Hadoop伪分布式系统搭建、运行和遇到的问题
之前学习Hadoop都是运行的本地模式,现在到了搭建伪分布式系统阶段。理论和实践必须结合进行,看书能看懂是一回事,亲自上手实践又是另一回事,会遇到各种问题。而有些是自身理解和操作错误可能很是棘手。下面一步步来吧!
1.安装Java
要想能够搭建伪分布式系统前提是安装Java(按照自己的电脑是32位还是64对应下载),然后配置环境变量JAVA_HOME。本人用的MacOS系统,因而环境变量在.bash_profile文件中。命令终端输入:vim .bash_profile,在文件中添加两句代码保存即可。
export JAVA_HOME=/Library/Java/JavaVirtualMachines/jdk1.8.0_191.jdk/Contents/Home
export PATH=$PATH:$JAVA_HOME/bin命令行输入:java -version回车,显示如下信息即java配置成功。
java version "1.8.0_191"
Java(TM) SE Runtime Environment (build 1.8.0_191-b12)
Java HotSpot(TM) 64-Bit Server VM (build 25.191-b12, mixed mode)2.安装Hadoop
下载好Hadoop发布包(我的是hadoop-2.8.5),并在本地目录解压缩,我的电脑是/usr/local下。鉴于Hadoop用户的home目录可能挂在在NFS上面,所以Hadoop系统最好不要安装在该目录上面:
cd /usr/local
sudo tar xzf hadoop-2.8.5.tar.gz最好将Hadoop文件的拥有者改为hadoop用户和组,为了学习阶段的方便我们可以把权限设置的大一些,目录下所有的文件赋予可读可写可执行权限:
sudo chown -R 777 hadoop:hadoop hadoop-2.8.5然后和Java一样配置环境变量:
export HADOOP_HOME=/usr/local/hadoop-2.8.5
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/binhadoop version
Hadoop 2.8.5
Subversion https://git-wip-us.apache.org/repos/asf/hadoop.git -r 0b8464d75227fcee2c6e7f2410377b3d53d3d5f8
Compiled by jdu on 2018-09-10T03:32Z
Compiled with protoc 2.5.0
From source with checksum 9942ca5c745417c14e318835f420733
This command was run using /usr/local/hadoop-2.8.5/share/hadoop/common/hadoop-common-2.8.5.jar表明Hadoop安装正确。
3.SSH配置
在伪分布模式下工作时必须启动守护进程,而启动守护进程的前提是使用需要提供的脚本成功安装SSH。在伪分布模式下,主机就是本地计算机(loclahost),因此需要确保用户能够用SSH连接到本地主机,并且可以不输入密码登陆。首先,确保SSH已经正确安装,且服务器正在运行。因为MacOS本身自带SSH所以省略了安装。然后基于空口令生成一个新SSH密钥,以实现无密码登陆。
ssh-kengen -t rsa -P '' -f /Users/mymac/.ssh/id_rsa
cat /Users/mymac/.ssh/id_rsa.pub >> /Users/mymac/.ssh/authorized_keys
ssh localhostssh localhost
Last login: Sat Dec 29 13:35:03 2018如果成功,则无需键入密码。
4.Hadoop配置文件
默认情况下,Hadoop的配置文件是放在/usr/local/hadoop-2.8.5/etc/hadoop目录下面。我的做法是将其复制出来放到别的地方,这样可以将配置文件和安装文件隔离开来。但是需要将环境变量HADOOP_CONF_DIR设置成指向的那个新目录。
cp -p /usr/local/hadoop-2.8.5/etc/hadoop /Users/mymac/hadoop-config这里我把Hadoop生成的日志文件也给了一个指向。
export HADOOP_CONF_DIR=/Users/mymac/hadoop-config在伪分布模式下,使用如下的简单内容创建配置文件:
core-site.xml:
fs.defaultFS
hdfs://localhost/
hdfs-site.xml:
dfs:replication
1
mapred-site.xml:
mapreduce.framework.name
yarn
yarn-site.xml:
yarn.resourcemanager.hostname
localhost
yarn.nodemanager.aux-services
mapreduce_shuffle
5.格式化HDFS文件系统:
我在搭建系统的时候忘记先格式化HDFS文件系统了,结果出现了问题。所以说理论和上手实践是两个概念啊,你一上手实践会犯各种奇葩问题。然后在一一解决,不过给自己一些试错的机会,这样印象更深。
mymacdeMac-mini:~ mymac$ hadoop fs -ls
18/12/29 15:27:32 WARN ipc.Client: Failed to connect to server: localhost/127.0.0.1:8020: try once and fail.
java.net.ConnectException: Connection refused
at sun.nio.ch.SocketChannelImpl.checkConnect(Native Method)
at sun.nio.ch.SocketChannelImpl.finishConnect(SocketChannelImpl.java:717)
at org.apache.hadoop.net.SocketIOWithTimeout.connect(SocketIOWithTimeout.java:206)
at org.apache.hadoop.net.NetUtils.connect(NetUtils.java:531)
at org.apache.hadoop.ipc.Client$Connection.setupConnection(Client.java:685)
at org.apache.hadoop.ipc.Client$Connection.setupIOstreams(Client.java:788)
at org.apache.hadoop.ipc.Client$Connection.access$3500(Client.java:410)
at org.apache.hadoop.ipc.Client.getConnection(Client.java:1550)
at org.apache.hadoop.ipc.Client.call(Client.java:1381)
at org.apache.hadoop.ipc.Client.call(Client.java:1345)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:227)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:116)
at com.sun.proxy.$Proxy10.getFileInfo(Unknown Source)
at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolTranslatorPB.getFileInfo(ClientNamenodeProtocolTranslatorPB.java:796)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.hadoop.io.retry.RetryInvocationHandler.invokeMethod(RetryInvocationHandler.java:409)
at org.apache.hadoop.io.retry.RetryInvocationHandler$Call.invokeMethod(RetryInvocationHandler.java:163)
at org.apache.hadoop.io.retry.RetryInvocationHandler$Call.invoke(RetryInvocationHandler.java:155)
at org.apache.hadoop.io.retry.RetryInvocationHandler$Call.invokeOnce(RetryInvocationHandler.java:95)
at org.apache.hadoop.io.retry.RetryInvocationHandler.invoke(RetryInvocationHandler.java:346)
at com.sun.proxy.$Proxy11.getFileInfo(Unknown Source)
at org.apache.hadoop.hdfs.DFSClient.getFileInfo(DFSClient.java:1649)
at org.apache.hadoop.hdfs.DistributedFileSystem$27.doCall(DistributedFileSystem.java:1440)
at org.apache.hadoop.hdfs.DistributedFileSystem$27.doCall(DistributedFileSystem.java:1437)
at org.apache.hadoop.fs.FileSystemLinkResolver.resolve(FileSystemLinkResolver.java:81)
at org.apache.hadoop.hdfs.DistributedFileSystem.getFileStatus(DistributedFileSystem.java:1437)
at org.apache.hadoop.fs.Globber.getFileStatus(Globber.java:64)
at org.apache.hadoop.fs.Globber.doGlob(Globber.java:269)
at org.apache.hadoop.fs.Globber.glob(Globber.java:148)
at org.apache.hadoop.fs.FileSystem.globStatus(FileSystem.java:1686)
at org.apache.hadoop.fs.shell.PathData.expandAsGlob(PathData.java:326)
at org.apache.hadoop.fs.shell.Command.expandArgument(Command.java:245)
at org.apache.hadoop.fs.shell.Command.expandArguments(Command.java:228)
at org.apache.hadoop.fs.shell.FsCommand.processRawArguments(FsCommand.java:103)
at org.apache.hadoop.fs.shell.Command.run(Command.java:175)
at org.apache.hadoop.fs.FsShell.run(FsShell.java:317)
at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:76)
at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:90)
at org.apache.hadoop.fs.FsShell.main(FsShell.java:380)
ls: Call From mymacdeMac-mini.local/192.168.1.4 to localhost:8020 failed on connection exception: java.net.ConnectException: Connection refused; For more details see: http://wiki.apache.org/hadoop/ConnectionRefused
即然没有格式化,那就先格式化好了。格式化就是一条指令:
hdfs namenode -format18/12/29 15:57:39 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: user = mymac
STARTUP_MSG: host = mymacdeMac-mini.local/192.168.1.4
STARTUP_MSG: args = [-format]
STARTUP_MSG: version = 2.8.5
STARTUP_MSG: classpath = “这里省略一堆jar包文件”
STARTUP_MSG: build = https://git-wip-us.apache.org/repos/asf/hadoop.git -r 0b8464d75227fcee2c6e7f2410377b3d53d3d5f8; compiled by 'jdu' on 2018-09-10T03:32Z
STARTUP_MSG: java = 1.8.0_191
************************************************************/
此处省略。。。。。。。。
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at mymacdeMac-mini.local/192.168.1.4
************************************************************/
6.启动守护进程和终止守护进程:
格式化完HDFS文件系统,接下来就是启动HDFS、YARN和MapReduce守护进程了。
start-dfs.sh
start-yarn.sh
mr-jobhistory-daemon.sh start historyserver我是分开启动的各个进程,不过也可以使用start-all.sh来启动,这样来的方便。但是我在尝试start-all.sh启动时,出现过问题就是namenode没有启动,原因未知。
mymacdeMac-mini:~ mymac$ start-dfs.sh
Starting namenodes on [localhost]
localhost: starting namenode, logging to /usr/local/hadoop-2.8.5/logs/hadoop-mymac-namenode-mymacdeMac-mini.local.out
localhost: starting datanode, logging to /usr/local/hadoop-2.8.5/logs/hadoop-mymac-datanode-mymacdeMac-mini.local.out
Starting secondary namenodes [0.0.0.0]
0.0.0.0: starting secondarynamenode, logging to /usr/local/hadoop-2.8.5/logs/hadoop-mymac-secondarynamenode-mymacdeMac-mini.local.out我们看到,namenode、datanode、辅助namenode相继启动。
mymacdeMac-mini:~ mymac$ start-yarn.sh
starting yarn daemons
starting resourcemanager, logging to /usr/local/hadoop-2.8.5/logs/yarn-mymac-resourcemanager-mymacdeMac-mini.local.out
localhost: starting nodemanager, logging to /usr/local/hadoop-2.8.5/logs/yarn-mymac-nodemanager-mymacdeMac-mini.local.out我们看到,资源管理器和节点管理器相继启动。
mymacdeMac-mini:~ mymac$ mr-jobhistory-daemon.sh start historyserver
starting historyserver, logging to /usr/local/hadoop-2.8.5/logs/mapred-mymac-historyserver-mymacdeMac-mini.local.outMapReduce守护进程只是日志记录服务。
以上是启动各守护进程,当然停止进程可以输入下列指令:
stop-dfs.sh
stop-yarn.sh
mr-jobhistory-daemon.sh stop historyserver7.创建用户目录:
我们需要一个目录来保存上传的数据源文件和作业后的输出文件。
hadoop fs -mkdir -p /user/$USER
mymacdeMac-mini:~ mymac$ hadoop fs -mkdir -p /user/$USER
mymacdeMac-mini:~ mymac$ hadoop fs -ls hdfs://localhost/user
Found 1 items
drwxr-xr-x - mymac supergroup 0 2018-12-29 16:20 hdfs://localhost/user/mymac
mymacdeMac-mini:~ mymac$
8.上传作业需要的资源文件
伪分布模式搭建完毕,现在来试运行一下作业任务 。

这个是Hadoop WebUI界面。(说明Hadoop启动成功)
接下来,需要把自己编写的作业打包成jar文件上传到HDFS中。
mymacdeMac-mini:~ mymac$ hadoop fs -put /Users/mymac/Desktop/hadooptest/MaxTemperature.jar hdfs://localhost/user/mymac/
mymacdeMac-mini:~ mymac$ hadoop fs -put /Users/mymac/Desktop/1901 hdfs://localhost/user/mymac/
mymacdeMac-mini:~ mymac$ hadoop fs -ls /user/mymac/
Found 2 items
-rw-r--r-- 2 mymac supergroup 888190 2018-12-29 16:32 /user/mymac/1901
-rw-r--r-- 2 mymac supergroup 17373 2018-12-29 16:32 /user/mymac/MaxTemperature.jar下面运行作业:
mymacdeMac-mini:~ mymac$ export HADOOP_CLASSPATH=/Users/mymac/Desktop/hadooptest/MaxTemperature.jar
mymacdeMac-mini:~ mymac$ hadoop com.hadoop.test.hadooptest.MaxTemperature /user/mymac/1901 /user/mymac/output
18/12/29 16:36:50 INFO client.RMProxy: Connecting to ResourceManager at localhost/127.0.0.1:8032
18/12/29 16:36:50 WARN mapreduce.JobResourceUploader: Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this.
18/12/29 16:36:50 INFO input.FileInputFormat: Total input files to process : 1
18/12/29 16:36:51 INFO mapreduce.JobSubmitter: number of splits:1
18/12/29 16:36:51 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1546071058316_0001
18/12/29 16:36:52 INFO impl.YarnClientImpl: Submitted application application_1546071058316_0001
18/12/29 16:36:52 INFO mapreduce.Job: The url to track the job: http://192.168.1.4:8088/proxy/application_1546071058316_0001/
18/12/29 16:36:52 INFO mapreduce.Job: Running job: job_1546071058316_0001
18/12/29 16:37:00 INFO mapreduce.Job: Job job_1546071058316_0001 running in uber mode : false
18/12/29 16:37:00 INFO mapreduce.Job: map 0% reduce 0%
18/12/29 16:37:06 INFO mapreduce.Job: map 100% reduce 0%
18/12/29 16:37:12 INFO mapreduce.Job: map 100% reduce 100%
18/12/29 16:37:12 INFO mapreduce.Job: Job job_1546071058316_0001 completed successfully
18/12/29 16:37:12 INFO mapreduce.Job: Counters: 49
File System Counters
FILE: Number of bytes read=72210
FILE: Number of bytes written=459613
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=888287
HDFS: Number of bytes written=29
HDFS: Number of read operations=6
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=1
Launched reduce tasks=1
Data-local map tasks=1
Total time spent by all maps in occupied slots (ms)=3252
Total time spent by all reduces in occupied slots (ms)=3075
Total time spent by all map tasks (ms)=3252
Total time spent by all reduce tasks (ms)=3075
Total vcore-milliseconds taken by all map tasks=3252
Total vcore-milliseconds taken by all reduce tasks=3075
Total megabyte-milliseconds taken by all map tasks=3330048
Total megabyte-milliseconds taken by all reduce tasks=3148800
Map-Reduce Framework
Map input records=6565
Map output records=6564
Map output bytes=59076
Map output materialized bytes=72210
Input split bytes=97
Combine input records=0
Combine output records=0
Reduce input groups=1
Reduce shuffle bytes=72210
Reduce input records=6564
Reduce output records=1
Spilled Records=13128
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=116
CPU time spent (ms)=0
Physical memory (bytes) snapshot=0
Virtual memory (bytes) snapshot=0
Total committed heap usage (bytes)=304087040
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=888190
File Output Format Counters
Bytes Written=29
查看一下作业输出文件:
mymacdeMac-mini:~ mymac$ hadoop fs -ls /user/mymac/
Found 3 items
-rw-r--r-- 3 mymac supergroup 888190 2018-12-29 16:32 /user/mymac/1901
-rw-r--r-- 3 mymac supergroup 17373 2018-12-29 16:32 /user/mymac/MaxTemperature.jar
drwxr-xr-x - mymac supergroup 0 2018-12-29 16:46 /user/mymac/output
mymacdeMac-mini:~ mymac$
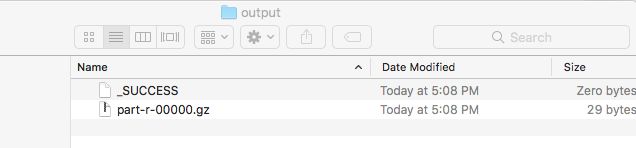
mymacdeMac-mini:~ mymac$ hadoop fs -ls /user/mymac/output
Found 2 items
-rw-r--r-- 3 mymac supergroup 0 2018-12-29 16:46 /user/mymac/output/_SUCCESS
-rw-r--r-- 3 mymac supergroup 29 2018-12-29 16:46 /user/mymac/output/part-r-00000.gz
注:在运行作业的时候可能会出现以下的问题"/bin/bash: /bin/java: is not a directory".
Job job_1537433842491_0002 failed with state FAILED due to: Application application_1537433842491_0002 failed 2 times due to AM Container for appattempt_1537433842491_0002_000002 exited with exitCode: 127
Container id: container_1537433842491_0002_02_000001
Exit code: 127
Stack trace: ExitCodeException exitCode=127:
at org.apache.hadoop.util.Shell.runCommand(Shell.java:585)
at org.apache.hadoop.util.Shell.run(Shell.java:482)
at org.apache.hadoop.util.Shell$ShellCommandExecutor.execute(Shell.java:776)
at org.apache.hadoop.yarn.server.nodemanager.DefaultContainerExecutor.launchContainer(DefaultContainerExecutor.java:212)
at org.apache.hadoop.yarn.server.nodemanager.containermanager.launcher.ContainerLaunch.call(ContainerLaunch.java:302)
at org.apache.hadoop.yarn.server.nodemanager.containermanager.launcher.ContainerLaunch.call(ContainerLaunch.java:82)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)原因是MapReduce的application master在启动container的时候,会用到java编译。脚本会在/bin/java当中查找,然而MacOS的java在/usr/bin/java中,没有找到所以会报错。所以尝试建立一个软连接就可以解决问题了。
sudo ln -s /usr/bin/java /bin/java9.下载完成的作业文件:
mymacdeMac-mini:~ mymac$ hadoop fs -get /user/mymac/output /Users/mymac/Desktop/output