python大作业——B站弹幕数据爬取与分析
前段时间要写一个Python大作业,选题为B站弹幕数据分析,由于是Python新手,所以参考了以下的文档,再次感谢分享技术的人
同时也因为本次是只是本人记录一次初学Python期间的一次较有意思的大作业,语法简陋勿喷。参考文档:https://blog.csdn.net/weixin_34161029/article/details/91713988
B站弹幕数据分析
-
第一部分——使用爬虫抓取弹幕数据
-
B站弹幕数据分析,首先我们需要抓取到B站视频的弹幕数据,才能进行数据分析
-
选取分析的对象是B站UP主 观视频工作室 的**《睡前消息》** 系列视频中的最新15期,即 110-124期视频(2020-05-03 ~ 2020-06-05) 的弹幕作为本次分析的弹幕,爬取的日期从第110期发布的日期开始到爬取的时候**(2020-05-03 ~ 2020-06-09)**
-
首先需要从 观视频工作室 的个人主页处找到 睡前消息 频道,爬这里就可以获取到所需要的视频链接,页面是动态页面,所以这里选择用 selenium库 爬取链接,存进Link.txt文件备用
注意这里我用的是比较偷懒的爬取方法,只能爬到最新15期,要爬其他的可以自己改进一下算法
-
在视频页的console处可以输入window.cid来获取cid,但在selenium模拟中往浏览器console处输入的方法,搜索苦久无果,所以想出了如此下策:在视频页打开F12,在elements处搜索cid,发现是有的,这条语句是与网关有关的,通过bs4匹配到该语句,用正则匹配出来即可
正则前缀/ 后缀-1-
-
要爬取B站的弹幕,有两种方法 ( 据我所知 )
5.1 第一种方法 是https://comment.bilibili.com/{cid}.xml,这种方法可以获得最新的maxlimit数量(一般这个数量是3000)的弹幕,但是没办法获得历史弹幕
5.2 第二种方法 是https://api.bilibili.com/x/v2/dm/history?type=1&oid={cid}&date={yyyy-mm-dd},这种方法可以获取从某一天开始的maxlimit数量的弹幕,把想要获得的日期遍历一遍,虽然可能会漏掉一些弹幕(比如某一天弹幕数超过了maxlimit,就获取不到超出的部分),但也算是获取了大部分弹幕,比上一种方法好,采取这种方法
而第二个方法由于是api,所以需要用到cookie,可以用以下的方法来获取cookie
-
接下来就是分析这个xml文件中的弹幕数据,例子为如下:
脱发 这个 p字段 中的参数含义为如下:(百度搜索得到的答案)
第一个参数 369.34300 记作DM_time,是弹幕在视频中出现的时间,以秒数为单位。
第二个参数 1 记作DM_mode,是弹幕的模式1…3 滚动弹幕 4底端弹幕 5顶端弹幕 6.逆向弹幕 7精准定位 8高级弹幕
第三个参数 25 记作DM_font,是字号, 12非常小,16特小,18小,25中,36大,45很大,64特别大
第四个参数 16777215 记作DM_color,是字体的颜色以HTML颜色的十进制为准
第五个参数 1590515762 记作DM_realTime,是发送弹幕的时间戳
第六个参数 0 记作DM_pool,是弹幕池 0普通池 1字幕池 2特殊池(高级弹幕)
第七个参数 a6fb6c47 记作DM_userID,是发送者的ID,用于“屏蔽此弹幕的发送者”功能
第八个参数 33226011652915207 记作DM_id,是弹幕在弹幕数据库中rowID,也就是这条弹幕是历史总弹幕的第几条
p字段以外的 弹幕本体 记作DM_text
-
把爬取到的弹幕分别放到多个csv文件中,每一期一个csv文件,方便后面的数据分析
-
至此爬取数据部分完成
-
-
第二部分——使用Pandas库进行数据分析
-
在爬取并保存了所有弹幕数据之后,先进行去重,可对比还未去重时文件的大小和去重后文件的大小
1.1 未去重:(至于110-112和113-124日期不一样,是因为抓113-124的时候被封了IP,只能等到第二天早上抓110-112)

1.2 去重后:

-
然后进行如下的可视化分析:
2.1 每一期弹幕总数的变化 折线图
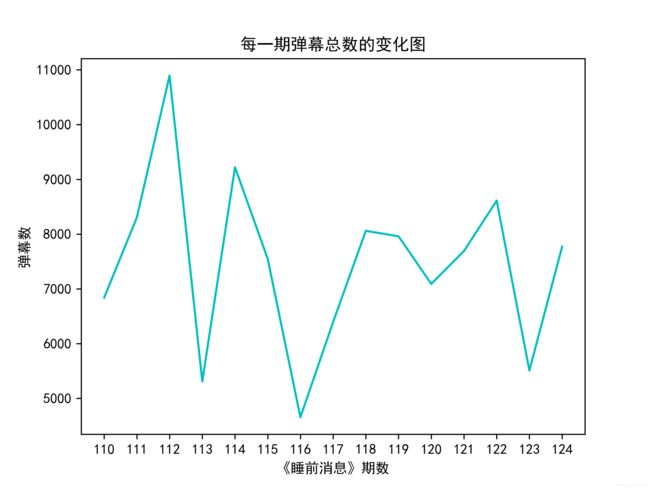
结合上图,我们发现每期的弹幕总数统计波动有些大,其中一些弹幕数,比如116期,甚至在这里统计只有不到5000条,但是在B站上可以看到:

这一期其实总弹幕是有1.4W的,统计到的弹幕数仅占1/3左右,出现这种情况是由于 在视频发出的某一天里,大多数用户发过了弹幕,而这部分弹幕超出了B站统计的maxlimit ,导致我们没办法统计到这部分弹幕。
相对而言,弹幕数多的视频就是弹幕不仅仅在某一天大量被发出,比如115期,这里我们统计到了有**9000+**的弹幕数,而B站上的数据:

统计到的弹幕大约占70%,这是由于并没有很多用户在某一个日期大量发出弹幕,导致弹幕库溢出,也从某方面说明了该视频的受众时间较广,是一个较为优质的视频。
另外,加上我去把每期的标题和弹幕数一对应,发现,涉及到 国与国之间的时评 的时候,在播放量相差不多的情况下,视频的受众时间会比较广,相对的,谈论的时事范围或格局越小,受众时间会相对应减小。当然这些都是通过一小部分数据得出的结论,不能代表完全的趋势就是这样。
2.2 统计发弹幕总数TOP10 的用户 横向柱状图

一共15期的节目,根据不完全统计,这位ID为 13631380 的用户一共发了160+条弹幕,平均每一期要发11条弹幕,是真爱粉无误了。
2.3 统计每期弹幕密度变化图 (图太多,只放了总体的缩略图)
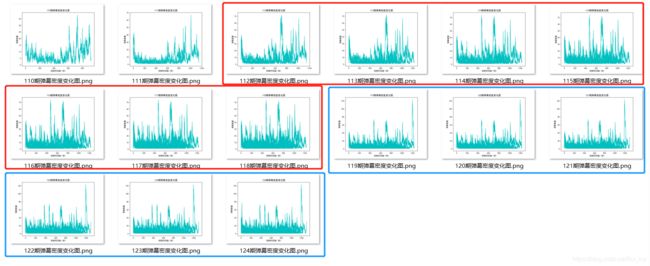
首先从个体上观察这些弹幕密度图,发现弹幕都是较为均匀的,但从总体上观察这些弹幕密度图的时候,发现其中112-118期的弹幕密度图极其相似,119-124期的弹幕密度图也是极其相似,总的来说,112-124期都会有一个密度大且会持续一小段时间的“弹幕风云”,更巧的是,这部分都集中在视频时间700秒左右,也就是11分-13分之间会有一波弹幕的小高潮。
为此我特意去再次观看**《睡前消息》,发现在112-118期中,节目大概都在15~20分钟左右,而在11-13分钟的时候,也就是在视频时间过去大概70%**左右的时候,主持人都会作出一些毒辣的点评,从而引起弹幕的激烈讨论。
2.4 绘制出每期视频的弹幕词云 (取其中几个词云图展示)
由于我设置了最小字体为10,所以如果是弹幕种类分布得比较广泛的视频,留白处会比较多,这里我选取了较为饱满的弹幕词云图作为展示
【睡前消息111】深圳房价这样涨下去,会变成第二个香港么?

【睡前消息112】阅文风波的背后,腾讯真的大到只手遮天了吗?

【睡前消息118】《后浪》过后,如何看待B站又要《入海》?

可见弹幕里面的 同意 支持 保护 之类的字眼比较多,**仅观表象的话 **可以说明,虽然该节目主持人虽嘴巴毒辣,在视频弹幕里会造成不少的人激烈讨论,但还是有大部分人同意这些观点的。
项目代码
-
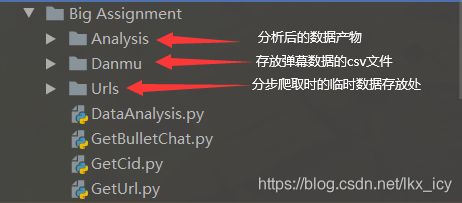
项目目录结构
-
GetUrl.py
from bs4 import BeautifulSoup from selenium import webdriver url = 'https://space.bilibili.com/54992199/channel/detail?cid=82529' print("开始爬取《睡前消息》第110-124期视频地址") # chrome驱动,需要放在Python安装的目录下 driver = webdriver.Chrome(r"E:\Python\chromedriver.exe") driver.get(url) data = driver.page_source soup = BeautifulSoup(data, 'lxml') count=1 res = [] all = soup.find_all('li', attrs={'class': 'small-item fakeDanmu-item'}) for li in all: if count<=15: a=li.find('a',attrs={'class':'cover cover-normal'}) res.append('https:'+a.get("href")) count+=1 else: break with open('Urls/Link.txt', 'w') as f: for link in res: f.write(link+'\n') print("已将全部链接放入到Link.txt文件中") -
GetCid.py
from bs4 import BeautifulSoup from selenium import webdriver import re import time cids=[] Urls=[] with open('Urls/Link.txt', 'r') as f: for line in f.readlines(): Urls.append(line.strip()) print("开始爬取《睡前消息》第110-124期视频的Cid") # chrome驱动,需要放在Python安装的目录下 driver = webdriver.Chrome(r"E:\Python\chromedriver.exe") for url in Urls: driver.get(url) data = driver.page_source soup = BeautifulSoup(data, 'lxml') all = soup.find_all('script') for a in all: if str(a).startswith("
-