CART决策树算法总结
CART决策树算法,顾名思义可以创建分类树(classification)和回归树(regression)。
1.分类树。
当CART决策树算法用于创建分类树时,和ID3和C4.5有很多相似之处,但是CART采用基尼指数作为选择划分属性的依据,数据集的纯度用基尼值来度量,具体公式为
Gini(D)=1−∑Ck=1pk ,其中 pk 是第K类样本的概率,C为属性的数量。
直观的来看,基尼值反应了从数据集中随机抽取两个样本,其类别标记不一样的概率,也就是说基尼指数越大,当前数据集合越“混乱”。
对于一个属性a,定义基尼指数(Gini index)的计算公式为
Giniindex(D,a)=∑Vv=1|Dv|/|D|∗Gini(Dv)
于是,在划分属性时,选择使得划分后基尼指数最小的属性作为最优属性。
2.回归树
当CART决策树算法用于回归树时,整个树是一棵二叉树,也就是说对于每一个非叶节点,都有一个划分属性和一个划分的值,根据这个值将当前数据集合划分成两类,要注意的是,在回归树的时候CART并不删除当前属性值,这是因为一个属性可能要划分多次。
回归树其实根据叶子节点的类型又可以分为“回归树”(这里的叫法保持不变)和“模型树”。
具体的来说,回归树的叶子节点是一个常数,通常取训练集合中划分到这个叶子的数据的平均值;而模型树相当于对于每个节点都建立了一个分段直线,也就是说用一段直线来拟合训练数据。
下面是用图片来表示二者的区别
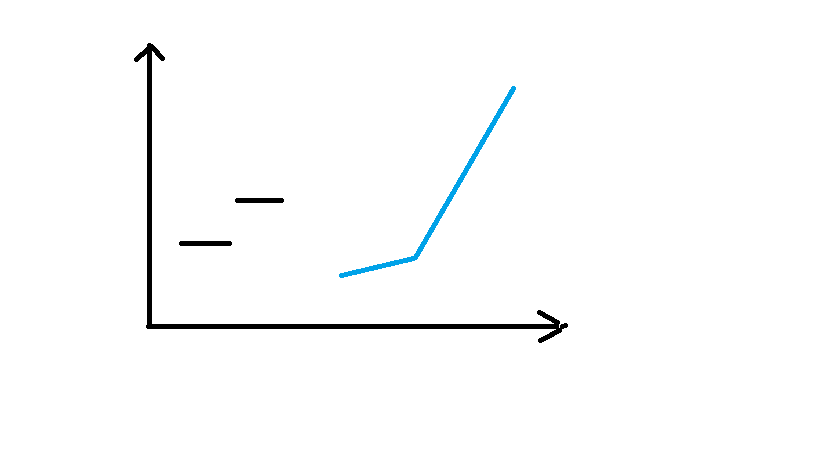
(左侧是回归树,右侧是模型树)
当CART算法用在回归树时,属性的选择就不能用基尼指数了,而是用真实值和预测值的平方差的和来作为度量依据。
3.剪枝操作
在决策树学习算法中,为了尽可能分类训练样本节点划分过程将不断重复,构建出来的数会倾向于过拟合,一棵过拟合树常常十分复杂,这时候就需要剪枝来简化树的结构并提高决策树的泛化能力。
剪枝操作首先将数据集分为训练集和测试集,用训练集来生成决策树,然后用测试机来评价这棵树看是否进行剪枝操作。
剪枝操作分为预剪枝和后剪枝。预剪枝是指在决策数的生成过程中进行的,如果当前决策树不能带来决策树泛化性能的提高,那么停止划分并将当前结点作为叶子节点。后剪枝操作首先生成整棵树,然后自底向上的对非叶子结点进行考察,如果将当前结点替换为叶子节点能带来泛化性能的提高,那么就进行剪枝。
下面是用Python实现的回归树和模型树的代码
from numpy import *
#CART决策树算法
def loadDataSet(fileName):
dataMat = []
fr = open(fileName)
for line in fr.readlines():
curLine = line.strip().split('\t')
# 将原数据映射成浮点数
fltLine = list(map(float, curLine))
dataMat.append(fltLine)
return dataMat
def binSplitDataSet(dataSet, feature, value):
mat0 = dataSet[nonzero(dataSet[:, feature] > value)[0], :]
mat1 = dataSet[nonzero(dataSet[:, feature] <= value)[0], :]
return mat0, mat1
# 模型树的函数
def linearSolve(dataSet):
m, n = shape(dataSet)
x = mat(ones((m, n)))
y = mat(ones((m, 1)))
x[:, 1:n] = dataSet[:, 0:n-1]
y = dataSet[:, -1]
xTx = x.T * x
if linalg.det(xTx) == 0:
raise NameError('This matrix is singular')
ws = xTx.I * x.T * y
return ws, x, y
# 回归树的叶节点,是一个常数
def regLeaf(dataSet):
return mean(dataSet[:, -1])
# 模型树的叶节点,是一个函数
def modelLeaf(dataSet):
ws, x, y = linearSolve(dataSet)
return ws
# 回归树的误差计算公式,也就是所有点与叶节点方差之和
def regErr(dataSet):
return var(dataSet[:, -1])*shape(dataSet)[0]
# 模型树的误差计算公式,所有点与预测值的方差之和
def modelErr(dataSet):
ws, x, y = linearSolve(dataSet)
yHat = x * ws
return sum(power(yHat-y, 2))
# ops两个值用来控制划分的结束,相当于预剪枝
# 第一个只是容许的误差下降值
# 第二个是切分的最少样本数量
def chooseBestFeat(dataSet, leafType=regLeaf, errType=regErr, ops=(1, 4)):
tolS = ops[0]
tolN = ops[1]
# 如果当前集合取值相同,那么不再继续划分
if len(set(dataSet[:, -1].T.tolist()[0])) == 1:
return None, leafType(dataSet)
m, n = shape(dataSet)
currentS = errType(dataSet)
bestFeat = -1
bestS = inf
bestValue = 0
for feat in range(n-1):
valSet = set(dataSet[:, feat].T.tolist()[0])
for val in valSet:
mat0, mat1 = binSplitDataSet(dataSet, feat, val)
# 如果划分的某一个集合太小,则不进行这次划分
if (shape(mat0)[0] < tolN) or (shape(mat1)[0] < tolN):
continue
s0 = errType(mat0)
s1 = errType(mat1)
if s0+s1 < bestS:
bestS = s0+s1
bestFeat = feat
bestValue = val
# 如果最优划分对于误差的减少不大,那么不进行这次划分
if currentS-bestS < tolS:
return None, leafType(dataSet)
return bestFeat, bestValue
def isTree(obj):
return (type(obj).__name__ == 'dict')
def getMean(node):
if isTree(node['left']):
node['left'] = getMean(node['left'])
if isTree(node['right']):
node['right'] = getMean(node['right'])
return (node['left']+node['right'])/2
# 后剪枝
def prune(node, testData):
# 如果当前测试集为空,认为此时发生了过拟合,进行剪枝
if shape(testData)[0] == 0:
return getMean(node)
# 就对测试集合进行划分
lSet, rSet = binSplitDataSet(testData, node['spInd'], node['spVal'])
# 对左右子树进行剪枝
if isTree(node['left']):
node['left'] = prune(node['left'], lSet)
if isTree(node['right']):
node['right'] = prune(node['right'], rSet)
# 如果左右子树都是叶子节点,那么对当前结点进行剪枝
if (not isTree(node['left'])) and (not isTree(node['right'])):
errNoMerge = sum(power(lSet[:, -1]-node['left'], 2)) + sum(power(rSet[:, -1]-node['right'], 2))
nodeMean = getMean(node)
errMerge = sum(power(testData[:, -1]-nodeMean, 2))
if errNoMerge < errMerge:
return nodeMean
return node
def createTree(dataSet, leafType=regLeaf, errType=regErr, ops=(1, 4)):
feat, val = chooseBestFeat(dataSet, leafType, errType, ops)
if feat == None:
return val
retTree = {}
retTree['spInd'] = feat
retTree['spVal'] = val
lSet, rSet = binSplitDataSet(dataSet, feat, val)
retTree['left'] = createTree(lSet, leafType, errType, ops)
retTree['right'] = createTree(rSet, leafType, errType, ops)
return retTree
# 运用树回归进行预测
# 树的结点值
def regVal(node, inData):
return float(node)
def modelVal(node, inData):
n = shape(inData)[1]
x = mat(ones((1, n+1)))
x[:, 1:n+1] = inData
return float(x*node)
# 对单组数据进行预测
def treeForeCast(node, inData, leafVal=regVal):
while isTree(node):
if inData[node['spInd']] > node['spVal']:
node = node['left']
else:
node = node['right']
return leafVal(node, inData)
# 对于输入数据集进行预测
def createForeCast(node, testData, leafVal=regVal):
m = len(testData)
yHat = mat(zeros((m, 1)))
for i in range(m):
yHat[i, 0] = treeForeCast(node, mat(testData[i]), modelVal)
return yHat
#dataSet = mat(loadDataSet('ex2.txt'))
#print(dataSet)
#root = createTree(dataSet, ops=(0, 1))
#testData = mat(loadDataSet('ex2test.txt'))
#print(root)
#root = prune(root, testData)
#print(root['spVal'])
trainMat = mat(loadDataSet('bikeSpeedVsIq_train.txt'))
testMat = mat(loadDataSet('bikeSpeedVsIq_test.txt'))
root = createTree(trainMat, modelLeaf, modelErr, (1, 20))
yHat = createForeCast(root, testMat[:, 0], modelVal)
rSquare = corrcoef(yHat, testMat[:, 1], rowvar=0)[0, 1]
print(rSquare)