依赖倒置和控制反转
依赖倒置
定义
依赖反转原则(Dependency inversion principle,DIP)是指一种特定的解耦形式,使得高层次的类不依赖于低层次的类的实现细节,依赖关系被颠倒(反转),从而使得低层次类依赖于高层次类的需求抽象。
该原则规定:
- 高层次的类不应该依赖于低层次的类,两者都应该依赖于抽象接口。
- 抽象接口不应该依赖于具体实现。而具体实现则应该依赖于抽象接口。
在传统的应用架构中,低层次的组件设计用于被高层次的组件使用,这一点提供了逐步的构建一个复杂系统的可能。在这种结构下,高层次的组件直接依赖于低层次的组件去实现一些任务。这种对于低层次组件的依赖限制了高层次组件被重用的可行性。
依赖反转原则的目的是把高层次组件从对低层次组件的依赖中解耦出来,这样使得重用不同层级的组件实现变得可能。
听起来很干,我们先通过实现一个简单的需求来描述依赖倒置原则要解决的问题。
需求
假设我们要实现一个简单的缓存功能,主要负责把数据存储起来方便以后调用。
为了快速完成需求,我们决定采用最简单的实现方式:存储到文件,所以我们设计其结构如下:
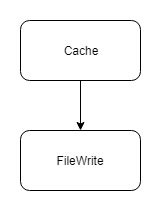
图 1 显示在应用程序中一共有两个类。“Cache” 类负责调用"FileWrite"类来写入文件。代码实现如下:
class FileWriter{
public function writeToFile($key,$value=null){
//....
}
}
class Cache{
protected FileWriter $file_writer;
public function __contruct(){
$this->file_writer=new FileWriter();
}
public function set($key,$value=null){
$this->file_writer->writeToFile($key,$value);
}
}
在所有使用文件来作为存储方式的系统中,上面的"Cache"类能很好的使用,然而在以其他方式来存储的系统中,“Cache” 类是无法被重用的。
例如,假设我们的系统是分布式服务,部署在多台机器上,这时候如果使用文件存储则缓存只能生效于本机器上,无法被其他机器使用,故我们无法使用文件来作为缓存的存储方式,所以我们引入一个新的存储方式:redis。另外我们也希望复用 “Cache” 类,但很不幸的是, “Cache” 类是直接依赖于 “FileWrite” 类的,无法直接被重用。
为了解决这个问题,我们需要修改下代码,如下:
class FileWriter{
public function writeToFile($key,$value=null){
//....
}
}
class RedisWriter{
public function writeToRedis($key,$value=null){
//....
}
}
class Cache{
protected FileWriter $file_writer;
protected RedisWriter $redis_writer;
protected $type;
public function __contruct($type){
$this->type=$type;
if($this->type=='redis'){
$this->file_writer=new FileWriter();
}else if($this->type=='file'){
$this->redis_writer=new RedisWriter();
}
}
public function set($key,$value=null){
if($this->type=='redis'){
$this->file_writer->writeToRedis($key,$value);
}else if($this->type=='file'){
$this->file_writer->writeToFile($key,$value);
}
}
}
可以看到我们需要引入一个新的类,而且需要去修改"Cache"类的代码。随着需求的变化,我们可能有要支持其他的存储方式,例如数据库,memcached,这时候我们就需要不断添加新的类,不断修改"Cache"类,而且把"Cache"淹没在凌乱的"if/else"判断中,这样的设计的维护和拓展成本简直不可想象。
出现这些问题的原因就在于类间的相互依赖,主要特征是包含高层逻辑的类依赖于低层类的细节:"Cache"类的"set"功能完全依赖于下面的"FileWriter"的具体实现细节,导致在使用环境发生变化的时候,"Cache"类无法复用。依赖倒置原则就是为了来解决这个问题的。
问题
- 没有抽象,耦合度高:当低层模块变动时,高层模块也得变动;
- 高层模块过度依赖低层模块,很难扩展。
- 这种依赖关系具有传递性,即如果是多层次的调用,最低层改动会影响较高层……直到最高层。
解决
高层次的类不应该依赖于低层次的类,两者都应该依赖于抽象接口:例如 “Cache” 类依赖于 “FileWriter” 类的实现,所以才会无法适用使用环境的变化。所以我们要想办法使 “Cache” 类不依赖于这些细节,因为具体实现是不断变化的,而抽象接口是相对稳定的,所以我们要把数据的存储抽象出来,成为一个接口,针对这个接口进行编程,这样就无需面对频繁变化的实现细节。
抽象接口不应该依赖于具体实现。而具体实现则应该依赖于抽象接口:在一开始做设计的时候,我们不要去考虑具体实现,而应该根据业务需求去设计接口,例如上面的例子,我们一开始就已经考虑到了用文件来存储了,而且架构也是基于此来进行设计的,这就从一开始是高层次的类依赖于具体实现了。然而实际上我们需要的功能是:数据存储,把数据存储到某个地方,至于具体怎么存储我们其实并不需要关心,只需要知道能存即可,所以我们一开始设计的时候就不应该针对文件存储来进行编程,而应该针对抽象的存储接口来编程。同时具体实现也依据接口来进行编程。
因此我们优化后的架构如下:
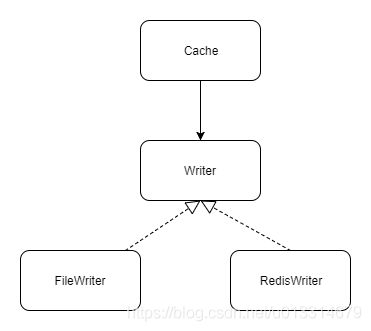
此时类 “Cache” 既没有依赖 “FileWriter” 也没有依赖 “RedisWriter”,而是依赖于接口"Writer",同时"FileWriter" 和 “RedisWriter” 的具体实现也依赖于抽象。
interface Writer{
public writer($key,$value=null);
}
class FileWriter implement Writer{
public function write($key,$value=null){
//....
}
}
class RedisWriter{
public function write($key,$value=null){
//....
}
}
class Cache{
protected Writer $writer;
public function __contruct(){
//$this->wirter=new RedisWriter();
$this->wirter=new FileWriter();
}
public function set($key,$value=null){
$this->file_writer->write($key,$value);
}
}
此时,我们就可以重用 “Cache” 类,而不需要具体的"Writer"。在不同的环境条件下,我们只需要修改生成的"writer"类即可,"set"方法里面的逻辑完全不需要改动,因为这里面是针对抽象接口"Writer"编程,只要"Writer"没有变,"set"方法也不需要做任何修改。
使用场景
程序中所有的依赖关系都应该终止于抽象类或者接口中,而不应该依赖于具体类。
根据这个启发式规则,编程时可以这样做:
- 类中的所有成员变量必须是接口或抽象,不应该持有一个指向具体类的引用或指针。
- 任何类都不应该从具体类派生,而应该继承抽象类,或者实现接口。
- 任何方法都不应该覆写它的任何基类中已经实现的方法。(里氏替换原则)
- 任何变量实例化都需要实现创建模式(如:工厂方法/模式),或使用依赖注入框架(如:Spring IOC)。
优点
- 高层模块和低层模块彻底解耦,都很容易实现扩展
- 抽象模块具有很高的稳定性、可重用性,对高/低层模块来说才是真正"可依赖的"。
缺点
- 增加了一层抽象层,增加实现难度;
- 对一些简单的调用关系来说,可能是得不偿失的。
- 对一些稳定的调用关系,反而增加复杂度,是不正确的。
控制反转
说完依赖倒置,我们再来说一个很相似的设计原则:控制反转。
看看上面的代码,虽然"set"方法里的逻辑不会发现变化了,但是在构造函数里还是要根据不同环境来生成对应的"Writer",还是需要修改代码,为了解决这个问题,我们引入控制反转的原则。
定义
控制反转(Inversion of Control,缩写为IoC ),是面向对象编程中的一种设计原则,可以用来减低计算机代码之间的耦合度。其中最常见的方式叫做依赖注入(Dependency Injection,简称DI),还有一种方式叫“依赖查找”(Dependency Lookup)。通过控制反转,对象在被创建的时候,由一个调控系统内所有对象的外界实体,将其所依赖的对象的引用传递给它。也可以说,依赖被注入到对象中。
控制反转针对的是依赖对象的获得方式,也既依赖对象不在是自己内部生成,而是由外界生成后传递进来。如下代码:
interface Writer{
public writer($key,$value=null);
}
class FileWriter implement Writer{
public function write($key,$value=null){
//....
}
}
class RedisWriter{
public function write($key,$value=null){
//....
}
}
class Cache{
protected Writer $writer;
public function __contruct(Writer $writer){
$this->wirter=$writer
}
public function set($key,$value=null){
$this->file_writer->write($key,$value);
}
}
"Cache"把内部依赖"Writer"的创建权力移交给了上层模块,自己只关心依赖提供的功能,但并不关心依赖的创建。IoC 是一种新的设计模式,它对上层模块与底层模块进行了更进一步的解耦。
实现方式
实现控制反转主要有两种方式:依赖注入和依赖查找。两者的区别在于,前者是被动的接收对象,在类A的实例创建过程中即创建了依赖的B对象,通过类型或名称来判断将不同的对象注入到不同的属性中,而后者是主动索取相应类型的对象,获得依赖对象的时间也可以在代码中自由控制。
依赖注入
依赖注入有如下实现方式:
- 基于构造函数。实现特定参数的构造函数,在新建对象时传入所依赖类型的对象。
class Cache{
protected Writer $writer;
public function __contruct(Writer $writer){
$this->wirter=$writer
}
}
- 基于 set 方法。实现特定属性的public set方法,来让外部容器调用传入所依赖类型的对象。
class Cache{
protected Writer $writer;
public function setWriter(Writer $writer){
$this->wirter=$writer
}
}
- 基于接口。实现特定接口以供外部容器注入所依赖类型的对象。
interface WriterSetter {
public function setWriter(Writer $writer);
}
class Cache implement WriterSetter{
protected Writer $writer;
@Override
public function setWriter(Writer $writer){
$this->wirter=$writer
}
}
接口注入和setter方法注入类似,不同的是接口注入使用了统一的方法来完成注入,而setter方法注入的方法名称相对比较随意,接口的存在,表明了一种依赖配置的能力。
在软件框架中,读取配置文件,然后根据配置信息,框架动态将一些依赖配置给特定接口的类,我们也可以说 Injector 也依赖于接口,而不是特定的实现类,这样进一步提高了准确性与灵活性。
依赖查找
依赖查找相比于依赖注入更加主动,先配置好对象的生成规则,然后在需要的地方通过主动调用框架提供的方法,根据相关的配置文件路径、key等信息来获取对象。
例如lumen里面:
app()->bind('classA', function ($app) {
return new ClassA();
});
//使用
$classA=app()->make('classA');
参考
https://zh.wikipedia.org/wiki/%E4%BE%9D%E8%B5%96%E5%8F%8D%E8%BD%AC%E5%8E%9F%E5%88%99
https://zh.wikipedia.org/wiki/%E6%8E%A7%E5%88%B6%E5%8F%8D%E8%BD%AC
https://blog.csdn.net/briblue/article/details/75093382
Enjoy it !
如果觉得文章对你有用,可以赞助我喝杯咖啡~
版权声明
转载请注明作者和文章出处
作者: X先生
https://blog.csdn.net/u013314679/article/details/105655583