如何去除网页噪声提取数据(02) —— 汽车之家(字体反爬)
如何去除网页噪声提取数据(02) —— 汽车之家(字体反爬)
1. 需求介绍
- 继去哪儿网之后,我又盯上了汽车之家这个网站,这个网站的反爬策略挺有意思的,采用了时下最流行的字体反爬技术,让我心神荡漾,对它动起了歪心思……嘿嘿
- 我的目标是爬取汽车之家论坛上的帖子内容。
- 捣鼓了一番之后,捣捣捣……终于成功获取了所有信息,让数据赤裸相见了,下面讲解详细的分析过程。
2. 环境
- python 3.6.1
- 系统:win7
- IDE:pycharm
- requests 2.14.2
- fontTools 3.26.0 (pip install footTools)
3. 汽车之家论坛网站分析
- 以抓取这篇文章的内容为目标:https://club.autohome.com.cn/bbs/thread/9b952e4f093e6295/64890206-1.html
3.1. 分析网页内容
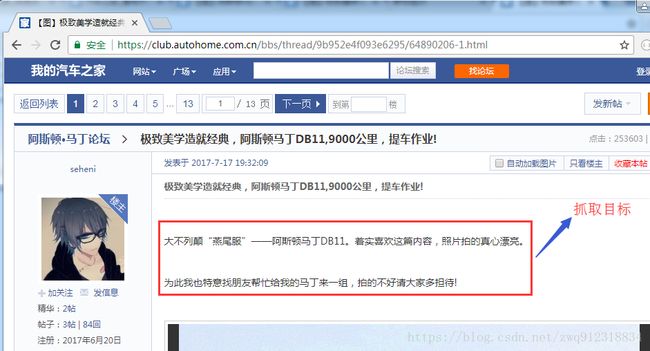
- 第一步:打开审查元素,查看渲染后的数据呈现形式。
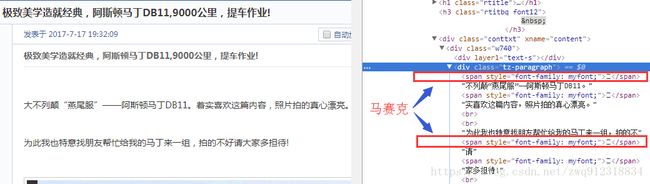
- 这是神马鬼,渲染后的数据都被打上了马赛克,遮遮掩掩的,害羞啊!
- 第二步:尝试将这个文本复制下来,内容如下。看起来,缺胳膊断腿的。
不列颠“燕尾服”——阿斯顿马丁DB11。实喜欢这篇内容,照片拍的真心漂亮。
为此我也特意找朋友帮忙给我的马丁来一组,拍的不请家多担待!- 第三步:我们看一眼它的网页源代码是什么,原始的真面目长啥样。毕竟我们爬虫拉下来的数据是源代码。这里只取文字部分。
<div layer1="text-s">div><div class="tz-paragraph"><span style='font-family: myfont;'>span><span style='font-family: myfont;'>span>列颠“燕尾服”——阿斯顿马丁DB11。<span style='font-family: myfont;'>span>实喜欢这篇内容,照片拍的真心漂亮。<br /><br />为此我也特意找朋友帮忙给我的马丁来<span style='font-family: myfont;'>span>组,拍的<span style='font-family: myfont;'>span>好请<span style='font-family: myfont;'>span>家多担待!<br />div><div layer1="text-e">div>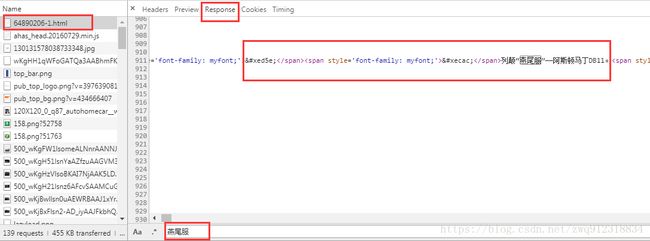
- 这个地方就要用到我们男人的第六感了……呃,是经验,看到形如:,,这样的字符,就应该想到这是一种特殊的字符编码了。而span style=’font-family: myfont;’ 这么明显的标记,昭示这就是字体的编码。举个这么大的牌子,就怕别人看不到似的…太招摇了,咳咳,下场就…
- 第四步:再次凭借着男人的第六感,既然有自定义字体,那必然会有字体文件随着js请求,被下载到本地。抽丝剥茧,顺藤摸瓜,到网页源代码中去搜索,发现这个地方的引用了:
<style type="text/css">
@font-face {font-family: 'myfont';src: url('//k2.autoimg.cn/g24/M06/3F/FF/wKgHH1qWFoGALXlaAABiXrRwbBM42..eot');src: url('//k3.autoimg.cn/g24/M06/3F/FF/wKgHH1qWFoGALXlaAABiXrRwbBM42..eot?#iefix') format('embedded-opentype'),url('//k3.autoimg.cn/g24/M06/3F/FF/wKgHH1qWFoGATQa3AABhmFKVVrQ43..ttf') format('woff');}
style>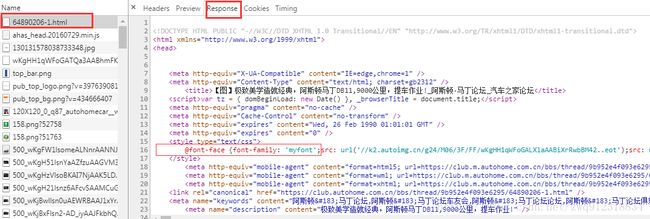
# 看到了几个文件:
1. eot文件: *.eot是一种压缩字库,目的是解决在网页中嵌入特殊字体的难题。在网页中嵌入的字体只能是 OpenType 类型,其他类型的字体只有转换成 OpenType 类型(eot格式)的字体才能在网页中进行嵌入。
2. ttf文件: *.ttf是字体文件格式。TTF(TrueTypeFont)是Apple公司和Microsoft公司共同推出的字体文件格式,随着windows的流行,已经变成最常用的一种字体文件表示方式。- 我们将这个字体文件的url地址,键入到浏览器中,将ttf字体文件下载到本地。
3.2. 字体反爬技术分析
- 自定义字体:@font-face 是CSS3中的一个模块,主要是实现将自定义的Web字体嵌入到指定网页中去。想了解详细定义,请从此门穿入:https://www.cnblogs.com/fjdingsd/p/5663561.html
3.2.1. 查看ttf字体文件
- 想查看ttf字体文件的详细内容,需要使用专门的工具,在网上我搜到了一个工具:FontCreator(下载地址:http://www.onlinedown.net/soft/88758.htm , 使用方法:https://blog.csdn.net/playboyanta123/article/details/79438786),还挺好用的。打开字体文件,显示如下:
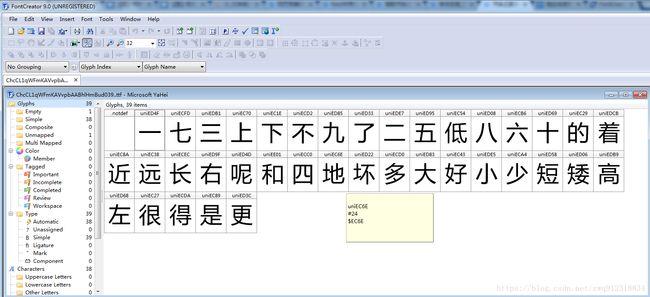
- 从这个表中可以看到,这里对一些中文文字进行了重新编码处理,属于自定的编码。这个字体里一共有39个字(第一个是空白字),很明显,每个字可以看到字形和字形编码。而且,很明显,这个编码是Unicode编码,这么明显,看不到,不是眼瞎么。
3.2.2. 字符集编码:unicode和utf-8
- 字符集详解:https://blog.csdn.net/qq_28098067/article/details/53486032
- 再次拿到网页源代码中的这段文字,去掉css样式,对比呈现给用户的文本,可以得出如下的对应关系
列颠“燕尾服”——阿斯顿马丁DB11。实喜欢这篇内容,照片拍的真心漂亮。
为此我也特意找朋友帮忙给我的马丁来组,拍的好请家多担待!大不列颠“燕尾服”――阿斯顿马丁DB11。着实喜欢这篇内容,照片拍的真心漂亮。
为此我也特意找朋友帮忙给我的马丁来一组,拍的不好请大家多担待- 对比一下,ttf字体文件中的编码和网页源代码中的编码
| 字形 | 网页源代码中呈现的编码 | ttf字体文件中的编码 |
|---|---|---|
| 大 | | uniED83 |
| 不 | | uniECD2 |
| 着 | | uniEDCB |
| 一 | | uniED4F |
| 不 | | uniECD2 |
| 大 | | uniED83 |
对比,发现两者不一样,长得就不像是亲兄弟。经过尝试比对,发现这其实分别是unicode编码和utf-8编码。
而且,我发现每次访问,字体字形顺序是不变的,但字符的编码确是变化的。因此,我们需要根据每次访问,动态解析字体文件。
4. 代码实现
- 经过上面的分析,对汽车之家字体反爬的策略摸清楚了,就可以制定对应的策略了。
- 具体的思路如下:
- 第一步:先将整个页面源代码爬下来。
- 第二步:找到ttf字体文件的地址,将ttf字体文件下载到本地。
- 第三步:手动用FontCreator程序打开字体文件,获取字形和对应的Unicode编码,录入到程序中。
- 第四步:用fontTools模块对ttf文件进行解析,获取字形对应的Unicode编码信息。
- 第五步:将自定义字体的Unicode编码转换成utf-8编码。
- 第六步:将网页源代码中的utf-8编码,按照前面录入的字形列表,按照国际汉字标准,全部替换成对应的字形Unicode编码。
# -*- coding:utf-8 -*-
import requests
from lxml import html
import re
from fontTools.ttLib import TTFont
# 定义字体文件的名字
fontFileName = "autohomeFont.ttf"
headerInfo = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.86 Safari/537.36",
'host':'club.autohome.com.cn',
}
# 爬取链接
url = "https://club.autohome.com.cn/bbs/thread/9b952e4f093e6295/64890206-1.html"
# 获取页面源代码
resp = requests.get(url, headers = headerInfo)
# 用正则表达式提取ttf字体文件的地址
# url('//k3.autoimg.cn/g24/M06/3F/FF/wKgHH1qWFoGATQa3AABhmFKVVrQ43..ttf') format('woff');}
ttfUrlRe = re.search(",url\('(//.*.ttf)'\) format\('woff'\)", resp.text, re.DOTALL)
ttfUrl = ""
if ttfUrlRe:
ttfUrl = "https:" + ttfUrlRe.group(1)
if ttfUrl:
# 以文件流的方式,抓取ttf字体文件
ttfFileStream = requests.get(ttfUrl, stream = True)
# 将数据流保存在本地的ttf文件中(新创建)
with open(fontFileName, "wb") as fp:
for chunk in ttfFileStream.iter_content(chunk_size=1024):
if chunk:
fp.write(chunk)
# 用fontTools模块解析字体库文件
fontObject = TTFont(fontFileName)
# 按顺序拿到各个字符的unicode编码
# ['.notdef', 'uniED8F', 'uniED3D', …… ]
uniWordList = fontObject['cmap'].tables[0].ttFont.getGlyphOrder()
print(f"自定义字体列表(unicorn编码): {uniWordList}")
# 将各个字符的unicode编码转换成utf-8编码
# [b'\xee\xb6\x8f', b'\xee\xb4\xbd', b'\xee\xb7\xb1', …… ]
utf8WordList = [eval("u'\\u" + uniWord[3:] + "'").encode("utf-8") for uniWord in uniWordList[1:]]
print(f"自定义字体列表( utf-8 编码): {utf8WordList}")
# 获取发帖内容文字
response = html.fromstring(resp.text)
contentLst = response.xpath("//div[@class='tz-paragraph']//text()")
# 这个部分的逻辑需要特别注意,因为自定义字体,也就是隐藏字符是以utf-8的形式存在的
# 所有一开始,我们就要以utf-8的编码形式来保持文本内容
content = ''.encode("utf-8")
for elem in contentLst:
content += elem.encode("utf-8")
# 录入字体文件中的字符。必须要以国际标准的unicode编码,取代汽车之家自己定义的字体编码
# 这个部分目前是手动输入,但是多次请求,每次拿到的ttf文件可能都不一样,甚至同一个字形,在不同的ttf文件中编码也不同,这个部分需要尤其注意
# 因为是python3,所以这些字符直接就是Unicode编码
wordList = ['一', '七', '三', '上', '下', '不', '九', '了', '二', '五', '低', '八',
'六', '十', '的', '着', '近', '远', '长', '右', '呢', '和', '四', '地', '坏',
'多', '大', '好', '小', '少', '短', '矮', '高', '左', '很', '得', '是', '更',
]
print(f"字体文件中字形列表: {wordList}")
print(f"contentBefort = {content.decode('utf-8')}")
print('--------------- After Convert -----------------')
# 因为之前提到过,在网页源代码中,这种“” 特殊字符是utf-8编码,所以我们要以utf-8的模式去进行查找替换
# content 是字符串,是Unicode编码
for i in range(len(utf8WordList)):
# 将自定的字体信息,替换成国际标准
content = content.replace(utf8WordList[i], wordList[i].encode('utf-8'))
print(f"contentAfter = {content.decode('utf-8')}")- 输出结果:
自定义字体列表(unicorn编码): ['.notdef', 'uniED8F', 'uniED3D', 'uniEDF1', 'uniECB0', 'uniEC5E', 'uniED12', 'uniEDC5', 'uniED73', 'uniEC33', 'uniEDD5', 'uniEC94', 'uniED48', 'uniECF6', 'uniEDA9', 'uniEC69', 'uniEE0B', 'uniECCA', 'uniEC78', 'uniED2C', 'uniEDDF', 'uniED8D', 'uniEC4D', 'uniED00', 'uniECAE', 'uniED62', 'uniED10', 'uniEDC3', 'uniEC83', 'uniEC31', 'uniECE4', 'uniED98', 'uniED46', 'uniEDF9', 'uniEDA8', 'uniEC67', 'uniED1A', 'uniECC9', 'uniED7C']
自定义字体列表( utf-8 编码): [b'\xee\xb6\x8f', b'\xee\xb4\xbd', b'\xee\xb7\xb1', b'\xee\xb2\xb0', b'\xee\xb1\x9e', b'\xee\xb4\x92', b'\xee\xb7\x85', b'\xee\xb5\xb3', b'\xee\xb0\xb3', b'\xee\xb7\x95', b'\xee\xb2\x94', b'\xee\xb5\x88', b'\xee\xb3\xb6', b'\xee\xb6\xa9', b'\xee\xb1\xa9', b'\xee\xb8\x8b', b'\xee\xb3\x8a', b'\xee\xb1\xb8', b'\xee\xb4\xac', b'\xee\xb7\x9f', b'\xee\xb6\x8d', b'\xee\xb1\x8d', b'\xee\xb4\x80', b'\xee\xb2\xae', b'\xee\xb5\xa2', b'\xee\xb4\x90', b'\xee\xb7\x83', b'\xee\xb2\x83', b'\xee\xb0\xb1', b'\xee\xb3\xa4', b'\xee\xb6\x98', b'\xee\xb5\x86', b'\xee\xb7\xb9', b'\xee\xb6\xa8', b'\xee\xb1\xa7', b'\xee\xb4\x9a', b'\xee\xb3\x89', b'\xee\xb5\xbc']
字体文件中字形列表: ['一', '七', '三', '上', '下', '不', '九', '了', '二', '五', '低', '八', '六', '十', '的', '着', '近', '远', '长', '右', '呢', '和', '四', '地', '坏', '多', '大', '好', '小', '少', '短', '矮', '高', '左', '很', '得', '是', '更']
contentBefort = 大不列颠“燕尾服”――阿斯顿马丁DB11。着实喜欢这篇内容,照片拍真心漂亮。为此我也特意找朋友帮忙给我马丁来一组,拍不好请大家多担待!阿斯顿马丁在国内知名度高,但是买并不是很多,虽是众车型,但是这绝不会影响铁杆粉丝对它热爱,众大众主要还是在于品牌定位,就不多提了,选择马丁原因主要是同级别车型中马丁比较调,没有特别张扬外观和排气声,加速快但是很平稳,不会给我一种要失控感。感觉完全不别于法拉和兰博。个品牌各有特点,如果说前两款是血气方刚少年,那马丁一定是稳重大哥,处事不惊。任风雨来袭,我自岿然不动!!这就是马丁气场。,像Lamborghini Huracan,Mclaren625C,FerrariCalifornia T都去看过太过扎眼。所以综合比较最终还是定了AstonMartinDB11。Lamborghini Huracan,内饰我看着乱,而且有点太招摇了,Mclaren625C,他们注重f1,毕竟f1出身,注重速度与激情,我总感觉车内设计不大气,个人意见。FerrariCalifornia T,见比较多,身边有伙伴在开,所以想买个不一样,而且这车和Lamborghini一样高调,不适合我,四款车内饰特点不同,但是都具有现代科技美!!权衡再最终还是定了DB11,中控部分设计和家里车有相同方,用着比较顺手也比较喜欢。有后排可以放东西,后备箱点,但是开这车也基本都是市内跑,出远门也不会开车去。车头给我感觉没有车尾那么强烈,从尾部看肌肉感十足,有点美式肌肉车feel,db11虽然是跑车,但是更好定位我个人觉着是轿跑吧,动力方面搭载5.2L V12双涡轮增压发动机,最大功率608马力,动力总成方面不输于任何品牌,官方给出百米加速是3.9秒,不过我没有体验过,包括s+模式目前也没有感受过,内饰感觉整体要比其他几款品牌好。价格没什么可说,大家都差不多。所以综合下来最终还是比较喜欢db11,车大概4个月右提回来。目前跑了9000多公里。刹车方面需要适应一段时间,最开始老是各种点头,急刹。慢慢适应吧(我个人车技一般)后备箱空间不是很大哦,所以一般出门游玩,后排也可以放一些东西,但是箱子不易过大,要不放进去比较费劲。整体来说两个人出行,后备箱+后排基本满足长途旅行吧!用车感优点:动力十足,缺点:空间有点,外观:回头率超高内饰:真皮触感很棒,做工精细,英国制造!空间:储物空间略,略少动力:提速快,加速平稳,不会有失控感操控:悬挂调校好,转向精准舒适:驾驶空间充足,是不是跑车通病,开久了腰累其它个别问题,每个人可能遇到不同,也不好发表意见和建议,慢慢体会交流心得吧,照片是朋友帮忙给拍,感谢伙伴@张拍摄!!
--------------- After Convert -----------------
contentAfter = 大不列颠“燕尾服”――阿斯顿马丁DB11。着实喜欢这篇内容,照片拍的真心漂亮。为此我也特意找朋友帮忙给我的马丁来一组,拍的不好请大家多担待!阿斯顿马丁在国内知名度高,但是买的并不是很多,虽是小众车型,但是这绝不会影响铁杆粉丝对它的热爱,小众大众主要还是在于品牌的定位,就不多提了,选择马丁的原因主要是同级别车型中马丁比较低调,没有特别张扬的外观和排气声,加速快但是很平稳,不会给我一种要失控感。感觉完全不别于法拉和兰博。三个品牌各有特点,如果说前两款是血气方刚的少年,那马丁一定是稳重的大哥,处事不惊。任风雨来袭,我自岿然不动!!这就是马丁的气场。,像Lamborghini 的Huracan,Mclaren的625C,Ferrari的California T都去看过太过扎眼。所以综合比较最终还是定了AstonMartin的DB11。Lamborghini 的Huracan,内饰我看着乱,而且有点太招摇了,Mclaren的625C,他们注重的f1,毕竟f1出身,注重速度与激情,我总感觉车内设计不大气,个人意见。Ferrari的California T,见的比较多,身边有伙伴在开,所以想买个不一样的,而且这车和Lamborghini一样高调,不适合我,四款车的内饰特点不同,但是都具有现代科技美!!权衡再三最终还是定了DB11,中控部分设计和家里车有相同的地方,用着比较顺手也比较喜欢。有后排可以放东西,后备箱小点,但是开这车也基本都是市内跑,出远门也不会开车去。车头给我的感觉没有车尾那么强烈,从尾部看肌肉感十足,有点美式肌肉车的feel,db11虽然是跑车,但是更好的定位我个人觉着是轿跑吧,动力方面搭载5.2L V12双涡轮增压发动机,最大功率608马力,动力总成方面不输于任何品牌,官方给出的百米加速是3.9秒,不过我没有体验过,包括s+模式目前也没有感受过,内饰感觉整体要比其他几款品牌的好。价格没什么可说的,大家都差不多。所以综合下来最终还是比较喜欢db11,车大概4个月左右提回来的。目前跑了9000多公里。刹车方面需要适应一段时间,最开始老是各种点头,急刹。慢慢适应吧(我个人车技一般)后备箱空间不是很大哦,所以一般出门游玩,后排也可以放一些东西,但是箱子不易过大,要不放进去比较费劲。整体来说两个人出行,后备箱+后排基本满足长短途旅行吧!用车感优点:动力十足,缺点:空间有点小,外观:回头率超高内饰:真皮的触感很棒,做工精细,英国制造!空间:储物空间略小,略少动力:提速快,加速平稳,不会有失控感操控:悬挂调校好,转向精准舒适:驾驶空间充足,是不是跑车通病,开久了腰累其它的的个别小问题,每个人可能遇到的不同,也不好发表意见和建议,慢慢体会交流心得吧,照片是朋友帮忙给拍的,感谢小伙伴@张的拍摄!!5. 参考文章和遗留问题
ttf字体文件的解析:
https://blog.csdn.net/blueangle17/article/details/23750999
https://github.com/fonttools/fonttools字符集详解:
https://blog.csdn.net/qq_28098067/article/details/53486032
字体反爬技术:
https://www.cnblogs.com/h2zZhou/p/7248261.html
遗留问题:
- 在实践中,我发现一个问题,就是下载的ttf文件,有时候是不一样的,也就是说,我们录入进程序中的wordList是有时效性的,不可能每次都下载文件,然后录入,不知道有没有模块能直接从ttf中解析字形,然后匹配到国际标准的unicode编码,这样就可以避免每次手动录入,动态解析了,懂得大神一定要私密我哦,有好礼相待~~