史上最简单的Elasticsearch教程-第六章:Elasticsearch的restful之搜索查询(DSL)
Eltasticsearch的restful搜索:
(提前声明:文章由作者:张耀峰 结合自己生产中的使用经验整理,最终形成简单易懂的文章,写作不易,转载请注明)
(文章参考:Elasticsearch权威指南,Spark快速大数据分析文档,Elasticsearch官方文档,实际项目中的应用场景)
(帮到到您请点点关注,文章持续更新中!)
Git主页 https://github.com/Mydreamandreality
看这章兄弟萌不用担心语法问题,你只需要了解match,filter他们各自承担的作用即可,
因为JavaApi和这个原生的SQL语句完全不是一套东西
我举个栗子:
在Java中查询需要的是:
BoolQueryBuild boolQuery = boolQuery();
不像是我们用mybatis一样直接裸写SQL,完全不一样 !
上一章已经在ES存储了部分数据,现在就根据上一章的数据进行检索:
-
这一章下来兄弟萌大概能学会这么多东西:
-
检索单个文章信息
-
简单的搜索
-
DSL搜索(复杂的查询语句,区间查询,短路语查询)
-
更复杂的搜索(过滤)
-
高亮(类似用百度进行搜索时,你的搜索关键字会在结果中高亮)
-
分析(较为复杂,聚合)
-
OK,现在开始我们的第一个需求,
-
检索单个文章信息:
#这个是相当简单的,只要执行HTTP GET请求并指出文档的"地址"=:索引,类型和ID既可,根据这三部分信息,我们就可以返回原始JSON文档
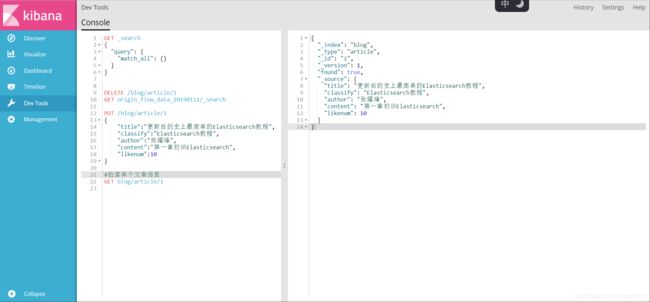
GET blog/article/1 (多么标准的restful风格Api)
#返回值如下,我们的JSON对象都在source_中,外部的信息有数据所在索引,数据所在类型.数据的ID,该数据的版本,是否存在 found:true(存在)
{
"_index": "blog",
"_type": "article",
"_id": "1",
"_version": 1,
"found": true,
"_source": {
"title": "更新后的史上最简单的Elasticsearch教程",
"classify": "Elasticsearch教程",
"author": "张耀烽",
"content": "第一章初识Elasticsearch",
"likenum": 10
}
}
ok,上面先简单了解一下,下面继续我们的第二个需求
-
简单的搜索
-
比如我们要获取所有的文章信息:
-
#获取搜索的文章信息:
GET blog/article/_search
#可以看到我们依然使用blog索引和article类型,但是我们在结尾使用关键字 _search 来取代原来的文档ID
#响应如下:
{
"took": 0,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 2,
"max_score": 1,
"hits": [
{
"_index": "blog",
"_type": "article",
"_id": "2",
"_score": 1,
"_source": {
"title": "史上最简单的Elasticsearch教程",
"classify": "Elasticsearch教程",
"author": "张耀烽",
"content": "第二章初识Kiaban",
"likenum": 100
}
},
{
"_index": "blog",
"_type": "article",
"_id": "1",
"_score": 1,
"_source": {
"title": "更新后的史上最简单的Elasticsearch教程",
"classify": "Elasticsearch教程",
"author": "张耀烽",
"content": "第一章初识Elasticsearch",
"likenum": 10
}
}
]
}
}
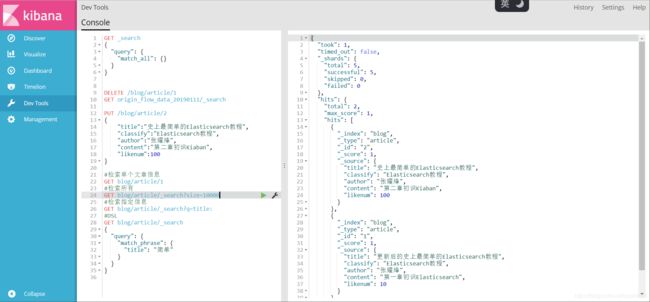
#响应内容的 hits 数组中包含了我们所有的两个文档。默认情况下搜索会返回前10个结果
#如果你需要查看更多数据只需要这样,携带参数 ?size=10000
GET blog/article/_search?size=10000
#默认情况下ES只能支持最多10000条的展示,这个问题涉及到它的底层和深度分页响应的问题,后续也会出一章解决这个问题
#顺便说一下刚用ES的时候一个搞笑的事:刚使用时我们并不知道ES可以定制深度分页,而我们产品中的数据都是从网络流量中爬虫爬下来的,
#所以一天的数据量可能就在100万+,我们要做的是在这数据之上进行计算分析,虽然已经做了分库分表,日统计和月统计分离的操作,
#但是ES一次最多只能取1万条,所以原始数据的展示就是一个很大的问题
#我们的产品经理很不满意(你行你上啊?),为了寻找解决方案,我便投向了可爱的Google,在搜索的过程中,
#我偶然发现,Google的搜索结果最多只能展示17页还是18页?(可以自己去查证),
#哈哈哈.然后给产品看,产品觉得不可能吧,于是他又去百度搜索引擎验证,
#发现百度只能展示7页(可能更多?我忘了,你们可以查证),之后的数据都无法展示~~~
#所以深度分页是搜索引擎的通病,和它本身的底层架构有很大的关系,之后再讲解
ok,第三个需求:
-
DSL搜索(复杂的查询语句)
-
首先:什么是DSL搜索? 官方解释
-
查询字符串搜索便于通过命令行完成特定(ad hoc)的搜索,但是它也有局限性。Elasticsearch提供丰富且灵活的查询语言叫做DSL查询(Query DSL),它允许你构建 更加复杂、强大的查询。 DSL(Domain Specific Language特定领域语言)以JSON请求体的形式出现。
-
干脆直接写一个DSL查询吧,一看就知道了
-
比如我要查询title包含"简单"的文章
-
GET blog/article/_search
{
"query": {
"match_phrase": {
"title": "简单"
}
}
}
#这个请求体使用JSON表示,其中使用了match语句 代表的就是查询title包含简单的文章
#DSL中的关键字类似match还是需要记一下的,因为后续的JavaApi中关于match的使用是比较频繁的(当然match的强大远不及现在看到的)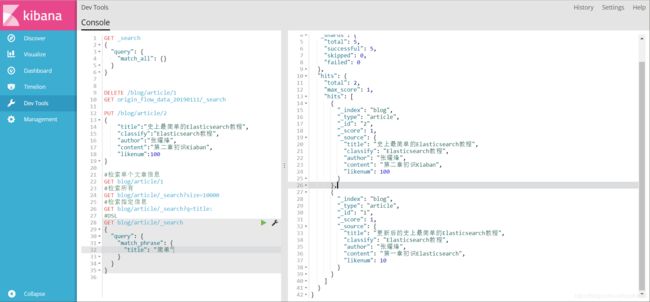
ok,第四个需求
-
更复杂的搜索
-
现在的需求就是:我要查看title包含"简单",但是点赞数必须大于50,这个时候就用到 filter(过滤器)
-
直接看代码就行了,理论说多了都是扯皮
GET /blog/article/_search
{
"post_filter": {
"range": {
"likenum": {
"gte": 50
}
}
}
, "query": {
"match_phrase": {
"title": "简单"
}
}
}
#range就是区间,likenum是我们的点赞field,gte:50 就是筛选大于50点赞数量的文章
#match就是寻找title包含"简单"的文章
ok,第五个需求:
-
高亮查询(模仿百度搜索结果高亮)
-
使用 highlight函数
GET blog/article/_search
{
"query": {
"match_phrase": {
"title": "简单"
}
}
, "highlight": {
"fields": {
"title": {}
}
}
}
#返回数据
"hits": {
"total": 2,
"max_score": 0.5446649,
"hits": [
{
"_index": "blog",
"_type": "article",
"_id": "2",
"_score": 0.5446649,
"_source": {
"title": "史上最简单的Elasticsearch教程",
"classify": "Elasticsearch教程",
"author": "张耀烽",
"content": "第二章初识Kiaban",
"likenum": 100
},
"highlight": {
"title": [
"史上最简单的Elasticsearch教程"
]
}
},...还有一个省略
#还是查找title包含简单的文章,然后使用highlight函数高亮搜索的title
#会命中与之前相同的结果,但是在返回结果中会有一个新的部分叫做highlight
#这里包含了来自你搜索的title字段中的文本,并且用来标识匹配到的单词
ok,最后一个分析(较为复杂,聚合)
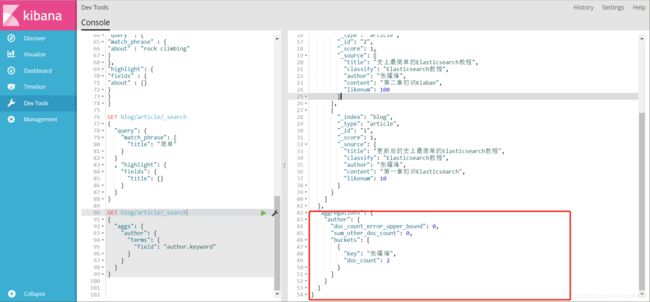
需求:统计 每个作者分别发布了多少篇文章
GET blog/article/_search
{
"aggs": {
"author": {
"terms": {
"field": "author.keyword"
}
}
}
}
#OK,terms进行分组,相当于mysql中group
#聚合的字段是author,就是作者字段#但是你们可以看到我在author后面追加了 .keyword
#这是因为在ES.x版本以后,只有两种数据类型
1.text
2.keyword
text:存储数据时候,会自动分词,并生成索引(这是很智能的,但在有些字段里面是没用的,所以对于有些字段使用text则浪费了空间)
keyword:存储数据时候,不会分词建立索引,但是可以做聚合
Ok,ES原生的DSL查询语句和检索语句就先写到这里了,本来还要写区间聚合的使用.但是数据不支持
不过没关系,到时候写JavaApi的时候聚合我会分很多章节去写,因为它太强大了,
有什么问题留言我们一起交流
下一章就开始写Springboot+JavaAPi的使用了!