行进行编码有如下两个优点:
- 偏移可以通过 3 个比特位来表示
- 将最大的偏移固定在一个较小的值(如上面的7)能够减少搜索原型花费的时间。
-
随之而来的问题就是,如果在前 7 行中都找不到本行的原型怎么办?这种情况下,我们就简单地将本行表示成从一个空集开始并不断加入本行所有整数的过程。我们可以使用间隔编码,即不使用原始整数而是整数之间的间隔来编码,由于文档之间的间隔可能比较紧,所以采用间隔编码可以进一步减少存储空间。
在上述表示下,当考察前 7 行来确定哪行是当前行的原型时,我们需要引入一个当前行和候选行的相似度阈值。如果阈值设置太高,那么就很少会使用原型来表示本行,此时,每行就需要重新表示。如果阈值设置太低,那么大部分行都通过原型来表示,因此,在查询处理时,这种行构造方法就会导致基于原型的多级间接处理。