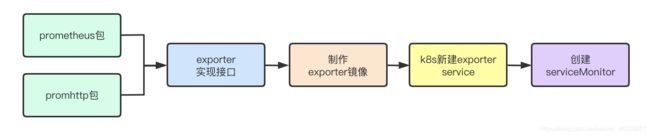
Prometheus自定义exporter
服务
以GPU监控为例,参考prometheus官方文档,这里用到了gonvml库,确保运行环境能找到libnvidia-ml.so.1库,如果没有,其实也可以nvidia-smi,手动解析获取监控指标,不过这样比较麻烦。
Gauge和GaugeVec区别:Gauge单个监控指标,GaugeVec多个监控指标集合,需要定义[]labels,使用WithLabelValues(labels…)去选择指标,用于多CPU、GPU等场景
package main
import (
"flag"
"fmt"
"github.com/mindprince/gonvml"
"github.com/prometheus/client_golang/prometheus"
"github.com/prometheus/client_golang/prometheus/promhttp"
"net/http"
"strconv"
"sync"
)
const (
namespace = "nvidia_gpu"
)
var (
labels = []string{"minor_number", "uuid", "name"}
)
//Collector defines prometheus collector params
type Collector struct {
sync.Mutex
numDevices prometheus.Gauge
usedMemory *prometheus.GaugeVec
totalMemory *prometheus.GaugeVec
dutyCycle *prometheus.GaugeVec
powerUsage *prometheus.GaugeVec
temperature *prometheus.GaugeVec
}
//NewCollector return a new Collector
func NewCollector() *Collector {
return &Collector{
numDevices: prometheus.NewGauge(
prometheus.GaugeOpts{
Namespace: namespace,
Name: "num_devices",
Help: "Number of GPU devices",
},
),
usedMemory: prometheus.NewGaugeVec(
prometheus.GaugeOpts{
Namespace: namespace,
Name: "memory_used_bytes",
Help: "Memory used by the GPU device in bytes",
},
labels,
),
totalMemory: prometheus.NewGaugeVec(
prometheus.GaugeOpts{
Namespace: namespace,
Name: "memory_total_bytes",
Help: "Total memory of the GPU device in bytes",
},
labels,
),
dutyCycle: prometheus.NewGaugeVec(
prometheus.GaugeOpts{
Namespace: namespace,
Name: "duty_cycle",
Help: "Percent of time over the past sample period during which one or more kernels were executing on the GPU device",
},
labels,
),
powerUsage: prometheus.NewGaugeVec(
prometheus.GaugeOpts{
Namespace: namespace,
Name: "power_usage_milliwatts",
Help: "Power usage of the GPU device in milliwatts",
},
labels,
),
temperature: prometheus.NewGaugeVec(
prometheus.GaugeOpts{
Namespace: namespace,
Name: "temperature_celsius",
Help: "Temperature of the GPU device in celsius",
},
labels,
),
}
}
//Describe return the descriptions
func (c *Collector) Describe(ch chan<- *prometheus.Desc) {
ch <- c.numDevices.Desc()
c.usedMemory.Describe(ch)
c.totalMemory.Describe(ch)
c.dutyCycle.Describe(ch)
c.powerUsage.Describe(ch)
c.temperature.Describe(ch)
}
//Collect return the current state of all metrics of the collector.
func (c *Collector) Collect(ch chan<- prometheus.Metric) {
c.Lock()
defer c.Unlock()
//clean all metrics
c.usedMemory.Reset()
c.totalMemory.Reset()
c.dutyCycle.Reset()
c.powerUsage.Reset()
c.temperature.Reset()
numDevices, err := gonvml.DeviceCount()
if err != nil {
fmt.Printf("DeviceCount() error: %v", err)
return
}
c.numDevices.Set(float64(numDevices))
ch <- c.numDevices
for i := 0; i < int(numDevices); i++ {
dev, err := gonvml.DeviceHandleByIndex(uint(i))
if err != nil {
fmt.Printf("DeviceHandleByIndex(%d) error: %v", i, err)
continue
}
minorNumber, err := dev.MinorNumber()
if err != nil {
fmt.Printf("MinorNumber() error: %v", err)
continue
}
minor := strconv.Itoa(int(minorNumber))
uuid, err := dev.UUID()
if err != nil {
fmt.Printf("UUID() error: %v", err)
continue
}
name, err := dev.Name()
if err != nil {
fmt.Printf("Name() error: %v", err)
continue
}
totalMemory, usedMemory, err := dev.MemoryInfo()
if err != nil {
fmt.Printf("MemoryInfo() error: %v", err)
} else {
c.usedMemory.WithLabelValues(minor, uuid, name).Set(float64(usedMemory))
c.totalMemory.WithLabelValues(minor, uuid, name).Set(float64(totalMemory))
}
dutyCycle, _, err := dev.UtilizationRates()
if err != nil {
fmt.Printf("UtilizationRates() error: %v", err)
} else {
c.dutyCycle.WithLabelValues(minor, uuid, name).Set(float64(dutyCycle))
}
powerUsage, err := dev.PowerUsage()
if err != nil {
fmt.Printf("PowerUsage() error: %v", err)
} else {
c.powerUsage.WithLabelValues(minor, uuid, name).Set(float64(powerUsage))
}
temperature, err := dev.Temperature()
if err != nil {
fmt.Printf("Temperature() error: %v", err)
} else {
c.temperature.WithLabelValues(minor, uuid, name).Set(float64(temperature))
}
}
c.usedMemory.Collect(ch)
c.totalMemory.Collect(ch)
c.dutyCycle.Collect(ch)
c.powerUsage.Collect(ch)
c.temperature.Collect(ch)
}
func main() {
if err := gonvml.Initialize(); err != nil {
fmt.Printf("Couldn't initialize gonvml: %v. Make sure NVML is in the shared library search path.", err)
}
defer gonvml.Shutdown()
port := flag.Int("p", 9445, "exporter listen port")
flag.Parse()
if driverVersion, err := gonvml.SystemDriverVersion(); err != nil {
fmt.Printf("SystemDriverVersion() error: %v", err)
} else {
fmt.Printf("SystemDriverVersion(): %v", driverVersion)
}
prometheus.MustRegister(NewCollector())
http.Handle("/metrics", promhttp.Handler())
if err := http.ListenAndServe(fmt.Sprintf(":%d", *port), nil); err != nil {
fmt.Printf("Error occur when start server %v", err)
}
}
直接go build(如果是mac系统,需要交叉编译,并且设置CGO_ENABLED=1,指定CC,或者起golang容器编译)
curl 127.0.0.1:9445/metrics
加入k8s
要在所有物理机上部署,需要使用daemonset
apiVersion: extensions/v1beta1
kind: DaemonSet
metadata:
creationTimestamp: 2020-06-09T07:22:11Z
generation: 1
labels:
app: gpu-exporter
chart: gpu-exporter-0.0.3-17209544
heritage: Tiller
release: gpu-exporter
name: gpu-exporter
namespace: default
resourceVersion: "994893"
selfLink: /apis/extensions/v1beta1/namespaces/default/daemonsets/gpu-exporter
uid: ef63872c-aa21-11ea-9329-6c92bf1a7e73
spec:
revisionHistoryLimit: 10
selector:
matchLabels:
app: gpu-exporter
template:
metadata:
creationTimestamp: null
labels:
app: gpu-exporter
spec:
containers:
- args:
- -p=9445
command:
- /home/work/gpu_exporter
image: gpu_exporter:v1.0
imagePullPolicy: IfNotPresent
name: gpu-exporter
resources: {}
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
dnsPolicy: ClusterFirst
restartPolicy: Always
schedulerName: default-scheduler
securityContext: {}
terminationGracePeriodSeconds: 30
volumes:
- configMap:
defaultMode: 420
name: gpu-exporter
name: conf
- name: secret
secret:
defaultMode: 420
secretName: gpu-exporter
templateGeneration: 1
updateStrategy:
rollingUpdate:
maxUnavailable: 1
type: RollingUpdate
status:
currentNumberScheduled: 1
desiredNumberScheduled: 1
numberAvailable: 1
numberMisscheduled: 0
numberReady: 1
observedGeneration: 1
updatedNumberScheduled: 1
service,特别注意spec.ports.name,指定端口名,后面ServiceMonitor需要用到
apiVersion: v1
kind: Service
metadata:
annotations:
prometheus.io/scrape: "true"
creationTimestamp: 2020-06-09T07:22:11Z
labels:
app: gpu-exporter
chart: gpu-exporter-0.0.3-17209544
heritage: Tiller
release: gpu-exporter
name: gpu-exporter-service
namespace: default
resourceVersion: "994838"
selfLink: /api/v1/namespaces/default/services/gpu-exporter-service
uid: ef62f485-aa21-11ea-9329-6c92bf1a7e73
spec:
clusterIP: 10.233.7.81
ports:
- name: metrics
port: 9445
protocol: TCP
targetPort: 9445
selector:
app: gpu-exporter
sessionAffinity: None
type: ClusterIP
status:
loadBalancer: {}
endpoint
apiVersion: v1
kind: Endpoints
metadata:
creationTimestamp: 2020-06-09T07:22:11Z
labels:
app: gpu-exporter
chart: gpu-exporter-0.0.3-17209544
heritage: Tiller
release: gpu-exporter
name: gpu-exporter-service
namespace: default
resourceVersion: "994894"
selfLink: /api/v1/namespaces/default/endpoints/gpu-exporter-service
uid: ef644d5c-aa21-11ea-9329-6c92bf1a7e73
subsets:
- addresses:
- ip: 192.168.1.1
nodeName: localhost
targetRef:
kind: Pod
name: gpu-exporter-ppb2n
namespace: default
resourceVersion: "994892"
uid: 868175fd-aa2d-11ea-9329-6c92bf1a7e73
ports:
- name: metrics
port: 9445
protocol: TCP
ServiceMonitor,spec.endpoints.port需要与上面一致
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
labels:
app: gpu-exporter
name: gpu-exporter
spec:
endpoints:
- interval: 10s
port: metrics
scrapeTimeout: 10s
namespaceSelector:
any: true
selector:
matchLabels:
app: gpu-exporter
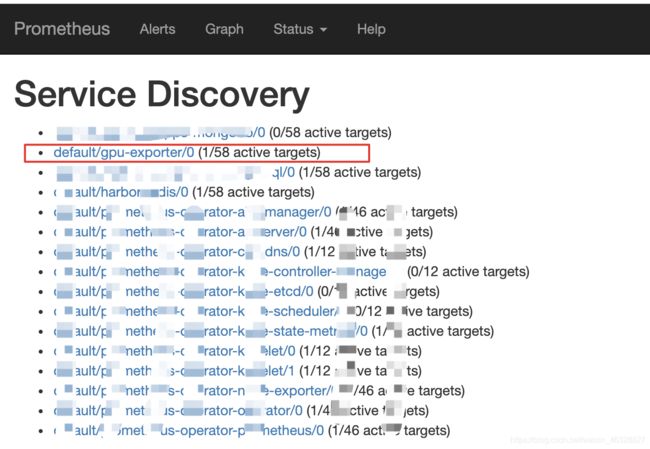
另外创建ServiceMonitor后,prometheus不会立即做服务发现,在 prometheus 控制台的 service-discovery 中不显示,需要重启一下pod,或者reload一下prometheus
登录prometheus,查看服务发现
 总体流程
总体流程