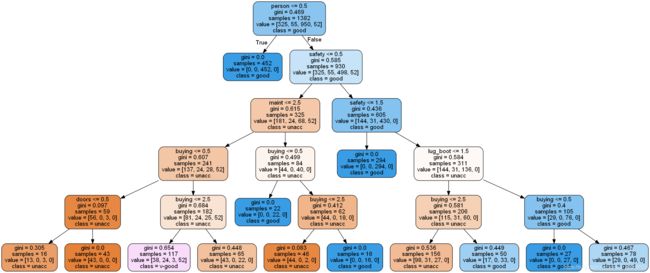
使用决策树算法评估汽车等级
首先安装号第三方库,绘图软件
不需要配置环境变量
数据:car.data
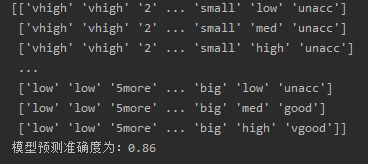
数据描述:1728条数据(6个特征+评估等级(4个级别))
特征:[‘buying’, ‘maint’,‘doors’,‘persons’,‘lug_boot’,‘safety’]
标签:[‘unacc’,‘acc’,‘good’,‘v-good’],

训练模型基本流程及对应要求:
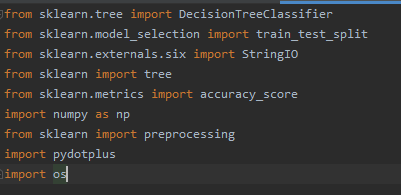
0、使用的第三方库
1、获取数据:读取数据
2、数据处理:字符型特征转换(from sklearn.preprocessing import LabelEncoder)
划分数据集…

3、模型训练与测试:利用sklearn实现分类决策树

4、模型评估(准确度)与可视化(树模型)

6、主函数:

代码:
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn.externals.six import StringIO
from sklearn import tree
from sklearn.metrics import accuracy_score
import numpy as np
from sklearn import preprocessing
import pandas as pd
import pydotplus
import os
def get_data(filename):
# 1、添加代码,获取数据
datasets = pd.read_csv(filename)
print(datasets.head())
df = open(filename)
arraylines = df.readlines()
index = 0;
data = []
for line in arraylines:
# 移除字符串头尾指定的字符(默认为空格)
line = line.strip()
listfromline = line.split(’,’)
data.append(listfromline)
index += 1
data = np.array(data)
print(data)
return data
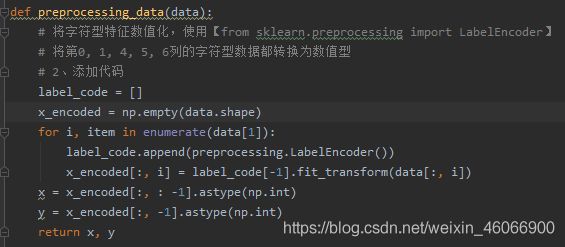
def preprocessing_data(data):
# 将字符型特征数值化,使用【from sklearn.preprocessing import LabelEncoder】
# 将第0, 1, 4, 5, 6列的字符型数据都转换为数值型
# 2、添加代码
label_code = []
x_encoded = np.empty(data.shape)
for i, item in enumerate(data[1]):
label_code.append(preprocessing.LabelEncoder())
x_encoded[:, i] = label_code[-1].fit_transform(data[:, i])
x = x_encoded[:, : -1].astype(np.int)
y = x_encoded[:, -1].astype(np.int)
return x, y
def deal_data(data):
# 划分数据
# 3、添加代码
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=1)
return x_train, x_test, y_train, y_test
def train_test(x_train, x_test, y_train):
# 4、添加代码,训练模型、测试
clf = DecisionTreeClassifier(criterion=‘gini’, splitter=‘best’, max_depth=5)
clf.fit(x_train, y_train)
y_pred = clf.predict(x_test)
return clf, y_pred
def evalute(y_test, y_pred):
# 添加代码,返回准确度accuracy_score
result = accuracy_score(y_test, y_pred)
return result
def draw(clf):
# 观察训练完成的树形:使用第三方库 graphviz添加绘制树形结构的代码
# 使用第三方库 graphviz
# viz code 可视化 制作一个简单易读的PDF’’’
os.environ[“PATH”] += os.pathsep + ‘D:/graphviz/bin’
dot_data = StringIO()
tree.export_graphviz(clf, out_file=dot_data,
feature_names=[‘buying’, ‘maint’, ‘doors’, ‘person’,‘lug_boot’,‘safety’],
class_names=[‘unacc’, ‘acc’, ‘good’,‘v-good’],
filled=True, rounded=True,
special_characters=False)
graph = pydotplus.graph_from_dot_data(dot_data.getvalue())
graph.write_pdf(“D:/pyCharm/例子/机器语言/car.pdf”)
if name == ‘main’:
# 1、 获取数据
filename = ‘D:/pyCharm/例子/机器语言/data_car.data’
data = get_data(filename)
# 2、数据可视化
x,y = preprocessing_data(data)
# 3、数据处理:字符型特征转换,划分数据集
x_train, x_test, y_train, y_test = deal_data(data)
# 4、模型训练与测试
clf, y_pred = train_test(x_train, x_test, y_train)
# 5、模型评估与可视化
result = evalute(y_test, y_pred)
print("模型预测准确度为:%.2f" % result)
draw(clf)