python爬虫入门实战(四)!爬取动态加载的页面!
有些网页是动态加载的,那么怎么处理呢?
今天的主题是爬取动态网页的经验分享,以cocos论坛为例子进行分享。(官方不会打我吧 )
配置环境
为什么选择cocos论坛呢?因为自己在浏览论坛时,发现标题内容会随着滚动条的位置而动态添加。
环境: python3 + requests 。还要引入几个系统库。参考如下:
import requests
import json
import csv
from multiprocessing.dummy import Pool
分析网页
以chrome浏览器为例,空白处 右键->检查 进入网页分析模式,选择 Network 中的XHR,滚动条往下滚,观察右侧加载了什么文件。

在网页分享模式下,点击刚才下载的文件,查看里面的内容,发现对一个地址使用了GET方法,并传入了页码的参数。
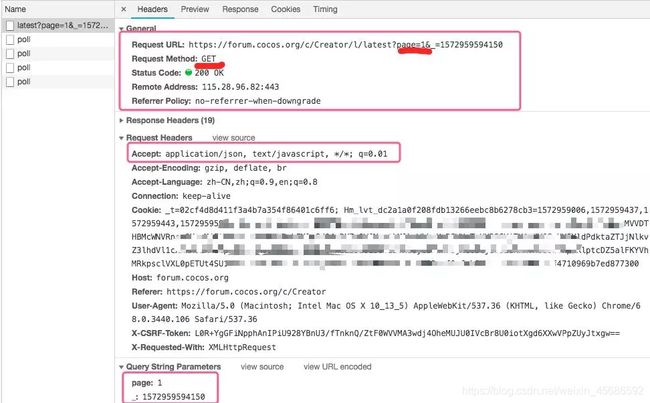
再看看返回的内容是一个json字符串。
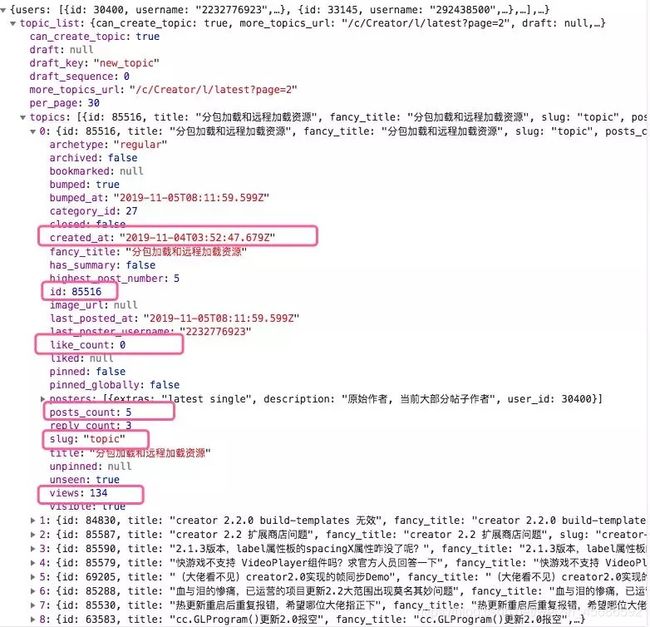
这个 json字符串里就有我们想要内容。一起看下如何用requests 发送参数,并返回Json 结果。
headers = {
'Accept': 'application/json'
}
url=f'https://forum.cocos.org/c/Creator/l/latest?page={1}';
html=requests.get(url,headers=headers);
if html.status_code == 200:
html_bytes = html.content;
html_str = html_bytes.decode();
只需要根据地址,传入一个 headers 告诉网页我们要接收json字符串。
解析json
json是一种数据存储格式,可以被多种语言解析,一般用于数据传输。
由前一张图,可以看到所有文章列表在topic_list的topics中,一起看看 python3 是怎么解析的。
data = json.loads(html_str);
all_items=data['topic_list']['topics']
write_content=[];
for item in all_items:
slug = item['slug'];
item_id = item['id']
link = f'https://forum.cocos.org/t/{slug}/{item_id}'
title = item['title'];
like_count = item['like_count'];
like_count = item['like_count'];
posts_count = item['posts_count'];
views = item['views'];
created_at = item['created_at'];
write_content.append({'标题': title, '链接': link
, '点赞':like_count , '回复':posts_count
, '浏览':views , '发帖时间':created_at
});
其中的链接地址可以通过打开几个论坛内容找到规律,是由 slug 和 id 这两个字段拼接的。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-T11pCIWL-1573459065650)(/img/in-post/201911/1105-title.png)]
最后使用多线程 和 csv 存储结果。(不清楚的话可以看看之前的文章哦。python爬虫入门实战(三) 和 python爬虫入门实战(二)!多线程爬虫! )
pool = Pool(3);
orign_num=[x for x in range(0,10)];
result = pool.map(scrapy,orign_num);
with open('ccc_title_link.csv', 'w', newline='') as csvfile:
fieldnames = ('标题', '链接', '点赞', '回复','浏览', '发帖时间')
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
for write_content in result:
for _content in write_content:
writer.writerow(_content);
最后,看看最终效果吧!

小结
对于动态生成的内容,我们可以通过网页分享中下载的文件分析,并通过requests模块模拟headers 和发送参数方法获取数据。
这是我学到的新技能哦!如有错误或其他想法,欢迎留言!如果我又学到新的东西,会第一时间分享给大家哦!点个关注不迷路!
以上内容仅供个人学习使用,请勿用于商业用途。
我是白玉无冰,游戏开发小赤佬,也玩python和shell
参考资料