【第一部分】 问题总结
-
在本次代码练习中,我有一个问题:
在MobileNet V2部分的 代码练习 ,论文中conv1的stride是2,第二个Block的第一层stride也是2,为什么使用CIFAR10数据集就变成1了?将网络层改为与论文模型一样时,训练发生错误。
【第二部分】 代码练习
-
MobileNetV1 网络
-
Depthwise 和 Pointwise 见第二次作业:卷积神经网络 part 1
-
由于模型中有BatchNorm层,故在模型训练前加入model.train(),模型测试前加入model.eval()。
-
模型:
class Block(nn.Module): def __init__(self, in_planes, out_planes, stride=1): super(Block, self).__init__() # group: 输入通道分组,卷积核的大小是(in_planes/in_planes, 3, 3) self.conv1 = nn.Conv2d(in_planes, in_planes, kernel_size=3, stride=stride, padding=1, groups=in_planes, bias=False) self.bn1 = nn.BatchNorm2d(in_planes) self.conv2 = nn.Conv2d(in_planes, out_planes, kernel_size=1, stride=1, padding=0, bias=False) self.bn2 = nn.BatchNorm2d(out_planes) def forward(self, x): out = F.relu(self.bn1(self.conv1(x))) out = F.relu(self.bn2(self.conv2(out))) return out class MobileNetV1(nn.Module): cfg = [(64,1), (128,2), (128,1), (256,2), (256,1), (512,2), (512,1), (1024,2), (1024,1)] def __init__(self, num_classes=10): super(MobileNetV1, self).__init__() self.conv1 = nn.Conv2d(3, 32, kernel_size=3, stride=1, padding=1, bias=False) self.bn1 = nn.BatchNorm2d(32) self.layers = self._make_layers(in_planes=32) self.linear = nn.Linear(1024, num_classes) def _make_layers(self, in_planes): layers = [] for x in self.cfg: out_planes = x[0] stride = x[1] layers.append(Block(in_planes, out_planes, stride)) in_planes = out_planes return nn.Sequential(*layers) def forward(self, x): out = F.relu(self.bn1(self.conv1(x))) out = self.layers(out) out = F.avg_pool2d(out, 2) out = out.view(out.size(0), -1) out = self.linear(out) return out -
其测试代码:
correct = 0 total = 0 net.eval() for data in testloader: images, labels = data images, labels = images.to(device), labels.to(device) outputs = net(images) _, predicted = torch.max(outputs.data, 1) total += labels.size(0) correct += (predicted == labels).sum().item() print('Accuracy of the network on the 10000 test images: %.2f %%' % (100 * correct / total))结果:

-
-
MobileNetV2
-
论文:MobileNetV2: Inverted Residuals and Linear Bottlenecks
-
亮点: the inverted residual with linear bottleneck.
-
Inverted residual block:先用1*1的卷积升维,再用3*3的卷积运算(变成了Depthwise、计算量减少),最后用1*1的卷积降维(中间大、两边小)
Residual block:先用1*1卷积降维,然后进行3*3的卷积运算,最后再用1*1的卷积升维(中间小、两边大)
-
shortcut:防止梯度消失
-
Linear Bottlenecks:最后一层使用线性激活,而非relu——若两端通道数较少,使用relu会损失更多信息,防止relu破坏特征

-
MobileNetV1 vs MobileNetV2

-
实验所给的MobileNet V2与论文实际模型不一样,阅读论文并修改:
class MobileNetV2(nn.Module): cfg = [(1, 16, 1, 1), (6, 24, 2, 1), #change stride 2->1 for CIFAR10,可是为什么呢? (6, 32, 3, 2), (6, 64, 4, 2), (6, 96, 3, 1), (6, 160, 3, 2), (6, 320, 1, 1)] def __init__(self, num_classes=10): super(MobileNetV2, self).__init__() # change stride 2->1 for CIFAR10 self.conv1 = nn.Conv2d(3, 32, kernel_size=3, stride=1, padding=1, bias=False) self.bn1 = nn.BatchNorm2d(32) self.layers = self._make_layers(in_planes=32) self.conv2 = nn.Conv2d(320, 1280, kernel_size=1, stride=1, padding=0, bias=False) self.bn2 = nn.BatchNorm2d(1280) self.linear = nn.Linear(1280, num_classes) def _make_layers(self, in_planes): layers = [] for expansion, out_planes, num_bocks, stride in self.cfg: strides = [stride]+[1]*(num_bocks-1) for stride in strides: layers.append(Block(in_planes, out_planes, expansion, stride)) in_planes = out_planes return nn.Sequential(*layers) def forward(self, x): out = F.relu(self.bn1(self.conv1(x))) out = self.layers(out) out = F.relu(self.bn2(self.conv2(out))) # NOTE: change pooling kernel_size 7 -> 4 for CIFAR10 out = F.avg_pool2d(out, 4) out = out.view(out.size(0), -1) out = self.linear(out) return out -
模型测试及结果:
correct = 0 total = 0 net.eval() #应对BN for data in testloader: images, labels = data images, labels = images.to(device), labels.to(device) outputs = net(images) _, predicted = torch.max(outputs.data, 1) total += labels.size(0) correct += (predicted == labels).sum().item() print('Accuracy of the network on the 10000 test images: %.2f %%' % ( 100 * correct / total))结果:

-
-
HybridSN
-
网络模型——含有二维卷积和三维卷积,二维卷积是三维卷积的特例,即将三维卷积的depth设置为1
class_num = 16 class HybridSN(nn.Module): def __init__(self): super(HybridSN, self).__init__() self.L = 30 self.S = 25 self.conv1 = nn.Conv3d(1, 8, kernel_size=(7, 3, 3), stride=1, padding=0) self.conv2 = nn.Conv3d(8, 16, kernel_size=(5, 3, 3), stride=1, padding=0) self.conv3 = nn.Conv3d(16, 32, kernel_size=(3, 3, 3), stride=1, padding=0) inputX = self.get2Dinput() inputConv4 = inputX.shape[1] * inputX.shape[2] self.conv4 = nn.Conv2d(inputConv4, 64, kernel_size=(3, 3), stride=1, padding=0) num = inputX.shape[3]-2 #二维卷积后(64, 17, 17)-->num = 17 inputFc1 = 64 * num * num self.fc1 = nn.Linear(inputFc1, 256) # 64 * 17 * 17 = 18496 self.fc2 = nn.Linear(256, 128) self.fc3 = nn.Linear(128, class_num) self.dropout = nn.Dropout(0.4) def get2Dinput(self): with torch.no_grad(): x = torch.zeros((1, 1, self.L, self.S, self.S)) x = self.conv1(x) x = self.conv2(x) x = self.conv3(x) return x def forward(self, x): x = F.relu(self.conv1(x)) x = F.relu(self.conv2(x)) x = F.relu(self.conv3(x)) x = x.view(x.shape[0], -1, x.shape[3], x.shape[4]) x = F.relu(self.conv4(x)) x = x.view(-1, x.shape[1] * x.shape[2] * x.shape[3]) x = F.relu(self.fc1(x)) x = self.dropout(x) x = F.relu(self.fc2(x)) x = self.dropout(x) x = self.fc3(x) return x # 随机输入,测试网络结构是否通 # x = torch.randn(1, 1, 30, 25, 25) # net = HybridSN() # y = net(x) -
得到结果:

-
多次尝试发现,测试结果准确率并不稳定:0.9510、0.9276、0.8898
分析原因:1、训练样本过少、本实验训练数据集为1024个样本
2、在全连接层加入dropout防止过拟合时,需要在实例化的模型训练之前加入model.train(),在模型测试之前加入model.eval();
model.eval()表示测试集不启动dropout,其dropout层不发挥作用,否则因为dropout导致随机丢弃一些中间结果而使最终结果变化 -
改进模型——在训练样本数一定的情况下,提高分类性能:
-
修改学习率 lr=0.0001、batch_size=64(过大的batch_size精度下降)
模型准确率基本稳定在98%以上,得到最优准确率98.88%

-
-
注:考虑先使用二维卷积再使用三维卷积
class HybridSN(nn.Module): def __init__(self): super(HybridSN, self).__init__() self.L = 30 self.S = 25 self.conv4 = nn.Conv2d(30, 64, kernel_size=(3, 3), stride=1, padding=0) self.conv1 = nn.Conv3d(1, 8, kernel_size=(7, 3, 3), stride=1, padding=0) self.conv2 = nn.Conv3d(8, 16, kernel_size=(5, 3, 3), stride=1, padding=0) self.conv3 = nn.Conv3d(16, 32, kernel_size=(3, 3, 3), stride=1, padding=0) inputX = self.get2Dinput() inputFc1 = inputX.shape[1] * inputX.shape[2] * inputX.shape[3] * inputX.shape[4] self.fc1 = nn.Linear(inputFc1, 256) # 64 * 17 * 17 = 18496 self.fc2 = nn.Linear(256, 128) self.fc3 = nn.Linear(128, class_num) self.dropout = nn.Dropout(0.4) def get2Dinput(self): with torch.no_grad(): x = torch.zeros((1, self.L, self.S, self.S)) x = self.conv4(x) x = x.view(x.shape[0], 1, x.shape[1], x.shape[2], x.shape[3]) x = self.conv1(x) x = self.conv2(x) x = self.conv3(x) return x def forward(self, x): x = F.relu(self.conv4(x)) x = x.view(x.shape[0], 1, x.shape[1], x.shape[2], x.shape[3]) x = F.relu(self.conv1(x)) x = F.relu(self.conv2(x)) x = F.relu(self.conv3(x)) x = x.view(-1, x.shape[1] * x.shape[2] * x.shape[3] * x.shape[4]) x = F.relu(self.fc1(x)) x = self.dropout(x) x = F.relu(self.fc2(x)) x = self.dropout(x) x = self.fc3(x) return x在训练时修改学习率:
train_loader = torch.utils.data.DataLoader(dataset=trainset, batch_size=64, shuffle=True, num_workers=2) test_loader = torch.utils.data.DataLoader(dataset=testset, batch_size=256, shuffle=False, num_workers=2) # 使用GPU训练,可以在菜单 "代码执行工具" -> "更改运行时类型" 里进行设置 device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") # 网络放到GPU上 net = HybridSN().to(device) criterion = nn.CrossEntropyLoss() optimizer = optim.Adam(net.parameters(), lr=0.0001) def adjust_learning_rate(optimizer, lr): for param_group in optimizer.param_groups: param_group['lr'] = lr # 开始训练 total_loss = 0 net.train() for epoch in range(100): lr = 0.0001 if epoch > 40: lr = 0.00001 if epoch > 75: lr = 0.000001 adjust_learning_rate(optimizer, lr) for i, (inputs, labels) in enumerate(train_loader): inputs = inputs.to(device) labels = labels.to(device) # 优化器梯度归零 optimizer.zero_grad() # 正向传播 + 反向传播 + 优化 outputs = net(inputs) loss = criterion(outputs, labels) loss.backward() optimizer.step() total_loss += loss.item() print('[Epoch: %d] [loss avg: %.4f] [current loss: %.4f]' %(epoch + 1, total_loss/(epoch+1), loss.item())) print('Finished Training')经过多轮训练,结果基本稳定在98.5%以上,比起论文模型平均分类精度有提高,对比上面的改进模型分类精度差别不大。但是训练时间变长,训练效率得到降低。
分析原因:一开始使用二维卷积,使channel从30增加到64,后面使用三维卷积,其光谱维度从64维开始卷积;而先使用三维卷积,其光谱维度从30开始卷积,使模型的参数量得到极大减少,故训练时间更快!
-
【第三部分】 论文阅读
-
论文:Beyond a Gaussian Denoiser: Residual Learning of Deep CNN for Image Denoising
-
GitHub代码:https://github.com/SaoYan/DnCNN-PyTorch
-
大多数的模型有两个缺陷:
- a complex optimization problem——计算效率低
- non-convex and involve several manually chosen parameters——降噪不够充分
-
使用CNN的原因:
- 深度CNN:is effective in increasing the capacity and flexibility for exploiting image characteristics.
- 训练CNN的正则化和学习方法方面取得进步:relu、BN、残差学习
- CNN能在GPU中并行计算
-
batch normalization 和 residual learning联合使用,加速训练、促进降噪效果
-
贡献:
- 提出了一种用于高斯去噪的端到端的深度CNN
- residual learning 和 batch normalization联合使用有益于CNN学习
- 轻松扩展到一般的图像去噪任务
-
残差学习从BN算法获益:BN减轻了内部协方差转变的问题
-
BN算法从残差学习获益:DnCNN通过隐藏层的操作隐式删除the latent clean image,降低了图像的相关性
-
网络结构(conv+bn+relu的堆叠):
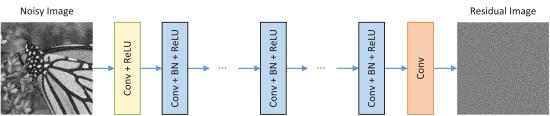
-
-
论文:Squeeze-and-Excitation Networks
-
一种通道注意力机制
-
网络结构:

-
改变特征通道之间的权重,增强对输出准确率影响较大的特征通道权重,抑制影响较小的通道特征
-
Squeeze 操作:作经平均池化(global average pooling)将图像的空间特征编码为一个实数。宽高为 (W, H) 的 二维图像 Uc 的空间编码:

-
Excitation 操作:使用两个全连接层提取通道间的非线性关系(同时也降低参数量)——先降维再升维使用sigmoid划分权重
-
SENet的应用:作为子模块嵌入网络模型中,如Inception、ResNet

-
加入SENet模块的网络模型训练花费的时间加大
-
-
论文:Deep Supervised Cross-modal Retrieval
-
图像文本匹配——致力于减少和消除样本间的差异
-
GitHub代码:https://github.com/penghu-cs/DSCMR
-
贡献:
- 提出了深度监督的跨模态学习结构,以弥补不同模态的heterogeneity gap(异质性差距)
- 最后一层使用两个具有权重共享的子网,以学习图像和文本模态间的跨模态相关性
- 使用线性分类器区分公共特征空间的样本
- 本文实验结果优于当前优秀的跨模态检测
-
网络结构:

-
两个子网络:一个图像模型、一个文本模型
-
图像模型的CNN层:VGG19(预训练)
-
文本模型:Sentence CNN、Word2Vec(预训练)
-
a linear layer is connected on the top of the image modal network and the text modal network,分类器P(如下:圆形是图像,三角形是文本)将训练数据表示在公共空间,对每个样本生成一个c维的预测标签
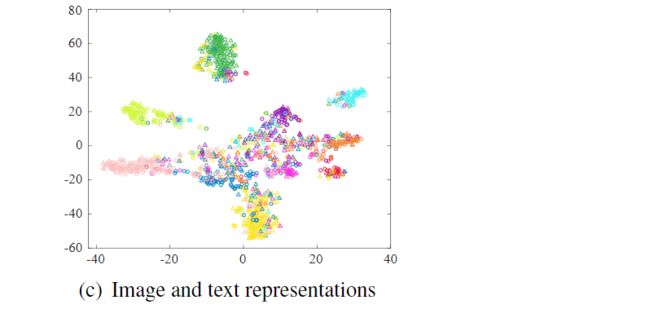
-
模型使用 J1、J2、J3 识别空间的辨别损失,具体参考此处链接
-
使用随机梯度下降优化损失函数:

-
-