机器学习分类算法常用评价指标
https://www.cnblogs.com/asialee/p/9800039.html
1. 准确率,召回率,精确率,F1-score,Fβ,ROC曲线,AUC值
为了评价模型以及在不同研究者之间进行性能比较,需要统一的评价标准。根据数据挖掘理论的一般方法,评价模型预测能力最广泛使用的是二维混淆矩阵(Confusion matrix)(如下表所示)。
二维混淆矩阵
| 真实类别 |
预测结果 |
|
| 类别1(正例) |
类别2(反例) |
|
| 类别1(正例) |
真正例(True Positive) TP |
假反例(False Negatibe) FN |
| 类别2(反例) |
假正例(False Positive)FP |
真反例(True Negatibe) TN |
(1)准确率(Accuracy)表示正确分类的测试实例的个数占测试实例总数的比例,计算公式为:
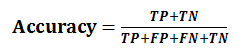
(2)召回率(Recall),也叫查全率,表示正确分类的正例个数占实际正例个数的比例,计算公式为:

(3)精确率(Precision),也叫查准率,表示正确分类的正例个数占分类为正例的实例个数的比例,计算公式为:
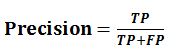
(4)F1-score是基于召回率(Recall)与精确率(Precision)的调和平均,即将召回率和精确率综合起来评价,计算公式为:
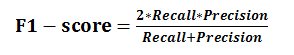
(5) Fβ加权调和平均
Fβ是F1度量的一般形式,能让我们表达出对查准率、查全率的不同偏好,计算公式如下:
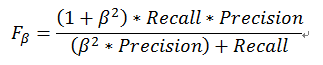
其中,β>0度量了查全率对查准率的相对重要性。β=1时退化为标准的F1;β>1时查全率有更大影响;β<1时查准率有更大影响。
(6)度量分类中的非均衡性的工具是ROC曲线(ROC Curve)
TPR(True Positive Rate)表示在所有实际为阳性的样本中,被正确地判断为阳性的比率,即:TPR=TP/(TP+FN); FPR( False Positive Rate)表示在所有实际为阴性的样本中,被错误地判断为阳性的比率,即:FPR=FP/(FP+TN)。
ROC曲线是以FPR作为X轴,TPR作为Y轴。FPR越大表明预测正类中实际负类越多,TPR越大,预测正类中实际正类越多。ROC曲线如下图所示:
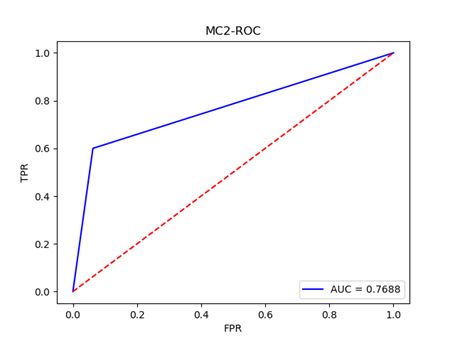
(7)AUC值(Area Unser the Curve)是ROC曲线下的面积,AUC值给出的是分类器的平均性能值。使用AUC值可以评估二分类问题分类效果的优劣,计算公式如下:

一个完美的分类器的AUC为1.0,而随机猜测的AUC为0.5,显然AUC值在0和1之间,并且数值越高,代表模型的性能越好。
2. 宏平均(Macro-averaging)和微平均(Micro-averaging)
在n个二分类混淆矩阵上综合考虑查准率和查全率时使用。
(1)宏平均(macro-ave)
先在各混淆矩阵上分别计算出查准率,查全率和F1,然后再计算平均值,这样就得到“宏查准率”(macro-P)、“宏查全率”(macro-R)、“宏F1”(macro-F1),计算公式分别如下:



(2)微平均(micro-ave)
先将各混淆矩阵的对应元素进行平均,得到TP、FP、TN、FN的平均值,再基于这些平均值计算出“微查准率”(micro-P)、“微查全率”(micro-R)、“微F1”(micro-F1),计算公式分别如下:

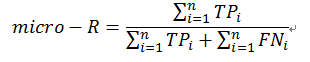
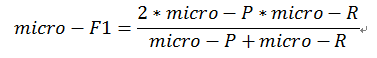
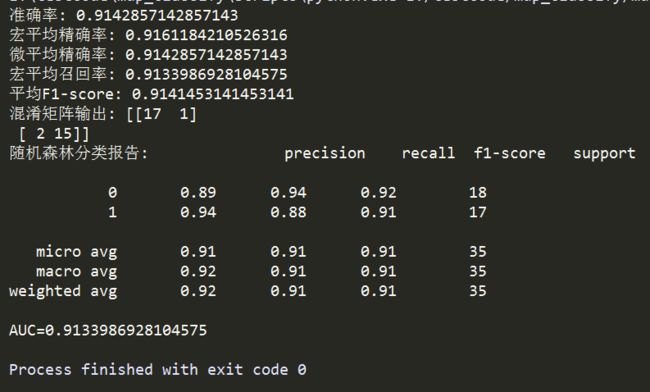
3. Python sklearn实现分类指标
(1)KC4数据准备
(2)使用随机森林实现分类并输出评价指标
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 |
|
评价指标结果如下: