初探“大数据分析”
目录
一、导览
1、数据谱图
2、数据分析的各个组成部分
二、数据产出
2.1 哪些行为要打log
2.2 log携带哪些信息
三、数据传输
四、数据存储
4.1 数据仓库设计逻辑
4.2 HDFS/AFS
4.3 Mysql
五、数据计算
5.1 Hadoop框架
5.2 Storm框架
5.3 Samza框架
5.4 Spark框架
5.5 Flink框架
六、数据呈现技术
6.1 实时监控
6.2 报表dashboard
6.3 SQL/查询平台
6.4 Excel
七、数据分析
7.1 宏观分析
7.1.1 Kpi指标
7.1.2 指标拆解
7.1.3 漏斗
7.1.4 渗透率
7.2 用户生命周期分析
7.3 ABtest分析
7.4 Cohort流量分析
7.5 微观用户session分析
一、导览
1、数据谱图
 数据谱图
数据谱图
2、数据分析的各个组成部分
(1)数据产出
(2)数据传输
(3)数据存储
(4)数据计算
(5)数据呈现
(6)数据分析
二、数据产出
这里主要业务和技术一起确定2个问题,技术人员来确保业务的需求通过合适的打点能满足。
2.1 哪些行为要打log
我们恨不得任何行为都打log,但这是不可能的。
业务功能上线的目的是什么,需要用数据说明目的是否达到,最终的行为和关键路径行为打log,才能用数据画出漏斗、分析用户的操作模式。
如果是ABtest,需要有一个ab组可比较的行为log,且打上ab组标记,保证ab同质。a组在一个打点上、b组在另外的打点上,得到的ab两组很可能不同质,得到的结论当然很难说可靠。
2.2 log携带哪些信息
不能一概而论,一般分为“所有打点共有的最基础信息”和“每个打点特有的ext其他信息”。
有个技巧是,如果信息太多log体积太大时,可以编码压缩,在log解析阶段反解出明文落盘入数据仓库;尤其在app端打点更应该如此。
如果是直接产出pb格式log,pb格式设计时预留json的ext字段,可避免频繁改动pb格式。
补充说明,关于打点的执行,事先要确定新增打点不和已有打点重复(确定复用的除外);开发中保证不打印\t\n等特殊字符,且格式不乱能解析(和log解析模块约定并联调);开发完要验证log正确打印。
需要强调的是,如果新增打点信息,那么尽可能不要改动已有信息的字段名、格式,逼不得已要改,必须同步升级log解析模块做兼容。
三、数据传输
App端的log有两种,重要且时效性要求高的行为直接向日志收集服务发请求,在服务端写log;要求不高的先写在手机中,攒够一定大小/超过一定时长集中上传服务器一次。
四、数据存储
数据存储实际上考虑的问题是,冷温热数据放在各自合适的位置,越频繁的数据分析能够越快完成,整体上提升数据分析效率。
4.1 数据仓库设计逻辑
这块内容实际是数据仓库和数据流的设计问题。
一般可以这样做:
(1)原始日志,解析分组
(2)各个维度分布数据
(3)各个维度,按需计算
数据流的设计思路特别简单——用存储换计算。各主题表通常要join其他数据源,比如query需求分类、比如用户画像,如果每天要join多次分析,那就应该预先建个join好的中间表。
拿留存来说,每天都要算次日留存,需要2天的uids,不能每天都把昨天和前天的原始log中的uid去重一次,那就建个每天的uids表。算3日留存、7日留存、月留存、7日区间留存、月区间留存都不再扫原始log。
而每个中间表都尽量携带更多信息,方便分析使用。比如uids表携带当天pv、首次time、末次time等不会影响uid主键的信息;uids_week还携带过去7天活跃天数等。
4.2 HDFS/AFS
hadoop的存储部分,HadoopDistributedFileSystem,对使用用户来说,它就是个文件系统。
AFS是新一代文件系统,功能上可以替代hdfs。所以,使用用户无需关心hdfs和afs的区别,就关心哪些数据存储到哪里就行了。
4.3 Mysql
前一节的存储,都是明细大数据的存储,查询耗时从小时到秒级不等,查询能力越快消耗资源越大。数据流处理到越靠后,汇总粒度越大,汇总数据量越小,所需保持时间越长,mysql是最佳选择,G级别的秒级查询。
汇总数据存入mysql,可以有个好听的名字,叫数据立方体data cube。
五、数据计算
5.1 Hadoop框架
提起大数据,第一个想起的肯定是Hadoop,因为Hadoop是目前世界上应用最广泛的大数据工具,他凭借极高的容错率和极低的硬件价格,在大数据市场上风生水起。Hadoop还是第一个在开源社区上引发高度关注的批处理框架,他提出的Map和Reduce的计算模式简洁而优雅。迄今为止,Hadoop已经成为了一个广阔的生态圈,实现了大量算法和组件。由于Hadoop的计算任务需要在集群的多个节点上多次读写,因此在速度上会稍显劣势,但是其吞吐量也同样是其他框架所不能匹敌的。
5.2 Storm框架
与Hadoop的批处理模式不同,Storm采用的是流计算框架,由Twitter开源并且托管在GitHub上。与Hadoop类似的是,Storm也提出了两个计算角色,分别为Spout和Bolt。
如果说Hadoop是水桶,只能一桶一桶的去井里扛,那么Storm就是水龙头,只要打开就可以源源不断的出水。Storm支持的语言也比较多,Java、Ruby、Python等语言都能很好的支持。由于Storm是流计算框架,因此使用的是内存,延迟上有极大的优势,但是Storm不会持久化数据。
5.3 Samza框架
Smaza也是一种流计算框架,但他目前只支持JVM语言,灵活度上略显不足,并且Samza必须和Kafka共同使用。但是响应的,其也继承了Kafka的低延时、分区、避免回压等优势。对于已经有Hadoop+Kafka工作环境的团队来说,Samza是一个不错的选择,并且Samza在多个团队使用的时候能体现良好的性能。
5.4 Spark框架
Spark属于前两种框架形式的集合体,是一种混合式的计算框架。它既有自带的实时流处理工具,也可以和Hadoop集成,代替其中的MapReduce,甚至Spark还可以单独拿出来部署集群,但是还得借助HDFS等分布式存储系统。Spark的强大之处在于其运算速度,与Storm类似,Spark也是基于内存的,并且在内存满负载的时候,硬盘也能运算,运算结果表示,Spark的速度大约为Hadoop的一百倍,并且其成本可能比Hadoop更低。但是Spark目前还没有像Hadoop哪有拥有上万级别的集群,因此现阶段的Spark和Hadoop搭配起来使用更加合适。
5.5 Flink框架
Flink也是一种混合式的计算框架,但是在设计初始,Fink的侧重点在于处理流式数据,这与Spark的设计初衷恰恰相反,而在市场需求的驱使下,两者都在朝着更多的兼容性发展。Flink目前不是很成熟,更多情况下Flink还是起到一个借鉴的作用。
六、数据呈现技术
6.1 实时监控
主要是针对实时数据流。
其实说这是数据计算也可以,不过这个计算通常只是简单的计数,更多的是数据怎么实时传输和计数,然后实时呈现出来便于及时发现流量波动。相比而言,上一部分的数据计算更偏重业务分析。
也因为计算逻辑简单,可以架设一条数据流专线。
| A数据产出 | B 传输 | C 计算 | D 存储 | E 呈现 |
| 线上每个pv打出一条log给消息队列 | 各种传输方式 |
订阅消息,一条log对mysql中该分钟的pv计数+1 #这里对mysql压力较大,可以攒N条update+N |
方便改值的Mysql | 动态数据或者html页面级刷新 |
6.2 报表dashboard
主要是针对基础指标、需要频繁查看的数据。
这是有固定套路的,需要有菜单、筛选项、图表、表格。
6.3 SQL/查询平台
主要是针对自主查询。
报表dashboard可以认为是宏观数据的监控,对业务整体状态做到心中有数。对业务分析来说,这远远不够。
|
|
写MapReduce代码统计分析 | SQL查询平台 | 工具化查询平台 | 报表dashboard |
| 灵活性 | 高 | 高 | 中 | 低 |
| 分析效率 | 没有效率可言 | 低 | 中 | 高 |
而为啥把一个查询平台放在数据呈现环节来说呢?所谓的呈现,是人-数接口,监控和报表的人数接口是page页面的图表和表格,SQL查询平台相当于以数据明细+自由获取方式暴露给分析人员。
当分析人员有了分析思路,需要获取数据时,sql查询平台要解决几个问题。
1、所需数据的元信息方便可得(数据在哪儿);
2、写出sql能被执行(能够触达数据);
3、方便的任务管理(sql共享和复用)。
进一步的,频繁查询的任务继续封装成工具,不用每次都改sql提交,直接在页面点点点获取数据。
6.4 Excel
主要是针对Excel各种图。
简单又强大。与SQL查询工具配合,玩数据于掌中轻松又愉快。实际上,玩excel主要玩的是透视表和图表,用来补足sql的短板。
七、数据分析
前面是数据分析的基石,如果基石不稳,会严重影响数据分析的效率和结论的完备性。牢靠的基石,是需要灵魂的,否则技术酷炫的呈现,对业务没有正向作用都是枉然。
那些只是工具,你更需要的是数据分析。“我要分析什么”来指导“我要怎样用好分析工具”。事实上,分析并不难,你只需要把合适的数据摆出来,旁边放上合适的对标数据,或者在脑子里对标其他数据,你就是在做分析了。就是说,“分”做好了,“析”是水到渠成的。再从分析到结论,就需要业务人员协助了,或者分析人员本身就非常熟悉业务。
下面是几大类分析,当然分类标准并不严格,提升业务时,也很难说只用一类分析搞定。一般业务要做一件事之前,先做摸底探知收益空间、然后设计ab实验上线、用户行为符合预期且收益达到预期就转全;日常的分析则是持续观察宏观指标、随时关注流量波动并定位原因;不定期的做用户生命周期为主的分析,做大盘渗透率为主的分析等等,目标都是提升业务。
7.1 宏观分析
主要是对kpi相关指标的趋势、拆解、产品体验漏斗的分析。
7.1.1 Kpi指标
这些最频繁的数据分析,一般都有报表来承载,不需要投入分析人力。
7.1.2 指标拆解
PV=UV*avgPV,uv可以按时段、地域、性别年龄、教育水平等基础属性拆,也可以按新老用户、轻中重度用户等产品使用情况拆。不过宏观指标的纬度拆分,需要做diff才能有更大价值,见后面的cohort分析。
7.1.3 漏斗
漏斗分析最简单,也最容易找出产品问题。展现到点击,漏走了80%,能做哪些提升?进入产品后50%的用户没产生有效行为,能做哪些提升?有效用户的次日留存达到80%,留存体验问题暂时可以不用太操心。
粘性指标实际上也是一种漏斗,月活>周活>日活。
7.1.4 渗透率
大盘某个纬度上的分布如何,产品在这个维度上不同人群中已经覆盖了多大比例,这个数据信息量比较大,在表格里很难分析出有价值信息。我们放一个二维气泡图,横轴是不同人群的大盘蛋糕,纵轴是渗透率现状
 渗透图
渗透图
7.2 用户生命周期分析
主要是对活跃,留存,粘性,dau等等的分析。
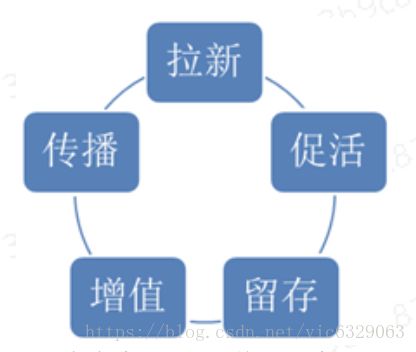
这5块内容,是《增长黑客》300页书的核心内容,书中更多的是围绕5块内容描述各种成功的案例,实际数据分析中,则需要逐个分析现状和提升空间,然后通过验证提升措施,逐渐积累知识。
拉新促活留存增值传播每个环节都可以设计相应的指标,进行现状和提升空间分析,然后通过验证增长措施。
比如用户活跃度及留存的指标,这个固定的套路可以例行做成报表。
7.3 ABtest分析
主要是对用户对新功能的反应等等的分析。
当你通过分析论证决定要做一个升级,就要用小流量abtest了。线上随机圈定2+组同质流量,a组流量命中升级版,b组用户只打流量标记,命中原版。新版的改动预期就是提升pv的,于是你观察ab两组用户的pv,喜闻乐见的折线如下图,新版大幅提升流量。
7.4 Cohort流量分析
主要是对趋势、波动等等的分析。
Cohort analysis是群体分析,就是把用户按某种方式分成不同的群体,分析不同群体的表现,从中发现知识。这个概念火起来没多久,Growthhacking概念就起来了,cohort就很少人提了。但cohort分析的具体执行上,与流量波动分析不谋而合。
试问,2号比1号pv增长了20%,为啥?
要回答这个问题你只看2个总数是回答不来的,一定需要进行维度下钻,实质上这就是在分群了。把维度或维度组合抽象成分群依据,维度值抽象成群体描述,然后对比维度值的diff,就是一个找流量波动原因的过程。
7.5 微观用户session分析
主要是对用户画像等等的分析。
随机抽取一部分用户,去观察每个用户的行为,而不是站在IT从业者的视角凭空猜想几亿网民使用产品的方式。
进一步的,你还能知道怎么样使用产品的用户有多大比例,“怎么样使用产品”可不是一两个宏观指标能看出来的。