决策树模型
决策树(DecisionTree, DT)是一种常见的用于分类和回归的非参数监督学习方法,目标是创建一个模型,通过从数 据特性中推导出简单的决策规则来预测目标变量的值。
决策树模型的优点在于:1,简单容易理解,数据结构可以可视化表达。2,需要很少的数据准备,其他技术通常需 要数据标准化,需要创建虚拟变量,并删除空白值。3,能够处理多输出问题。 决策树模型的缺点在于:1,决策树学习可能会生成过于复杂的数结构,不能代表普遍的规则,即模型容易过拟 合,修剪机制,设置叶子节点所需的最小样本数目或设置树的最大深度是避免决策树过拟合的必要条件。2,决策 树可能不稳定,因为数据中的小变化可能导致生成完全不同的树。这个问题可以通过在一个集合中使用多个决策树 来减轻。3,实际的决策树学习算法是基于启发式算法的,例如在每个节点上进行局部最优决策的贪婪算法。这种 算法不能保证返回全局最优决策树。通过在集合学习中训练多个树,可以减少这种情况,在这里,特征和样本是随 机抽取的。
#分析数据
from sklearn import datasets
# sklearn自带的datasets中就有Boston房价数据集
housing_data=datasets.load_boston()
dataset_X=housing_data.data
# 获取影响房价的特征向量,作为feaure X
dataset_y=housing_data.target # 获取对应的房价,作为label y #
print(dataset_X.shape) # (506, 13)
# 一共有506个样本,每个样本有13个features #
print(dataset_y.shape) # (506,)
print(dataset_X[:5,:]) # 打印看看features的数值类型和大小,貌似已经normalize.
# 上面的数据集划分也可以采用下面的方法:
from sklearn.model_selection import train_test_split
train_X,test_X,train_y,test_y=train_test_split(dataset_X,dataset_y,test_size=0.2,random_state=37 )
#构建数据模型
from sklearn.tree import DecisionTreeRegressor
decision_regressor = DecisionTreeRegressor(max_depth=4)
decision_regressor.fit(train_X,train_Y)
#用决策树预测新数据,并打印分数:MSE和解释方差分
y_pre_trainY=decision_regressor.predict(test_X)
from sklearn import metrics
#误差越小,模型越好,得分越大,模型越好
print("均方误差MSE:{}".format(metrics.mean_squared_error(y_pre_trainY,test_Y)))
print("解释方差分:{}".format(metrics.explained_variance_score(y_pre_trainY,test_Y)))
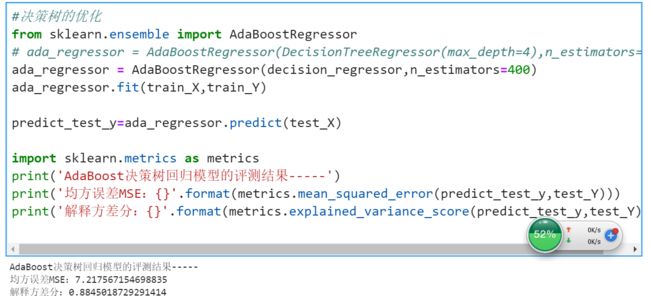
决策树模型的优化
一般的,可以先从数据集上优化,但本项目的数据集是非常成熟的案例,进一步优化的空间不大,所以只能从模型 上下手。此处我采用两种优化方法,第一种是优化决策树模型中的各种参数,比如优化max_depth,判断是否可以 改进MSE,第二种方式是使用AdaBoost算法来增强模型的准确性。