QDD检测框架系列(2)——Pyramid Scene Parsing Network
最近不太忙,还是有必要趁着空把学习的东西都记录下来的。
Pyramid Scene Parsing Network,又称PSPNet,这是2016年CVPR上的一篇文章,为什么会看到这么早的文章呢,这其中肯定是有原因的,因为在完成某项工作的时候,一开始使用的是物体检测的框架,后来发现某些需求没有办法满足,所以就想,那我能不能使用场景分割的框架呢,于是同时就推荐了这个网络,一试效果还不错。所以决定把它记录下来。
也许,看到这里有的同学就已经晕了,目标检测和场景分割,这个不是一个框架嘛,都是为了获取mask,他们之间有什么差距呢?为什么一个可以,一个就不可以?
我在这里给出解答,原因是目标检测的框架,比如说maskrcnn,它的mask是在bbox里面进行mask的估计,影响mask生成结果的一个很重要的原因是anchor的比例。所以在面对某些特殊场景的时候,基于maskrcnn的分割效果是不好的。但是pspnet这种不基于box,直接像素级的生成mask,效果就会好很多。粗糙的讲了讲,大家可以自己细细得再去琢磨琢磨。
下面进入正文,讲PSPnet:
1、什么是场景分割
基于语义分割的场景分析是计算机视觉中的一个基本课题,其目的是为图像中的每个像素指定一个类别标签。场景分析提供了对场景的完整理解,预测了每个元素的类别、位置和形状。目标大致如下图所标注这样,希望将一个自然的场景,里面的不同类别用不同的颜色进行逐像素的标注工作。

场景分割在现实中也有着十分广泛的应用,对于自动驾驶、机器人传感技术、以及一些虚拟现实的技术来说具有广泛的研究意义。
2、 场景分割的现状
目前来讲,场景分割还存在许多的挑战。比如说,目前常用的场景分割的主要框架还是基于全卷积网络进行的,这种方法提高了网络对于图片的理解能力,提高了网络场景分割的能力,但是同时,我们也需要认识到,目前来说,整个网络还是存在着许多的不足的,比如现实中的场景以及需要分割的种类几乎是无穷无尽的,我们没有办法让网络能够分出所有的种类。
对于一些形状,性质比较相近的场景,即使是专家标注也会产生比较大的误差,人都尚且不能完成认识的过程,我们又怎么能苛求网络去必须做到呢?还有就是网络其实并没有做到理解这个动作,比如他会把道路上的车识别为轮船,这在我们人类看来简直搞笑,但是机器是真的会犯这样的低级错误,追踪到底还是我们训练网络的时候,他只是记住了那些特征,但是他并没有理解这些特征的意思以及特征之间的关联性。
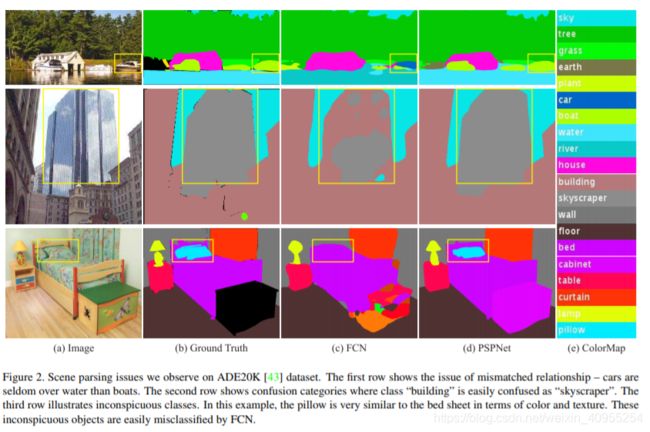
作者在文中也总结了,目前复杂情况下的场景分割存在的一些问题。
a)语境关系的不匹配是一个普遍存在的问题,尤其在对复杂场景的理解中极为重要。我们可以从生活常识中得出这样的结论:有些物体常常是一起出现的,例如,飞机很可能在跑道上或在空中飞行,而不是在公路上。对于上图中的第一行示例,FCN根据外观将黄色框中的船预测为“汽车”,但众所周知,汽车很少在河上行驶。所以,缺乏收集语境信息的能力会增大错误分类的概率。
b)类别混淆 ADE20K数据集中有许多类别标签在分类时容易出现混淆。例如:田野和土地;山脉和丘陵;墙、房子、建筑物和摩天大楼,它们的外观十分相似。有的时候即使专家注释员标记了整个数据集,仍然会产生17.60%的像素误差。在图2的第二行中,对于框中的物体,FCN预测其部分是摩天大楼,部分是建筑物。这些结果是不正确的,框中的整个物体只能要么是摩天大楼,要么是建筑物,但不能两者兼有,而利用类别之间的关系即可解决上述问题。
c)不明显的类别 一般来说,我们会发现真实场景中,包含的物体他们的大小差异性会由于距离相机的距离,视角,光照,物体实际大小等原因,一些特别大,一些特别小。比如路灯和标识牌,这些在场景中也许都十分重要,但是由于比较小,很难被找到,又比如巨大的树,楼,由于超出了FCN的感受野,也很难被发现。第三类就是枕头和床单,由于位置,花纹什么的都很相似,从而导致无法被分割出来。
3、本文的工作
为了融合全局特征,提出了PSPnet,又称金字塔场景分割网络,为此专门设计了全局金字塔池话模块。使用局部和全局的信息进行融合,使得整个网络的性能更加可靠。此外文中还提出了一种深度监督损失函数的优化策略。
3.1金字塔模块
有人在文章中提出来可以使用金字塔池化生成的不同级别的特征图最终被展平并拼接起来,然后输入到全连接层中进行分类。该全局先验模块是为消除CNN进行图像分类时需输入固定尺寸图像的这一约束而设计的。
为了进一步避免丢失表征不同子区域之间关系的语境信息,我们提出了一个包含不同尺度、不同子区域间关系的分层全局信息。如图3中(c)部分所示,将该金字塔池化模块的输出作为深度神经网络最终的特征图,并称其为全局场景先验信息。

上图中使用虚线标注出来的就是金字塔模块。可以轻松地看出金字塔池化模块融合了四种不同尺度下的特征。图中用红色突出显示的为最粗略的层级,是使用全局池化生成的单个bin输出。剩下的三个层级将输入特征图划分成若干个不同的子区域,并对每个子区域进行池化,最后将包含位置信息的池化后的单个bin组合起来。金字塔池化模块中不同层级输出不同尺度的特征图,为了保持全局特征的权重,我们在每个金字塔层级后使用1x1的卷积核,当某个层级维数为n时,即可将语境特征的维数降到原始特征的1/n。然后,通过双线性插值直接对低维特征图进行上采样,使其与原始特征图尺度相同。最后,将不同层级的特征图拼接为最终的金字塔池化全局特征。
同时文中作者还提示我们应该注意到金字塔的层数和每个层级相应尺度的大小都是可以修改。该结构通过采用不同大小的池化核,通过简单几步即可提取出不同的子区域的特征,因此,多层级的池化核大小应保持合理的间隔。我们的金字塔池化模块是一个四层级的模块,分别有1x1、2x2、3x3和6x6的bin大小。
3.2整体网络介绍
以上述所说的金字塔模块作为基础,作者提出了PSPnet,如上图3所示。整个网络的pipeline如下所示,首先输入一幅图像,我们使用一个CNN网络(残差)来提取特征,然后获得第一阶段的特征图。然后我们再使用金字塔模块对特征图提取多尺度的信息,这里的多尺度一共有四个尺度,然后将这些信息与特征图融合到一起,形成了全局特征。然后最后再将这个特征通过一层卷积层得到最后的预测图。
总结
整个文章的框架以及其他部分,其实都很naive,但是却胜在实用,我在和师兄讨论这个问题的时候,师兄推荐了另外一篇文章ASPP,这篇文章中将金字塔结构换成了不同大小的空洞卷积,结构如下,效果类似,大家可以参考参考

嗯,今天就到这里啦,这个月写两篇了,我要多写,把上个月的补上来。
学术交流可以关注我的公众号,后台留言,粉丝不多,看到必回。卑微小钱在线祈求
