GAN、CGAN、DCGAN、Cycle GAN、SAGAN、WGAN、StarGAN
GAN:
值函数(评价函数,非损失函数):
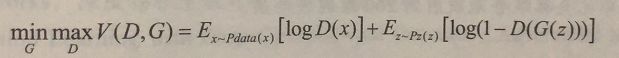
x表示真实图片,z表示输入噪声,x~Pdata(x)与x~Pz(z)表示满足各自的分布律。理想状态下,D(G(Z))=0.5
更新方式:
交替训练G(Generator)和D(Discriminator), D加梯度,G减梯度

简单讲一下上面两个公式,m指样本个数,从评价函数出发:
第一个公式,更新的是D的w(![]() )
)
第二个公式,更新的是G的w(![]() )
)
CGAN条件对抗生成网络:
参考网址:https://blog.csdn.net/stalbo/article/details/79359380
输入增加额外信息y。在mnist数据集上进行CGAN的实验,G网络输入是z噪声及标签y,输出为假图片向量。D网络输入是图像向量和标签y,输出是来自mnist数据集的概率
目标函数是带有条件概率的二元极小极大博弈,x是mnist数据集的图片向量

DCGAN深度卷积生成对抗网络:
CNN(2个CNN替换了D和G)与GAN的结合。

stride代替pooling实现了G的可微,使评价函数平滑收敛
应用: 生成卡通头像
代码链接:https://zhuanlan.zhihu.com/p/24767059
爬虫爬取图站图像——用opencv裁出头像(用了detectMultiScale方法多尺度检验人脸)——用自己的数据集训练及测试
Cycle GAN
F(G(X))=X
G(F(Y))=Y
用循环一致性损失
self-attention GAN(SAGAN) 带自注意力机制的生成对抗网络
https://blog.csdn.net/zhangyumengs/article/details/80555523
http://baijiahao.baidu.com/s?id=1602505761971177843&wfr=spider&for=pc
https://www.jianshu.com/p/0540fb554088
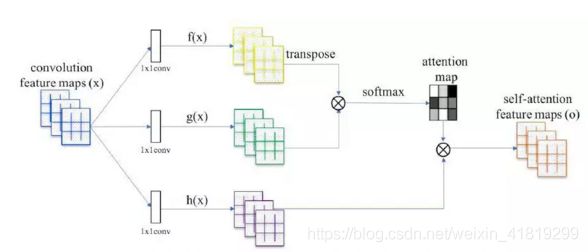
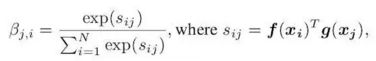
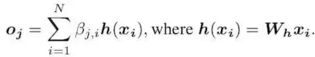
![]() γ从0开始变大
γ从0开始变大
![]()
Βj,i表示模型在合成第j个区域时对第i个位置的关注程度
spectral normalization谱归一化
Wasserstein GAN(WGAN)
https://www.cnblogs.com/Charles-Wan/p/6501945.html
https://blog.csdn.net/zhl493722771/article/details/82781914
https://blog.csdn.net/qq_25737169/article/details/78857788
https://zhuanlan.zhihu.com/p/25071913
https://www.cnblogs.com/ranjiewen/p/9201631.html
《深度学习入门之Pytorch》
GAN的问题:
在优化判别器时,为衡量生成样本与 真实样本的差异时,引入了JS散度JSD越小说明两种分布越接近。当两种分布没有重叠或重叠很小时,JSD恒等于常数log2,梯度消失,无法进一步优化。换句话说,判别器训练得太好,分布不重叠,梯度消失;判别器训练得不好,错误的优化方向。判别器不好不坏最好。
真实样本是一个高维分布,生成样本是一个低维分布。此外,不可能真正去计算两个分布,只能近似取样,导致两个分布可能没有重叠部分。

引入Wasserstein距离替换JS散度衡量两个分布差异。



相比原始GAN改进了4点:
- 判别器最后一层去掉sigmoid(WGAN做的是回归问题,而原始GAN做的分类问题)
- 生成器和判别器的loss不取log
- 每次更新判别器的参数之后把它们的绝对值截断到不超过一个固定常数c(权重裁剪)
- 不要用基于动量的优化算法(包括momentum和Adam),推荐RMSProp,SGD也行(作者的实验结论)
引入权重裁剪的目的:
满足一阶Lipschitz连续性,使关于输入的样本,D输出变化比较平稳。引入一阶Lipschitz连续性是为了将一个无法求解的inf问题转换为求max问题。

WGAN提出使用wassertein距离作为优化方式训练GAN,但是数学上和真正代码实现上还是有区别的,使用Wasserteion距离需要满足很强的连续性条件—lipschitz连续性
Improving WGAN
WAN为满足一阶lipschitz连续性,使用了权重衰减的方法。将一阶lipschitz连续性等价于梯度范数处小于1


STARGAN(星型网络)
https://blog.csdn.net/weixin_42445501/article/details/82748225
该2018CVPR做了变换表情方面的工作
多数据集训练用来CelebA(肤色、年龄)和 RaFD(表情),这两个数据集内容相交但类别不相交,使用Mask vector对标记进行处理,如下所示:
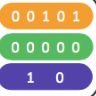
第一行代表CelebA属性,第二行代表RaFD属性,第三行为数据集one-hot标签
参考链接:
https://zhuanlan.zhihu.com/p/24767059