Python-scipy 笔记整理
笔记整理,供自行学习使用
Reference:
https://vitu.ai/courses/lesson/65600627429901184/65598890065315648
https://zhidao.baidu.com/question/309834209.html
https://www.cnblogs.com/hirokuh/p/9335200.html
某速查表
导包
import numpy as np
import scipy.stats as stats
import scipy.optimize as opt
统计
标题2.1 生成随机数
我们从生成随机数开始,这样方便后面的介绍。生成n个随机数可用rv_continuous.rvs(size=n)或rv_discrete.rvs(size=n),其中rv_continuous表示连续型的随机分布,如均匀分布(uniform)、正态分布(norm)、贝塔分布(beta)等;rv_discrete表示离散型的随机分布,如伯努利分布(bernoulli)、几何分布(geom)、泊松分布(poisson)等。我们生成10个[0, 1]区间上的随机数和10个服从参数=4,=2的贝塔分布随机数:
#stats.分布类型.rvs(参数)
rv_unif = stats.uniform.rvs(size=10)
print(rv_unif)
rv_beta = stats.beta.rvs(size=10, a=4, b=2)
print(rv_beta)
[0.84772492 0.51058721 0.7942104 0.36178878 0.16336951 0.37133914
0.41797924 0.74608254 0.67306172 0.57230642]
[0.53050978 0.88430587 0.68545092 0.65654262 0.94247261 0.55616683
0.80095464 0.89808025 0.40890796 0.3278801 ]
在每个随机分布的生成函数里,都内置了默认的参数,如均匀分布的上下界默认是0和1。可是一旦需要修改这些参数,每次生成随机都要敲这么老长一串有点麻烦,能不能简单点?SciPy里头有一个Freezing的功能,可以提供简便版本的命令。SciPy.stats支持定义出某个具体的分布的对象,我们可以做如下的定义,让beta直接指代具体参数=4和=2的贝塔分布。为让结果具有可比性,这里指定了随机数的生成种子,由NumPy提供。
np.random.seed(seed=2015)
rv_beta = stats.beta.rvs(size=10, a=4, b=2)
print("method 1:")
print(rv_beta)
np.random.seed(seed=2015)
beta = stats.beta(a=4, b=2)
print("method 2:")
print(beta.rvs(size=10))
2.2 假设检验
生成数据
norm_dist = stats.norm(loc=0.5, scale=2)
n = 200
dat = norm_dist.rvs(size=n)
print("mean of data is: " + str(np.mean(dat)))
print("median of data is: " + str(np.median(dat)))
print("standard deviation of data is: " + str(np.std(dat)))
mean of data is: 0.437675174954761
median of data is: 0.3809116799169993
standard deviation of data is: 1.9017812959529896
假设这个数据是我们获取到的实际的某些数据,如股票日涨跌幅,我们对数据进行简单的分析。最简单的是检验这一组数据是否服从假设的分布,如正态分布。这个问题是典型的单样本假设检验问题,最为常见的解决方案是采用K-S检验( Kolmogorov-Smirnov test)。
K-S检验是统计学中在对一组数据进行统计分析是所用到的一种方法。它是将需要做统计分析的数据和另一组标准数据进行对比,求得它和标准数据之间的偏差的方法。一般在K-S检验中,先计算需要做比较的两组观察数据的累积分布函数,然后求这两个累积分布函数的差的绝对值中的最大值D。最后通过查表以确定D值是否落在所要求对应的置信区间内。若D值落在了对应的置信区间内,说明被检测的数据满足要求。反之亦然。
单样本K-S检验的原假设是给定的数据来自和原假设分布相同的分布,在SciPy中提供了kstest函数,参数分别是数据、拟检验的分布名称和对应的参数:
mu = np.mean(dat)
sigma = np.std(dat)
stat_val, p_val = stats.kstest(dat, 'norm', (mu, sigma))
print('KS-statistic D = %6.3f p-value = %6.4f' % (stat_val, p_val))
KS-statistic D = 0.039 p-value = 0.9252
假设检验的-value值很大(在原假设下,-value是服从[0, 1]区间上的均匀分布的随机变量,可参考http://en.wikipedia.org/wiki/P-value ),因此我们接受原假设,即该数据通过了正态性的检验。在正态性的前提下,我们可进一步检验这组数据的均值是不是0。典型的方法是检验(-test),其中单样本的检验函数为ttest_1samp:
stat_val, p_val = stats.ttest_1samp(dat, 0)
print('One-sample t-statistic D = %6.3f, p-value = %6.4f' % (stat_val, p_val))
One-sample t-statistic D = 3.247, p-value = 0.0014
我们看到-value<0.05,即给定显著性水平0.05的前提下,我们应拒绝原假设:数据的均值为0。我们再生成一组数据,尝试一下双样本的检验(ttest_ind):
norm_dist2 = stats.norm(loc=-0.2, scale=1.2)
dat2 = norm_dist2.rvs(size=int(n/2))
stat_val, p_val = stats.ttest_ind(dat, dat2, equal_var=False)
print('Two-sample t-statistic D = %6.3f, p-value = %6.4f' % (stat_val, p_val))
Two-sample t-statistic D = 5.565, p-value = 0.0000
注意,这里我们生成的第二组数据样本大小、方差和第一组均不相等,在运用检验时需要使用Welch’s -test,即指定ttest_ind中的equal_var=False。我们同样得到了比较小的−,在显著性水平0.05的前提下拒绝原假设,即认为两组数据均值不等。
stats还提供其他大量的假设检验函数,如bartlett和levene用于检验方差是否相等;anderson_ksamp用于进行Anderson-Darling的K-样本检验等。
2.3 其他函数
有时需要知道某数值在一个分布中的分位,或者给定了一个分布,求某分位上的数值。这可以通过cdf和ppf函数完成:
g_dist = stats.gamma(a=2)
print("quantiles of 2, 4 and 5:")
print(g_dist.cdf([2, 4, 5]))
print("Values of 25%, 50% and 90%:")
print(g_dist.pdf([0.25, 0.5, 0.95]))
quantiles of 2, 4 and 5:
[0.59399415 0.90842181 0.95957232]
Values of 25%, 50% and 90%:
[0.1947002 0.30326533 0.36740397]
norm.cdf # (Cumulative Distribution Function)计算累积标准正态分布函数
norm.pdf # (Probability Density Function) 概率密度函数
norm.ppf # (Percent Point Function) 百分点函数,概率密度函数的积分值
对于一个给定的分布,可以用moment很方便的查看分布的矩信息,例如我们查看(0,1)的六阶原点矩:
stats.norm.moment(6, loc=0, scale=1)
15.000000000895332
对数据集的统计描述分析,包括数据样本大小,极值,均值,方差,偏度和峰度:
import numpy as np
import scipy.stats as stats
norm_dist = stats.norm(loc=0, scale=1.8)
dat = norm_dist.rvs(size=100)
info = stats.describe(dat)
print("Data size is: " + str(info[0]))
print("Minimum value is: " + str(info[1][0]))
print("Maximum value is: " + str(info[1][1]))
print("Arithmetic mean is: " + str(info[2]))
print("Unbiased variance is: " + str(info[3]))
print("Biased skewness is: " + str(info[4]))
print("Biased kurtosis is: " + str(info[5]))
Data size is: 100
Minimum value is: -4.245209254208455
Maximum value is: 5.436965592219658
Arithmetic mean is: 0.18332414156460872
Unbiased variance is: 3.466535875509111
Biased skewness is: 0.1319216596536725
Biased kurtosis is: 0.15953628443439394
当我们知道一组数据服从某些分布的时候,可以调用fit函数来得到对应分布参数的极大似然估计(MLE, maximum-likelihood estimation)。以下代码示例了假设数据服从正态分布,用极大似然估计分布参数:
norm_dist = stats.norm(loc=0, scale=1.8)
dat = norm_dist.rvs(size=100)
mu, sigma = stats.norm.fit(dat)
print("MLE of data mean:" + str(mu))
print("MLE of data standard deviation:" + str(sigma))
MLE of data mean:-0.18165731132645366
MLE of data standard deviation:1.9147057587843739
pearsonr和spearmanr可以计算Pearson和Spearman相关系数,这两个相关系数度量了两组数据的相互线性关联程度:
norm_dist = stats.norm()
dat1 = norm_dist.rvs(size=100)
exp_dist = stats.expon()
dat2 = exp_dist.rvs(size=100)
cor, pval = stats.pearsonr(dat1, dat2)
print("Pearson correlation coefficient: " + str(cor))
cor, pval = stats.pearsonr(dat1, dat2)
print("Spearman's rank correlation coefficient: " + str(cor))
Pearson correlation coefficient: -0.009896596878874862
Spearman's rank correlation coefficient: -0.009896596878874862
其中的-value表示原假设(两组数据不相关)下,相关系数的显著性。
最后,在分析金融数据中使用频繁的线性回归在SciPy中也有提供,我们来看一个例子:
x = stats.chi2.rvs(3, size=50)
y = 2.5 + 1.2 * x + stats.norm.rvs(size=50, loc=0, scale=1.5)
slope, intercept, r_value, p_value, std_err = stats.linregress(x, y)
print("Slope of fitted model is:" , slope)
print("Intercept of fitted model is:", intercept)
print("R-squared:", r_value**2)
Slope of fitted model is: 1.332841966169289
Intercept of fitted model is: 2.4391780725280694
R-squared: 0.8102424235974711
在前面的链接中,可以查到大部分stat中的函数,本节权作简单介绍,挖掘更多功能的最好方法还是直接读原始的文档。另外,StatsModels(http://statsmodels.sourceforge.net )模块提供了更为专业,更多的统计相关函数。若在SciPy没有满足需求,可以采用StatsModels。优秀的工程师都应该会快读读文档。
优化
优化问题在投资中可谓是根本问题,如果手上有众多可选的策略,应如何从中选择一个“最好”的策略进行投资呢?这时就需要用到一些优化技术针对给定的指标进行寻优。随着越来越多金融数据的出现,机器学习逐渐应用在投资领域,在机器学习中,优化也是十分重要的一个部分。以下介绍一些常见的优化方法,虽然例子是人工生成的,不直接应用于实际金融数据,我们希望读者在后面遇到优化问题时,能够从这些简单例子迅速上手解决。
3.1 无约束优化问题
所谓的无约束优化问题指的是一个优化问题的寻优可行集合是目标函数自变量的定义域,即没有外部的限制条件。例如,求解优化问题
minimize()=2−4.8+1.2
就是一个无约束优化问题,而求解
minimizesubject to()=2−4.8+1.2≥0
则是一个带约束的优化问题。更进一步,我们假设考虑的问题全部是凸优化问题,即目标函数是凸函数,其自变量的可行集是凸集。(详细定义可参考斯坦福大学Stephen Boyd教授的教材convex optimization,下载链接:http://stanford.edu/~boyd/cvxbook )
我们以Rosenbrock函数
![[ f(\mathbf{x}) = \sum_{i=1}^{N-1} 100 (x_i - x_{i-1}2)2 + (1 - x_{i-1})^2 ]](https://img-blog.csdnimg.cn/20200716115609928.png)
作为寻优的目标函数来简要介绍在SciPy中使用优化模块scipy.optimize。
首先需要定义一下这个Rosenbrock函数:
def rosen(x):
"""The Rosenbrock function"""
return sum(100.0*(x[1:]-x[:-1]**2.0)**2.0 + (1-x[:-1])**2.0)
3.1.1 Nelder-Mead单纯形法
单纯形法是运筹学中介绍的求解线性规划问题的通用方法,这里的Nelder-Mead单纯形法与其并不相同,只是用到单纯形的概念。设定起始点0=(1.3,0.7,0.8,1.9,1.2),并进行最小化的寻优。这里‘xtol’表示迭代收敛的容忍误差上界:
def rosen(x):
"""The Rosenbrock function"""
return sum(100.0*(x[1:]-x[:-1]**2.0)**2.0 + (1-x[:-1])**2.0)
x_0 = np.array([0.5, 1.6, 1.1, 0.8, 1.2])
res = opt.minimize(rosen, x_0, method='nelder-mead', options={'xtol': 1e-8, 'disp': True})
print("Result of minimizing Rosenbrock function via Nelder-Mead Simplex algorithm:")
print(res)
Optimization terminated successfully.
Current function value: 0.000000
Iterations: 436
Function evaluations: 706
Result of minimizing Rosenbrock function via Nelder-Mead Simplex algorithm:
final_simplex: (array([[1. , 1. , 1. , 1. , 1. ],
[1. , 1. , 1. , 1. , 1. ],
[1. , 1. , 1. , 1. , 0.99999999],
[1. , 1. , 1. , 1. , 1. ],
[1. , 1. , 1. , 1. , 1.00000001],
[1. , 1. , 1. , 1. , 1.00000001]]), array([1.66149699e-17, 6.32117429e-17, 7.44105349e-17, 8.24396866e-17,
9.53208876e-17, 1.07882961e-16]))
fun: 1.6614969876635003e-17
message: 'Optimization terminated successfully.'
nfev: 706
nit: 436
status: 0
success: True
x: array([1., 1., 1., 1., 1.])
Rosenbrock函数的性质比较好,简单的优化方法就可以处理了,还可以在minimize中使用method='powell’来指定使用Powell’s method。这两种简单的方法并不使用函数的梯度,在略微复杂的情形下收敛速度比较慢,下面让我们来看一下用到函数梯度进行寻优的方法。
更多单纯形法的参考资料请移步baidu or 这里:管理运筹学 韩伯棠 中国大学mooc
3.1.2 Broyden-Fletcher-Goldfarb-Shanno法
Broyden-Fletcher-Goldfarb-Shanno(BFGS)法用到了梯度信息,首先求一下Rosenbrock函数的梯度:
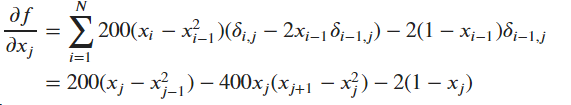
其中当=时,,=1,否则,=0。
边界的梯度是特例,有如下形式:
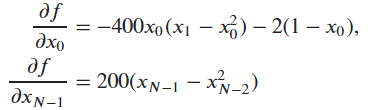
我们可以如下定义梯度向量的计算函数了:
def rosen_der(x):
xm = x[1:-1]
xm_m1 = x[:-2]
xm_p1 = x[2:]
der = np.zeros_like(x)
der[1:-1] = 200*(xm-xm_m1**2) - 400*(xm_p1 - xm**2)*xm - 2*(1-xm)
der[0] = -400*x[0]*(x[1]-x[0]**2) - 2*(1-x[0])
der[-1] = 200*(x[-1]-x[-2]**2)
return der
梯度信息的引入在minimize函数中通过参数jac指定:
res = opt.minimize(rosen, x_0, method='BFGS', jac=rosen_der, options={'disp': True})
print("Result of minimizing Rosenbrock function via Broyden-Fletcher-Goldfarb-Shanno algorithm:")
print(res)
Optimization terminated successfully.
Current function value: 0.000000
Iterations: 39
Function evaluations: 47
Gradient evaluations: 47
Result of minimizing Rosenbrock function via Broyden-Fletcher-Goldfarb-Shanno algorithm:
fun: 1.569191726013783e-14
hess_inv: array([[0.00742883, 0.01251316, 0.02376685, 0.04697638, 0.09387584],
[0.01251316, 0.02505532, 0.04784533, 0.094432 , 0.18862433],
[0.02376685, 0.04784533, 0.09594869, 0.18938093, 0.37814437],
[0.04697638, 0.094432 , 0.18938093, 0.37864606, 0.7559884 ],
[0.09387584, 0.18862433, 0.37814437, 0.7559884 , 1.51454413]])
jac: array([-3.60424798e-06, 2.74743159e-06, -1.94696995e-07, 2.78416205e-06,
-1.40985001e-06])
message: 'Optimization terminated successfully.'
nfev: 47
nit: 39
njev: 47
status: 0
success: True
x: array([1. , 1.00000001, 1.00000002, 1.00000004, 1.00000007])
3.1.3 牛顿共轭梯度法(Newton-Conjugate-Gradient algorithm)
用到梯度的方法还有牛顿法,牛顿法是收敛速度最快的方法,其缺点在于要求Hessian矩阵(二阶导数矩阵)。牛顿法大致的思路是采用泰勒展开的二阶近似:
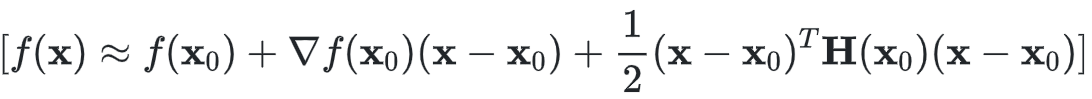
其中(0)表示二阶导数矩阵。若Hessian矩阵是正定的,函数的局部最小值可以通过使上面的二次型的一阶导数等于0来获取,我们有:
![[ \mathbf{x}_{\mathrm{opt}} = \mathbf{x}_0 - \mathbf{H}^{-1}\nabla f ]](https://img-blog.csdnimg.cn/20200716120144469.png)
这里可使用共轭梯度近似Hessian矩阵的逆矩阵。下面给出Rosenbrock函数的Hessian矩阵元素通式:
![[,=∂2∂∂=200(,−2−1−1,)−400(+1,−2,)−400,(+1−2)+2,,=(202+12002−400+1),−400+1,−400−1−1,]](https://img-blog.csdnimg.cn/20200716120220506.png)
其中,∈[1,−2]。其他边界上的元素通式为:
![[∂2∂20∂2∂0∂1=∂2∂1∂0∂2∂−1∂−2=∂2∂−2∂−1∂2∂2−1=120020−4001+2,=−4000,=−400−2,=200.]](https://img-blog.csdnimg.cn/20200716120248170.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3dlaXhpbl80Mzg2ODQzNw==,size_16,color_FFFFFF,t_70)
例如,当=5时的Hessian矩阵为:
![[ \mathbf{H} =120020−4001+2−4000000−4000202+120021−4002−4001000−4001202+120022−4003−4002000−4002202+120023−4004−4003000−4003200]](https://img-blog.csdnimg.cn/20200716120255435.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3dlaXhpbl80Mzg2ODQzNw==,size_16,color_FFFFFF,t_70)
为使用牛顿共轭梯度法,我们需要提供一个计算Hessian矩阵的函数:
def rosen_hess(x):
x = np.asarray(x)
H = np.diag(-400*x[:-1],1) - np.diag(400*x[:-1],-1)
diagonal = np.zeros_like(x)
diagonal[0] = 1200*x[0]**2-400*x[1]+2
diagonal[-1] = 200
diagonal[1:-1] = 202 + 1200*x[1:-1]**2 - 400*x[2:]
H = H + np.diag(diagonal)
return H
res = opt.minimize(rosen, x_0, method='Newton-CG', jac=rosen_der, hess=rosen_hess, options={'xtol': 1e-8, 'disp': True})
print("Result of minimizing Rosenbrock function via Newton-Conjugate-Gradient algorithm (Hessian):")
print(res)
Optimization terminated successfully.
Current function value: 0.000000
Iterations: 20
Function evaluations: 22
Gradient evaluations: 41
Hessian evaluations: 20
Result of minimizing Rosenbrock function via Newton-Conjugate-Gradient algorithm (Hessian):
fun: 1.47606641102778e-19
jac: array([-3.62847530e-11, 2.68148992e-09, 1.16637362e-08, 4.81693414e-08,
-2.76999090e-08])
message: 'Optimization terminated successfully.'
nfev: 22
nhev: 20
nit: 20
njev: 41
status: 0
success: True
x: array([1., 1., 1., 1., 1.])
对于一些大型的优化问题,Hessian矩阵将异常大,牛顿共轭梯度法用到的仅是Hessian矩阵和一个任意向量的乘积,为此,用户可以提供两个向量,一个是Hessian矩阵和一个任意向量的乘积,另一个是向量,这就减少了存储的开销。记向量=(1,…,−1),可有

们定义如下函数并使用牛顿共轭梯度方法寻优:
def rosen_hess_p(x, p):
x = np.asarray(x)
Hp = np.zeros_like(x)
Hp[0] = (1200*x[0]**2 - 400*x[1] + 2)*p[0] - 400*x[0]*p[1]
Hp[1:-1] = -400*x[:-2]*p[:-2]+(202+1200*x[1:-1]**2-400*x[2:])*p[1:-1] \
-400*x[1:-1]*p[2:]
Hp[-1] = -400*x[-2]*p[-2] + 200*p[-1]
return Hp
res = opt.minimize(rosen, x_0, method='Newton-CG', jac=rosen_der, hessp=rosen_hess_p, options={'xtol': 1e-8, 'disp': True})
print("Result of minimizing Rosenbrock function via Newton-Conjugate-Gradient algorithm (Hessian times arbitrary vector):")
print(res)
Optimization terminated successfully.
Current function value: 0.000000
Iterations: 20
Function evaluations: 22
Gradient evaluations: 41
Hessian evaluations: 58
Result of minimizing Rosenbrock function via Newton-Conjugate-Gradient algorithm (Hessian times arbitrary vector):
fun: 1.47606641102778e-19
jac: array([-3.62847530e-11, 2.68148992e-09, 1.16637362e-08, 4.81693414e-08,
-2.76999090e-08])
message: 'Optimization terminated successfully.'
nfev: 22
nhev: 58
nit: 20
njev: 41
status: 0
success: True
x: array([1., 1., 1., 1., 1.])
3.2. 约束优化问题
无约束优化问题的一种标准形式为:
minimizesubject to()()≤0,=1,…,=
其中0,…,:ℝ→ℝ为ℝ空间上的二次可微的凸函数;为×矩阵且秩rank=<。
我们考察如下一个例子:
minimizesubject to(,)=2+2−2−223−=0−1≥0
定义目标函数及其导数为:
def func(x, sign=1.0):
""" Objective function """
return sign*(2*x[0]*x[1] + 2*x[0] - x[0]**2 - 2*x[1]**2)
def func_deriv(x, sign=1.0):
""" Derivative of objective function """
dfdx0 = sign*(-2*x[0] + 2*x[1] + 2)
dfdx1 = sign*(2*x[0] - 4*x[1])
return np.array([ dfdx0, dfdx1 ])
其中sign表示求解最小或者最大值,我们进一步定义约束条件:
cons = ({'type': 'eq', 'fun': lambda x: np.array([x[0]**3 - x[1]]), 'jac': lambda x: np.array([3.0*(x[0]**2.0), -1.0])},
{'type': 'ineq', 'fun': lambda x: np.array([x[1] - 1]), 'jac': lambda x: np.array([0.0, 1.0])})
最后我们使用SLSQP(Sequential Least SQuares Programming optimization algorithm)方法进行约束问题的求解(作为比较,同时列出了无约束优化的求解):
res = opt.minimize(func, [-1.0, 1.0], args=(-1.0,), jac=func_deriv, method='SLSQP', options={'disp': True})
print("Result of unconstrained optimization:")
print(res)
res = opt.minimize(func, [-1.0, 1.0], args=(-1.0,), jac=func_deriv, constraints=cons, method='SLSQP', options={'disp': True})
print("Result of constrained optimization:")
print(res)
Optimization terminated successfully. (Exit mode 0)
Current function value: -2.0
Iterations: 4
Function evaluations: 5
Gradient evaluations: 4
Result of unconstrained optimization:
fun: -2.0
jac: array([-0., -0.])
message: 'Optimization terminated successfully.'
nfev: 5
nit: 4
njev: 4
status: 0
success: True
x: array([2., 1.])
Optimization terminated successfully. (Exit mode 0)
Current function value: -1.0000001831052137
Iterations: 9
Function evaluations: 14
Gradient evaluations: 9
Result of constrained optimization:
fun: -1.0000001831052137
jac: array([-1.99999982, 1.99999982])
message: 'Optimization terminated successfully.'
nfev: 14
nit: 9
njev: 9
status: 0
success: True
x: array([1.00000009, 1. ])
和统计部分一样,Python也有专门的优化扩展模块,CVXOPT(http://cvxopt.org )专门用于处理凸优化问题,在约束优化问题上提供了更多的备选方法。CVXOPT是著名的凸优化教材convex optimization的作者之一,加州大学洛杉矶分校Lieven Vandenberghe教授的大作,是处理优化问题的利器。
SciPy中的优化模块还有一些特殊定制的函数,专门处理能够转化为优化求解的一些问题,如方程求根、最小方差拟合等,可到SciPy优化部分的指引页面查看。