Hadoop 的三种运行模式_本地模式_伪分布式模式
演示的版本是:2.7.2 官方文档
Hadoop运行模式
Hadoop运行模式包括:本地模式、伪分布式模式以及完全分布式模式。
Hadoop官方网站:http://hadoop.apache.org/
1、本地运行模式
a) 官方Grep案例
其实就是按照给定的条件找到符合条件的单词。

$ mkdir input //1、创建在hadoop-2.7.2文件下面创建一个input文件夹
$ cp etc/hadoop/*.xml input //2、将Hadoop的xml配置文件复制到input
$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar grep input output 'dfs[a-z.]+' //3、执行share目录下的MapReduce程序
$ cat output/* //4、查看输出结果
官方给的样例就是把 etc/haddop/ 里面所有以 .xml 结尾的文件拷贝到 input 目录里面,然后统计这些文件中 符合条件的单词是那些,这些信息保存在 output 目录里面, output 不能事先存在,不然会报错。
执行流程:
[atguigu@hadoop100 hadoop-2.7.2]$
mkdir input
[atguigu@hadoop100 hadoop-2.7.2]$ cp etc/hadoop/*.xml input
[atguigu@hadoop100 hadoop-2.7.2]$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar grep input output 'dfs[a-z.]+'
19/01/27 05:15:36 INFO Configuration.deprecation: session.id is deprecated. Instead, use dfs.metrics.session-id
19/01/27 05:15:36 INFO jvm.JvmMetrics: Initializing JVM Metrics with processName=JobTracker, sessionId=
19/01/27 05:15:36 INFO input.FileInputFormat: Total input paths to process : 8
19/01/27 05:15:36 INFO mapreduce.JobSubmitter: number of splits:8
19/01/27 05:15:36 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_local857720284_0001
19/01/27 05:15:36 INFO mapreduce.Job: The url to track the job: http://localhost:8080/
19/01/27 05:15:36 INFO mapreduce.Job: Running job: job_local857720284_0001
19/01/27 05:15:36 INFO mapred.LocalJobRunner: OutputCommitter set in config null
19/01/27 05:15:36 INFO output.FileOutputCommitter: File Output Committer Algorithm version is 1
19/01/27 05:15:36 INFO mapred.LocalJobRunner: OutputCommitter is org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter
19/01/27 05:15:36 INFO mapred.LocalJobRunner: Waiting for map tasks
19/01/27 05:15:36 INFO mapred.LocalJobRunner: Starting task: attempt_local857720284_0001_m_000000_0
19/01/27 05:15:36 INFO output.FileOutputCommitter: File Output Committer Algorithm version is 1
19/01/27 05:15:36 INFO mapred.Task: Using ResourceCalculatorProcessTree : [ ]
19/01/27 05:15:36 INFO mapred.MapTask: Processing split: file:/opt/module/hadoop-2.7.2/input/hadoop-policy.xml:0+9683
19/01/27 05:15:37 INFO mapred.MapTask: (EQUATOR) 0 kvi 26214396(104857584)
19/01/27 05:15:37 INFO mapred.MapTask: mapreduce.task.io.sort.mb: 100
19/01/27 05:15:37 INFO mapred.MapTask: soft limit at 83886080
19/01/27 05:15:37 INFO mapred.MapTask: bufstart = 0; bufvoid = 104857600
19/01/27 05:15:37 INFO mapred.MapTask: kvstart = 26214396; length = 6553600
19/01/27 05:15:37 INFO mapred.MapTask: Map output collector class = org.apache.hadoop.mapred.MapTask$MapOutputBuffer
19/01/27 05:15:37 INFO mapred.LocalJobRunner:
19/01/27 05:15:37 INFO mapred.MapTask: Starting flush of map output
19/01/27 05:15:37 INFO mapred.MapTask: Spilling map output
19/01/27 05:15:37 INFO mapred.MapTask: bufstart = 0; bufend = 17; bufvoid = 104857600
19/01/27 05:15:37 INFO mapred.MapTask: kvstart = 26214396(104857584); kvend = 26214396(104857584); length = 1/6553600
19/01/27 05:15:37 INFO mapred.MapTask: Finished spill 0
19/01/27 05:15:37 INFO mapred.Task: Task:attempt_local857720284_0001_m_000000_0 is done. And is in the process of committing
19/01/27 05:15:37 INFO mapred.LocalJobRunner: map
19/01/27 05:15:37 INFO mapred.Task: Task 'attempt_local857720284_0001_m_000000_0' done.
19/01/27 05:15:37 INFO mapred.LocalJobRunner: Finishing task: attempt_local857720284_0001_m_000000_0
19/01/27 05:15:37 INFO mapred.LocalJobRunner: Starting task: attempt_local857720284_0001_m_000001_0
19/01/27 05:15:37 INFO output.FileOutputCommitter: File Output Committer Algorithm version is 1
19/01/27 05:15:37 INFO mapred.Task: Using ResourceCalculatorProcessTree : [ ]
19/01/27 05:15:37 INFO mapred.MapTask: Processing split: file:/opt/module/hadoop-2.7.2/input/kms-site.xml:0+5511
19/01/27 05:15:37 INFO mapred.MapTask: (EQUATOR) 0 kvi 26214396(104857584)
19/01/27 05:15:37 INFO mapred.MapTask: mapreduce.task.io.sort.mb: 100
19/01/27 05:15:37 INFO mapred.MapTask: soft limit at 83886080
19/01/27 05:15:37 INFO mapred.MapTask: bufstart = 0; bufvoid = 104857600
19/01/27 05:15:37 INFO mapred.MapTask: kvstart = 26214396; length = 6553600
19/01/27 05:15:37 INFO mapred.MapTask: Map output collector class = org.apache.hadoop.mapred.MapTask$MapOutputBuffer
19/01/27 05:15:37 INFO mapred.LocalJobRunner:
19/01/27 05:15:37 INFO mapred.MapTask: Starting flush of map output
19/01/27 05:15:37 INFO mapred.Task: Task:attempt_local857720284_0001_m_000001_0 is done. And is in the process of committing
19/01/27 05:15:37 INFO mapred.LocalJobRunner: map
19/01/27 05:15:37 INFO mapred.Task: Task 'attempt_local857720284_0001_m_000001_0' done.
19/01/27 05:15:37 INFO mapred.LocalJobRunner: Finishing task: attempt_local857720284_0001_m_000001_0
19/01/27 05:15:37 INFO mapred.LocalJobRunner: Starting task: attempt_local857720284_0001_m_000002_0
19/01/27 05:15:37 INFO output.FileOutputCommitter: File Output Committer Algorithm version is 1
19/01/27 05:15:37 INFO mapred.Task: Using ResourceCalculatorProcessTree : [ ]
19/01/27 05:15:37 INFO mapred.MapTask: Processing split: file:/opt/module/hadoop-2.7.2/input/capacity-scheduler.xml:0+4436
19/01/27 05:15:37 INFO mapred.MapTask: (EQUATOR) 0 kvi 26214396(104857584)
19/01/27 05:15:37 INFO mapred.MapTask: mapreduce.task.io.sort.mb: 100
19/01/27 05:15:37 INFO mapred.MapTask: soft limit at 83886080
19/01/27 05:15:37 INFO mapred.MapTask: bufstart = 0; bufvoid = 104857600
19/01/27 05:15:37 INFO mapred.MapTask: kvstart = 26214396; length = 6553600
19/01/27 05:15:37 INFO mapred.MapTask: Map output collector class = org.apache.hadoop.mapred.MapTask$MapOutputBuffer
19/01/27 05:15:37 INFO mapred.LocalJobRunner:
19/01/27 05:15:37 INFO mapred.MapTask: Starting flush of map output
19/01/27 05:15:37 INFO mapred.Task: Task:attempt_local857720284_0001_m_000002_0 is done. And is in the process of committing
19/01/27 05:15:37 INFO mapred.LocalJobRunner: map
19/01/27 05:15:37 INFO mapred.Task: Task 'attempt_local857720284_0001_m_000002_0' done.
19/01/27 05:15:37 INFO mapred.LocalJobRunner: Finishing task: attempt_local857720284_0001_m_000002_0
19/01/27 05:15:37 INFO mapred.LocalJobRunner: Starting task: attempt_local857720284_0001_m_000003_0
19/01/27 05:15:37 INFO output.FileOutputCommitter: File Output Committer Algorithm version is 1
19/01/27 05:15:37 INFO mapred.Task: Using ResourceCalculatorProcessTree : [ ]
19/01/27 05:15:37 INFO mapred.MapTask: Processing split: file:/opt/module/hadoop-2.7.2/input/kms-acls.xml:0+3518
19/01/27 05:15:37 INFO mapred.MapTask: (EQUATOR) 0 kvi 26214396(104857584)
19/01/27 05:15:37 INFO mapred.MapTask: mapreduce.task.io.sort.mb: 100
19/01/27 05:15:37 INFO mapred.MapTask: soft limit at 83886080
19/01/27 05:15:37 INFO mapred.MapTask: bufstart = 0; bufvoid = 104857600
19/01/27 05:15:37 INFO mapred.MapTask: kvstart = 26214396; length = 6553600
19/01/27 05:15:37 INFO mapred.MapTask: Map output collector class = org.apache.hadoop.mapred.MapTask$MapOutputBuffer
19/01/27 05:15:37 INFO mapred.LocalJobRunner:
19/01/27 05:15:37 INFO mapred.MapTask: Starting flush of map output
19/01/27 05:15:37 INFO mapred.Task: Task:attempt_local857720284_0001_m_000003_0 is done. And is in the process of committing
19/01/27 05:15:37 INFO mapred.LocalJobRunner: map
19/01/27 05:15:37 INFO mapred.Task: Task 'attempt_local857720284_0001_m_000003_0' done.
19/01/27 05:15:37 INFO mapred.LocalJobRunner: Finishing task: attempt_local857720284_0001_m_000003_0
19/01/27 05:15:37 INFO mapred.LocalJobRunner: Starting task: attempt_local857720284_0001_m_000004_0
19/01/27 05:15:37 INFO output.FileOutputCommitter: File Output Committer Algorithm version is 1
19/01/27 05:15:37 INFO mapred.Task: Using ResourceCalculatorProcessTree : [ ]
19/01/27 05:15:37 INFO mapred.MapTask: Processing split: file:/opt/module/hadoop-2.7.2/input/hdfs-site.xml:0+775
19/01/27 05:15:37 INFO mapred.MapTask: (EQUATOR) 0 kvi 26214396(104857584)
19/01/27 05:15:37 INFO mapred.MapTask: mapreduce.task.io.sort.mb: 100
19/01/27 05:15:37 INFO mapred.MapTask: soft limit at 83886080
19/01/27 05:15:37 INFO mapred.MapTask: bufstart = 0; bufvoid = 104857600
19/01/27 05:15:37 INFO mapred.MapTask: kvstart = 26214396; length = 6553600
19/01/27 05:15:37 INFO mapred.MapTask: Map output collector class = org.apache.hadoop.mapred.MapTask$MapOutputBuffer
19/01/27 05:15:37 INFO mapred.LocalJobRunner:
19/01/27 05:15:37 INFO mapred.MapTask: Starting flush of map output
19/01/27 05:15:37 INFO mapred.Task: Task:attempt_local857720284_0001_m_000004_0 is done. And is in the process of committing
19/01/27 05:15:37 INFO mapred.LocalJobRunner: map
19/01/27 05:15:37 INFO mapred.Task: Task 'attempt_local857720284_0001_m_000004_0' done.
19/01/27 05:15:37 INFO mapred.LocalJobRunner: Finishing task: attempt_local857720284_0001_m_000004_0
19/01/27 05:15:37 INFO mapred.LocalJobRunner: Starting task: attempt_local857720284_0001_m_000005_0
19/01/27 05:15:37 INFO output.FileOutputCommitter: File Output Committer Algorithm version is 1
19/01/27 05:15:37 INFO mapred.Task: Using ResourceCalculatorProcessTree : [ ]
19/01/27 05:15:37 INFO mapred.MapTask: Processing split: file:/opt/module/hadoop-2.7.2/input/core-site.xml:0+774
19/01/27 05:15:37 INFO mapred.MapTask: (EQUATOR) 0 kvi 26214396(104857584)
19/01/27 05:15:37 INFO mapred.MapTask: mapreduce.task.io.sort.mb: 100
19/01/27 05:15:37 INFO mapred.MapTask: soft limit at 83886080
19/01/27 05:15:37 INFO mapred.MapTask: bufstart = 0; bufvoid = 104857600
19/01/27 05:15:37 INFO mapred.MapTask: kvstart = 26214396; length = 6553600
19/01/27 05:15:37 INFO mapred.MapTask: Map output collector class = org.apache.hadoop.mapred.MapTask$MapOutputBuffer
19/01/27 05:15:37 INFO mapred.LocalJobRunner:
19/01/27 05:15:37 INFO mapred.MapTask: Starting flush of map output
19/01/27 05:15:37 INFO mapred.Task: Task:attempt_local857720284_0001_m_000005_0 is done. And is in the process of committing
19/01/27 05:15:37 INFO mapred.LocalJobRunner: map
19/01/27 05:15:37 INFO mapred.Task: Task 'attempt_local857720284_0001_m_000005_0' done.
19/01/27 05:15:37 INFO mapred.LocalJobRunner: Finishing task: attempt_local857720284_0001_m_000005_0
19/01/27 05:15:37 INFO mapred.LocalJobRunner: Starting task: attempt_local857720284_0001_m_000006_0
19/01/27 05:15:37 INFO output.FileOutputCommitter: File Output Committer Algorithm version is 1
19/01/27 05:15:37 INFO mapred.Task: Using ResourceCalculatorProcessTree : [ ]
19/01/27 05:15:37 INFO mapred.MapTask: Processing split: file:/opt/module/hadoop-2.7.2/input/yarn-site.xml:0+690
19/01/27 05:15:37 INFO mapred.MapTask: (EQUATOR) 0 kvi 26214396(104857584)
19/01/27 05:15:37 INFO mapred.MapTask: mapreduce.task.io.sort.mb: 100
19/01/27 05:15:37 INFO mapred.MapTask: soft limit at 83886080
19/01/27 05:15:37 INFO mapred.MapTask: bufstart = 0; bufvoid = 104857600
19/01/27 05:15:37 INFO mapred.MapTask: kvstart = 26214396; length = 6553600
19/01/27 05:15:37 INFO mapred.MapTask: Map output collector class = org.apache.hadoop.mapred.MapTask$MapOutputBuffer
19/01/27 05:15:37 INFO mapred.LocalJobRunner:
19/01/27 05:15:37 INFO mapred.MapTask: Starting flush of map output
19/01/27 05:15:37 INFO mapred.Task: Task:attempt_local857720284_0001_m_000006_0 is done. And is in the process of committing
19/01/27 05:15:37 INFO mapred.LocalJobRunner: map
19/01/27 05:15:37 INFO mapred.Task: Task 'attempt_local857720284_0001_m_000006_0' done.
19/01/27 05:15:37 INFO mapred.LocalJobRunner: Finishing task: attempt_local857720284_0001_m_000006_0
19/01/27 05:15:37 INFO mapred.LocalJobRunner: Starting task: attempt_local857720284_0001_m_000007_0
19/01/27 05:15:37 INFO output.FileOutputCommitter: File Output Committer Algorithm version is 1
19/01/27 05:15:37 INFO mapred.Task: Using ResourceCalculatorProcessTree : [ ]
19/01/27 05:15:37 INFO mapred.MapTask: Processing split: file:/opt/module/hadoop-2.7.2/input/httpfs-site.xml:0+620
19/01/27 05:15:37 INFO mapred.MapTask: (EQUATOR) 0 kvi 26214396(104857584)
19/01/27 05:15:37 INFO mapred.MapTask: mapreduce.task.io.sort.mb: 100
19/01/27 05:15:37 INFO mapred.MapTask: soft limit at 83886080
19/01/27 05:15:37 INFO mapred.MapTask: bufstart = 0; bufvoid = 104857600
19/01/27 05:15:37 INFO mapred.MapTask: kvstart = 26214396; length = 6553600
19/01/27 05:15:37 INFO mapred.MapTask: Map output collector class = org.apache.hadoop.mapred.MapTask$MapOutputBuffer
19/01/27 05:15:37 INFO mapred.LocalJobRunner:
19/01/27 05:15:37 INFO mapred.MapTask: Starting flush of map output
19/01/27 05:15:37 INFO mapred.Task: Task:attempt_local857720284_0001_m_000007_0 is done. And is in the process of committing
19/01/27 05:15:37 INFO mapred.LocalJobRunner: map
19/01/27 05:15:37 INFO mapred.Task: Task 'attempt_local857720284_0001_m_000007_0' done.
19/01/27 05:15:37 INFO mapred.LocalJobRunner: Finishing task: attempt_local857720284_0001_m_000007_0
19/01/27 05:15:37 INFO mapred.LocalJobRunner: map task executor complete.
19/01/27 05:15:37 INFO mapred.LocalJobRunner: Waiting for reduce tasks
19/01/27 05:15:37 INFO mapred.LocalJobRunner: Starting task: attempt_local857720284_0001_r_000000_0
19/01/27 05:15:37 INFO output.FileOutputCommitter: File Output Committer Algorithm version is 1
19/01/27 05:15:37 INFO mapred.Task: Using ResourceCalculatorProcessTree : [ ]
19/01/27 05:15:37 INFO mapred.ReduceTask: Using ShuffleConsumerPlugin: org.apache.hadoop.mapreduce.task.reduce.Shuffle@6eedaff1
19/01/27 05:15:37 INFO reduce.MergeManagerImpl: MergerManager: memoryLimit=334338464, maxSingleShuffleLimit=83584616, mergeThreshold=220663392, ioSortFactor=10, memToMemMergeOutputsThreshold=10
19/01/27 05:15:37 INFO reduce.EventFetcher: attempt_local857720284_0001_r_000000_0 Thread started: EventFetcher for fetching Map Completion Events
19/01/27 05:15:37 INFO reduce.LocalFetcher: localfetcher#1 about to shuffle output of map attempt_local857720284_0001_m_000005_0 decomp: 2 len: 6 to MEMORY
19/01/27 05:15:37 INFO reduce.InMemoryMapOutput: Read 2 bytes from map-output for attempt_local857720284_0001_m_000005_0
19/01/27 05:15:37 INFO reduce.MergeManagerImpl: closeInMemoryFile -> map-output of size: 2, inMemoryMapOutputs.size() -> 1, commitMemory -> 0, usedMemory ->2
19/01/27 05:15:37 INFO reduce.LocalFetcher: localfetcher#1 about to shuffle output of map attempt_local857720284_0001_m_000001_0 decomp: 2 len: 6 to MEMORY
19/01/27 05:15:37 INFO reduce.InMemoryMapOutput: Read 2 bytes from map-output for attempt_local857720284_0001_m_000001_0
19/01/27 05:15:37 INFO reduce.MergeManagerImpl: closeInMemoryFile -> map-output of size: 2, inMemoryMapOutputs.size() -> 2, commitMemory -> 2, usedMemory ->4
19/01/27 05:15:37 INFO reduce.LocalFetcher: localfetcher#1 about to shuffle output of map attempt_local857720284_0001_m_000004_0 decomp: 2 len: 6 to MEMORY
19/01/27 05:15:37 INFO reduce.InMemoryMapOutput: Read 2 bytes from map-output for attempt_local857720284_0001_m_000004_0
19/01/27 05:15:37 INFO reduce.MergeManagerImpl: closeInMemoryFile -> map-output of size: 2, inMemoryMapOutputs.size() -> 3, commitMemory -> 4, usedMemory ->6
19/01/27 05:15:37 INFO reduce.LocalFetcher: localfetcher#1 about to shuffle output of map attempt_local857720284_0001_m_000007_0 decomp: 2 len: 6 to MEMORY
19/01/27 05:15:37 INFO reduce.InMemoryMapOutput: Read 2 bytes from map-output for attempt_local857720284_0001_m_000007_0
19/01/27 05:15:37 INFO reduce.MergeManagerImpl: closeInMemoryFile -> map-output of size: 2, inMemoryMapOutputs.size() -> 4, commitMemory -> 6, usedMemory ->8
19/01/27 05:15:37 INFO reduce.LocalFetcher: localfetcher#1 about to shuffle output of map attempt_local857720284_0001_m_000000_0 decomp: 21 len: 25 to MEMORY
19/01/27 05:15:37 INFO reduce.InMemoryMapOutput: Read 21 bytes from map-output for attempt_local857720284_0001_m_000000_0
19/01/27 05:15:37 INFO reduce.MergeManagerImpl: closeInMemoryFile -> map-output of size: 21, inMemoryMapOutputs.size() -> 5, commitMemory -> 8, usedMemory ->29
19/01/27 05:15:37 INFO reduce.LocalFetcher: localfetcher#1 about to shuffle output of map attempt_local857720284_0001_m_000003_0 decomp: 2 len: 6 to MEMORY
19/01/27 05:15:37 INFO reduce.InMemoryMapOutput: Read 2 bytes from map-output for attempt_local857720284_0001_m_000003_0
19/01/27 05:15:37 INFO reduce.MergeManagerImpl: closeInMemoryFile -> map-output of size: 2, inMemoryMapOutputs.size() -> 6, commitMemory -> 29, usedMemory ->31
19/01/27 05:15:37 INFO reduce.LocalFetcher: localfetcher#1 about to shuffle output of map attempt_local857720284_0001_m_000006_0 decomp: 2 len: 6 to MEMORY
19/01/27 05:15:37 WARN io.ReadaheadPool: Failed readahead on ifile
EBADF: Bad file descriptor
at org.apache.hadoop.io.nativeio.NativeIO$POSIX.posix_fadvise(Native Method)
at org.apache.hadoop.io.nativeio.NativeIO$POSIX.posixFadviseIfPossible(NativeIO.java:267)
at org.apache.hadoop.io.nativeio.NativeIO$POSIX$CacheManipulator.posixFadviseIfPossible(NativeIO.java:146)
at org.apache.hadoop.io.ReadaheadPool$ReadaheadRequestImpl.run(ReadaheadPool.java:206)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
19/01/27 05:15:37 INFO reduce.InMemoryMapOutput: Read 2 bytes from map-output for attempt_local857720284_0001_m_000006_0
19/01/27 05:15:37 INFO reduce.MergeManagerImpl: closeInMemoryFile -> map-output of size: 2, inMemoryMapOutputs.size() -> 7, commitMemory -> 31, usedMemory ->33
19/01/27 05:15:37 INFO reduce.LocalFetcher: localfetcher#1 about to shuffle output of map attempt_local857720284_0001_m_000002_0 decomp: 2 len: 6 to MEMORY
19/01/27 05:15:37 INFO reduce.InMemoryMapOutput: Read 2 bytes from map-output for attempt_local857720284_0001_m_000002_0
19/01/27 05:15:37 INFO reduce.MergeManagerImpl: closeInMemoryFile -> map-output of size: 2, inMemoryMapOutputs.size() -> 8, commitMemory -> 33, usedMemory ->35
19/01/27 05:15:37 INFO reduce.EventFetcher: EventFetcher is interrupted.. Returning
19/01/27 05:15:37 INFO mapred.LocalJobRunner: 8 / 8 copied.
19/01/27 05:15:37 INFO reduce.MergeManagerImpl: finalMerge called with 8 in-memory map-outputs and 0 on-disk map-outputs
19/01/27 05:15:37 INFO mapred.Merger: Merging 8 sorted segments
19/01/27 05:15:37 INFO mapred.Merger: Down to the last merge-pass, with 1 segments left of total size: 10 bytes
19/01/27 05:15:37 INFO reduce.MergeManagerImpl: Merged 8 segments, 35 bytes to disk to satisfy reduce memory limit
19/01/27 05:15:37 INFO reduce.MergeManagerImpl: Merging 1 files, 25 bytes from disk
19/01/27 05:15:37 INFO reduce.MergeManagerImpl: Merging 0 segments, 0 bytes from memory into reduce
19/01/27 05:15:37 INFO mapred.Merger: Merging 1 sorted segments
19/01/27 05:15:37 INFO mapred.Merger: Down to the last merge-pass, with 1 segments left of total size: 10 bytes
19/01/27 05:15:37 INFO mapred.LocalJobRunner: 8 / 8 copied.
19/01/27 05:15:37 INFO Configuration.deprecation: mapred.skip.on is deprecated. Instead, use mapreduce.job.skiprecords
19/01/27 05:15:37 INFO mapred.Task: Task:attempt_local857720284_0001_r_000000_0 is done. And is in the process of committing
19/01/27 05:15:37 INFO mapred.LocalJobRunner: 8 / 8 copied.
19/01/27 05:15:37 INFO mapred.Task: Task attempt_local857720284_0001_r_000000_0 is allowed to commit now
19/01/27 05:15:37 INFO output.FileOutputCommitter: Saved output of task 'attempt_local857720284_0001_r_000000_0' to file:/opt/module/hadoop-2.7.2/grep-temp-476836355/_temporary/0/task_local857720284_0001_r_000000
19/01/27 05:15:37 INFO mapred.LocalJobRunner: reduce > reduce
19/01/27 05:15:37 INFO mapred.Task: Task 'attempt_local857720284_0001_r_000000_0' done.
19/01/27 05:15:37 INFO mapred.LocalJobRunner: Finishing task: attempt_local857720284_0001_r_000000_0
19/01/27 05:15:37 INFO mapred.LocalJobRunner: reduce task executor complete.
19/01/27 05:15:37 INFO mapreduce.Job: Job job_local857720284_0001 running in uber mode : false
19/01/27 05:15:37 INFO mapreduce.Job: map 100% reduce 100%
19/01/27 05:15:37 INFO mapreduce.Job: Job job_local857720284_0001 completed successfully
19/01/27 05:15:37 INFO mapreduce.Job: Counters: 30
File System Counters
FILE: Number of bytes read=2693510
FILE: Number of bytes written=5030435
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
Map-Reduce Framework
Map input records=745
Map output records=1
Map output bytes=17
Map output materialized bytes=67
Input split bytes=925
Combine input records=1
Combine output records=1
Reduce input groups=1
Reduce shuffle bytes=67
Reduce input records=1
Reduce output records=1
Spilled Records=2
Shuffled Maps =8
Failed Shuffles=0
Merged Map outputs=8
GC time elapsed (ms)=252
Total committed heap usage (bytes)=2667053056
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=26007
File Output Format Counters
Bytes Written=123
19/01/27 05:15:37 INFO jvm.JvmMetrics: Cannot initialize JVM Metrics with processName=JobTracker, sessionId= - already initialized
19/01/27 05:15:38 INFO input.FileInputFormat: Total input paths to process : 1
19/01/27 05:15:38 INFO mapreduce.JobSubmitter: number of splits:1
19/01/27 05:15:38 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_local326049581_0002
19/01/27 05:15:38 INFO mapreduce.Job: The url to track the job: http://localhost:8080/
19/01/27 05:15:38 INFO mapreduce.Job: Running job: job_local326049581_0002
19/01/27 05:15:38 INFO mapred.LocalJobRunner: OutputCommitter set in config null
19/01/27 05:15:38 INFO output.FileOutputCommitter: File Output Committer Algorithm version is 1
19/01/27 05:15:38 INFO mapred.LocalJobRunner: OutputCommitter is org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter
19/01/27 05:15:38 INFO mapred.LocalJobRunner: Waiting for map tasks
19/01/27 05:15:38 INFO mapred.LocalJobRunner: Starting task: attempt_local326049581_0002_m_000000_0
19/01/27 05:15:38 INFO output.FileOutputCommitter: File Output Committer Algorithm version is 1
19/01/27 05:15:38 INFO mapred.Task: Using ResourceCalculatorProcessTree : [ ]
19/01/27 05:15:38 INFO mapred.MapTask: Processing split: file:/opt/module/hadoop-2.7.2/grep-temp-476836355/part-r-00000:0+111
19/01/27 05:15:38 INFO mapred.MapTask: (EQUATOR) 0 kvi 26214396(104857584)
19/01/27 05:15:38 INFO mapred.MapTask: mapreduce.task.io.sort.mb: 100
19/01/27 05:15:38 INFO mapred.MapTask: soft limit at 83886080
19/01/27 05:15:38 INFO mapred.MapTask: bufstart = 0; bufvoid = 104857600
19/01/27 05:15:38 INFO mapred.MapTask: kvstart = 26214396; length = 6553600
19/01/27 05:15:38 INFO mapred.MapTask: Map output collector class = org.apache.hadoop.mapred.MapTask$MapOutputBuffer
19/01/27 05:15:38 INFO mapred.LocalJobRunner:
19/01/27 05:15:38 INFO mapred.MapTask: Starting flush of map output
19/01/27 05:15:38 INFO mapred.MapTask: Spilling map output
19/01/27 05:15:38 INFO mapred.MapTask: bufstart = 0; bufend = 17; bufvoid = 104857600
19/01/27 05:15:38 INFO mapred.MapTask: kvstart = 26214396(104857584); kvend = 26214396(104857584); length = 1/6553600
19/01/27 05:15:38 INFO mapred.MapTask: Finished spill 0
19/01/27 05:15:38 INFO mapred.Task: Task:attempt_local326049581_0002_m_000000_0 is done. And is in the process of committing
19/01/27 05:15:38 INFO mapred.LocalJobRunner: map
19/01/27 05:15:38 INFO mapred.Task: Task 'attempt_local326049581_0002_m_000000_0' done.
19/01/27 05:15:38 INFO mapred.LocalJobRunner: Finishing task: attempt_local326049581_0002_m_000000_0
19/01/27 05:15:38 INFO mapred.LocalJobRunner: map task executor complete.
19/01/27 05:15:38 INFO mapred.LocalJobRunner: Waiting for reduce tasks
19/01/27 05:15:38 INFO mapred.LocalJobRunner: Starting task: attempt_local326049581_0002_r_000000_0
19/01/27 05:15:38 INFO output.FileOutputCommitter: File Output Committer Algorithm version is 1
19/01/27 05:15:38 INFO mapred.Task: Using ResourceCalculatorProcessTree : [ ]
19/01/27 05:15:38 INFO mapred.ReduceTask: Using ShuffleConsumerPlugin: org.apache.hadoop.mapreduce.task.reduce.Shuffle@67af1c61
19/01/27 05:15:38 INFO reduce.MergeManagerImpl: MergerManager: memoryLimit=334338464, maxSingleShuffleLimit=83584616, mergeThreshold=220663392, ioSortFactor=10, memToMemMergeOutputsThreshold=10
19/01/27 05:15:38 INFO reduce.EventFetcher: attempt_local326049581_0002_r_000000_0 Thread started: EventFetcher for fetching Map Completion Events
19/01/27 05:15:38 INFO reduce.LocalFetcher: localfetcher#2 about to shuffle output of map attempt_local326049581_0002_m_000000_0 decomp: 21 len: 25 to MEMORY
19/01/27 05:15:38 INFO reduce.InMemoryMapOutput: Read 21 bytes from map-output for attempt_local326049581_0002_m_000000_0
19/01/27 05:15:38 INFO reduce.MergeManagerImpl: closeInMemoryFile -> map-output of size: 21, inMemoryMapOutputs.size() -> 1, commitMemory -> 0, usedMemory ->21
19/01/27 05:15:38 INFO reduce.EventFetcher: EventFetcher is interrupted.. Returning
19/01/27 05:15:38 INFO mapred.LocalJobRunner: 1 / 1 copied.
19/01/27 05:15:38 INFO reduce.MergeManagerImpl: finalMerge called with 1 in-memory map-outputs and 0 on-disk map-outputs
19/01/27 05:15:38 INFO mapred.Merger: Merging 1 sorted segments
19/01/27 05:15:38 INFO mapred.Merger: Down to the last merge-pass, with 1 segments left of total size: 11 bytes
19/01/27 05:15:38 INFO reduce.MergeManagerImpl: Merged 1 segments, 21 bytes to disk to satisfy reduce memory limit
19/01/27 05:15:38 INFO reduce.MergeManagerImpl: Merging 1 files, 25 bytes from disk
19/01/27 05:15:38 INFO reduce.MergeManagerImpl: Merging 0 segments, 0 bytes from memory into reduce
19/01/27 05:15:38 INFO mapred.Merger: Merging 1 sorted segments
19/01/27 05:15:38 INFO mapred.Merger: Down to the last merge-pass, with 1 segments left of total size: 11 bytes
19/01/27 05:15:38 INFO mapred.LocalJobRunner: 1 / 1 copied.
19/01/27 05:15:38 INFO mapred.Task: Task:attempt_local326049581_0002_r_000000_0 is done. And is in the process of committing
19/01/27 05:15:38 INFO mapred.LocalJobRunner: 1 / 1 copied.
19/01/27 05:15:38 INFO mapred.Task: Task attempt_local326049581_0002_r_000000_0 is allowed to commit now
19/01/27 05:15:38 INFO output.FileOutputCommitter: Saved output of task 'attempt_local326049581_0002_r_000000_0' to file:/opt/module/hadoop-2.7.2/output/_temporary/0/task_local326049581_0002_r_000000
19/01/27 05:15:38 INFO mapred.LocalJobRunner: reduce > reduce
19/01/27 05:15:38 INFO mapred.Task: Task 'attempt_local326049581_0002_r_000000_0' done.
19/01/27 05:15:38 INFO mapred.LocalJobRunner: Finishing task: attempt_local326049581_0002_r_000000_0
19/01/27 05:15:38 INFO mapred.LocalJobRunner: reduce task executor complete.
19/01/27 05:15:39 INFO mapreduce.Job: Job job_local326049581_0002 running in uber mode : false
19/01/27 05:15:39 INFO mapreduce.Job: map 100% reduce 100%
19/01/27 05:15:39 INFO mapreduce.Job: Job job_local326049581_0002 completed successfully
19/01/27 05:15:39 INFO mapreduce.Job: Counters: 30
File System Counters
FILE: Number of bytes read=1159582
FILE: Number of bytes written=2231696
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
Map-Reduce Framework
Map input records=1
Map output records=1
Map output bytes=17
Map output materialized bytes=25
Input split bytes=127
Combine input records=0
Combine output records=0
Reduce input groups=1
Reduce shuffle bytes=25
Reduce input records=1
Reduce output records=1
Spilled Records=2
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=0
Total committed heap usage (bytes)=658505728
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=123
File Output Format Counters
Bytes Written=23
[atguigu@hadoop100 hadoop-2.7.2]$ cat output/*
1 dfsadmin
[atguigu@hadoop100 hadoop-2.7.2]$
通过结果可得到 input 目录中的文件满足条件的就只有一个单词 dfsadmin。
把正则的 dfs 改为 kms:
[atguigu@hadoop100 hadoop-2.7.2]$ rm -rf output/
[atguigu@hadoop100 hadoop-2.7.2]$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar grep input output 'kms[a-z.]+'
19/01/27 05:20:07 INFO Configuration.deprecation: session.id is deprecated. Instead, use dfs.metrics.session-id
...
...
...
Bytes Read=1057
File Output Format Counters
Bytes Written=715
[atguigu@hadoop100 hadoop-2.7.2]$ cat output/*
9 kms.acl.
2 kms.keytab
1 kms.key.provider.uri
1 kms.current.key.cache.timeout.ms
1 kms.cache.timeout.ms
1 kms.cache.enable
1 kms.authentication.type
1 kms.authentication.signer.secret.provider.zookeeper.path
1 kms.authentication.signer.secret.provider.zookeeper.kerberos.principal
1 kms.keystore
1 kms.authentication.signer.secret.provider.zookeeper.connection.string
1 kms.authentication.signer.secret.provider.zookeeper.auth.type
1 kms.authentication.signer.secret.provider
1 kms.authentication.kerberos.principal
1 kms.authentication.kerberos.name.rules
1 kms.authentication.kerberos.keytab
1 kms.audit.aggregation.window.ms
1 kms.authentication.signer.secret.provider.zookeeper.kerberos.keytab
[atguigu@hadoop100 hadoop-2.7.2]$
b) 官方WordCount案例
通过单词意思就知道是统计单词的个数,这个案例很经典很实用,面试经常问。
准备工作:
1. 创建在hadoop-2.7.2文件下面创建一个wcinput文件夹
[atguigu@hadoop100 hadoop-2.7.2]$ mkdir wcinput
2. 在wcinput文件下创建一个wc.input文件
[atguigu@hadoop100 hadoop-2.7.2]$ cd wcinput
[atguigu@hadoop100 wcinput]$ touch wc.input
3.编辑wc.input文件
[atguigu@hadoop100 wcinput]$ vi wc.input
在文件中输入如下内容
hadoop yarn
hadoop mapreduce
atguigu
atguigu
保存退出::wq
4. 回到Hadoop目录/opt/module/hadoop-2.7.2
下面我们就可以运行官方给我们提供的 WordCount 案例:
5. 执行程序
[atguigu@hadoop100 hadoop-2.7.2]$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount wcinput wcoutput
6. 查看结果
[atguigu@hadoop100 hadoop-2.7.2]$ cat wcoutput/part-r-00000
atguigu 2
hadoop 2
mapreduce 1
yarn 1
hadoop jar share/hadoop/mapreduce/mkdir wcinput
[atguigu@hadoop100 hadoop-2.7.2]$ cd wcinput
[atguigu@hadoop100 wcinput]$ touch wc.input
[atguigu@hadoop100 wcinput]$ vi wc.input
[atguigu@hadoop100 wcinput]$ cd ..
[atguigu@hadoop100 hadoop-2.7.2]$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount wcinput wcoutput
19/01/27 05:48:06 INFO Configuration.deprecation: session.id is deprecated. Instead, use
..........................
Bytes Written=50
[atguigu@hadoop100 hadoop-2.7.2]$ cat wcoutput/*
atguigu 2
hadoop 2
mapreduce 1
yarn 1
[atguigu@hadoop100 hadoop-2.7.2]$
2、伪分布式运行模式
2.1、启动HDFS并运行MapReduce程序
步骤:
a)分析
(1)配置集群
(2)启动、测试集群增、删、查
(3)执行WordCount案例
b)执行步骤
(1)配置集群
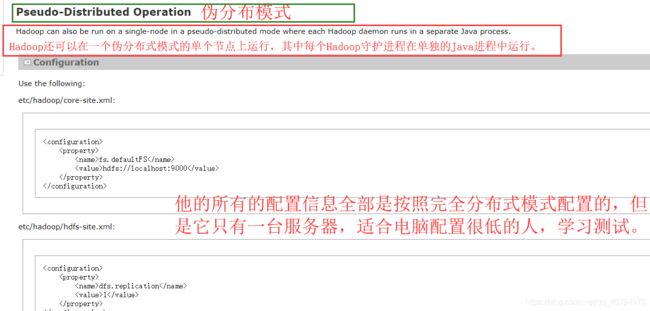
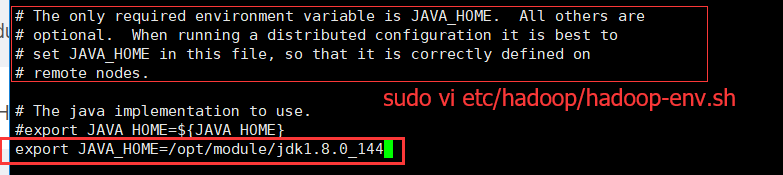
(a)配置:hadoop-env.sh sudo vi etc/hadoop/hadoop-env.sh (注意这里的etc 是Hadoop里面的,不是Linux 里面的 etc)
Linux系统中获取JDK的安装路径:
[atguigu@ hadoop100 ~]# echo $JAVA_HOME
/opt/module/jdk1.8.0_144
修改JAVA_HOME 路径:vi /etc/profile
export JAVA_HOME=/opt/module/jdk1.8.0_144
![]()
(b)配置:core-site.xml vi etc/hadoop/core-site.xml
fs.defaultFS
hdfs://hadoop101:9000
hadoop.tmp.dir
/opt/module/hadoop-2.7.2/data/tmp
!!!!!!!!!!!!!!!!:配置了这个,在去执行上面的本地模式,本地模式不可以用了,默认是本地模式,现在改了。

![]()
如果不指定Hadoop运行时产生文件的存储目录,他默认的目录是 /tmp/hadoop-用户名 (自动创建),在系统的根目录。配置的目录无需提前创建系统自动创建。
vi etc/hadoop/core-site.xml
[atguigu@hadoop100 hadoop-2.7.2]$ sudo vi etc/hadoop/core-site.xml
[sudo] password for atguigu:
[atguigu@hadoop100 hadoop-2.7.2]$
(c)配置:hdfs-site.xml sudo vi etc/hadoop/hdfs-site.xml (这个配不配置都行)
dfs.replication
1
注:默认个数是3个,也就是在3台机器上存储了同一份数据,任何一个存储数据的节点挂掉,那么还有两份,同时它会在其他服务器上增加一份节点副本,始终保持集群上的副本数是3,副本数的多少取决于集群机器的质量。
如果只有一台机器就算默认的是3个,也只有一个备份,你后面增加它就会给你备份。

(2)启动集群
(a)格式化NameNode(第一次启动时格式化,以后就不要总格式化)
[atguigu@hadoop100 hadoop-2.7.2]$ bin/hdfs namenode -format
注意:格式化需要把 Hadoop 里面的数据删除掉(所以说第一次是没有问题,后面就可能有问题)。
(b)启动NameNode
[atguigu@hadoop100 hadoop-2.7.2]$ sbin/hadoop-daemon.sh start namenode
(c)启动DataNode
[atguigu@hadoop100 hadoop-2.7.2]$ sbin/hadoop-daemon.sh start datanode

(3)查看集群
(a)查看是否启动成功
[atguigu@hadoop100 hadoop-2.7.2]$ jps
5302 DataNode
5495 Jps
5449 NameNode
注意:jps是JDK中的命令,不是Linux命令。不安装JDK不能使用jps
(b)web端查看HDFS文件系统 http://hadoop100:50070/dfshealth.html#tab-overview

注意:hadoop100 需要实现在 Windows 或者 Linux 系统里面配置好 (C:\Windows\System32\drivers\etc\hosts),取决于你的游览器是在拿个系统里面。


如果不能查看,看如下帖子处理 https://blog.csdn.net/qq_40794973/article/details/86663969
在 sdfs 的根目录下创建多级目录
[atguigu@hadoop100 hadoop-2.7.2]$ bin/hdfs dfs -mkdir -p /usr/atguigu/input
[atguigu@hadoop100 hadoop-2.7.2]$
dfs 用来定义路径的
bin/hdfs dfs 后面跟要执行的命令
[atguigu@hadoop100 hadoop-2.7.2]$ bin/hdfs dfs -ls /
Found 1 items
drwxr-xr-x - atguigu supergroup 0 2019-01-27 19:00 /usr
[atguigu@hadoop100 hadoop-2.7.2]$ bin/hdfs dfs -lsr /
lsr: DEPRECATED: Please use 'ls -R' instead.
drwxr-xr-x - atguigu supergroup 0 2019-01-27 19:00 /usr
drwxr-xr-x - atguigu supergroup 0 2019-01-27 19:00 /usr/atguigu
drwxr-xr-x - atguigu supergroup 0 2019-01-27 19:00 /usr/atguigu/input
[atguigu@hadoop100 hadoop-2.7.2]$

把本地的文件上传到 hdfs上面,上传到刚刚创建的多级目录 input 里面 bin/hdfs dfs -put wcinput/wc.input /usr/atguigu/input
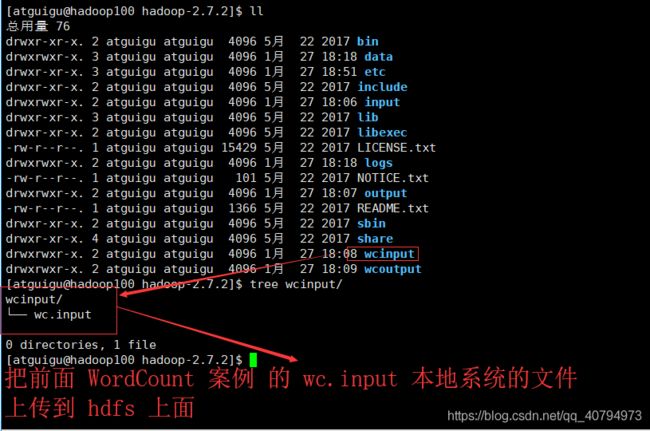


在 hdfs 上面跑一个 WordCount 案例 (输入文件上面已经上传到了 /usr/atguigu/input 目录里面)
[atguigu@hadoop100 hadoop-2.7.2]$ jps
3269 DataNode
3205 NameNode
4622 Jps
[atguigu@hadoop100 hadoop-2.7.2]$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount /usr/atguigu/input/wc.input /usr/atguigu/output
成功
(c)查看产生的Log日志
说明:在企业中遇到Bug时,经常根据日志提示信息去分析问题、解决Bug。
当前目录:/opt/module/hadoop-2.7.2/logs
[atguigu@hadoop100 logs]$ ls
hadoop-atguigu-datanode-hadoop100.log hadoop-atguigu-namenode-hadoop100.out
hadoop-atguigu-datanode-hadoop100.out SecurityAuth-atguigu.audit
hadoop-atguigu-namenode-hadoop100.log
[atguigu@hadoop100 logs]$ cat hadoop-atguigu-datanode-hadoop100.log
(d)思考:为什么不能一直格式化NameNode,格式化NameNode,要注意什么?
[atguigu@hadoop100 hadoop-2.7.2]$ cat data/tmp/dfs/name/current/VERSION
#Sun Jan 27 18:18:10 CST 2019
namespaceID=64968429
clusterID=CID-a4ad884d-998c-47df-b315-ae4e0a8e874d
cTime=0
storageType=NAME_NODE
blockpoolID=BP-244670385-192.168.19.100-1548584290557
layoutVersion=-63
[atguigu@hadoop100 hadoop-2.7.2]$ cat data/tmp/dfs/data/current/VERSION
#Sun Jan 27 18:18:34 CST 2019
storageID=DS-fdc0a442-60e5-42ea-98b8-a0b90a5954ac
clusterID=CID-a4ad884d-998c-47df-b315-ae4e0a8e874d
cTime=0
datanodeUuid=022f01d6-9a59-4fe5-8e9a-a86251f0afcd
storageType=DATA_NODE
layoutVersion=-56
[atguigu@hadoop100 hadoop-2.7.2]$
[atguigu@hadoop100 hadoop-2.7.2]$ cd data/tmp/dfs/
[atguigu@hadoop100 dfs]$ tree
.
├── data
│ ├── current
│ │ ├── BP-244670385-192.168.19.100-1548584290557
│ │ │ ├── current
│ │ │ │ ├── finalized
│ │ │ │ │ └── subdir0
│ │ │ │ │ └── subdir0
│ │ │ │ │ ├── blk_1073741825
│ │ │ │ │ ├── blk_1073741825_1001.meta
│ │ │ │ │ ├── blk_1073741826
│ │ │ │ │ └── blk_1073741826_1002.meta
│ │ │ │ ├── rbw
│ │ │ │ └── VERSION
│ │ │ ├── scanner.cursor
│ │ │ └── tmp
│ │ └── VERSION
│ └── in_use.lock
└── name
├── current
│ ├── edits_inprogress_0000000000000000001
│ ├── fsimage_0000000000000000000
│ ├── fsimage_0000000000000000000.md5
│ ├── seen_txid
│ └── VERSION
└── in_use.lock
11 directories, 14 files
注意:格式化NameNode,会产生新的集群id,导致NameNode和DataNode的集群id不一致,集群找不到已往数据。所以,格式NameNode时,一定要先删除data数据和log日志,然后再格式化NameNode。
(4)操作集群
(a)在HDFS文件系统上创建一个input文件夹
[atguigu@hadoop100 hadoop-2.7.2]$ bin/hdfs dfs -mkdir -p /user/atguigu/input
(b)将测试文件内容上传到文件系统上
[atguigu@hadoop100 hadoop-2.7.2]$bin/hdfs dfs -put wcinput/wc.input /user/atguigu/input/
(c)查看上传的文件是否正确
[atguigu@hadoop100 hadoop-2.7.2]$ bin/hdfs dfs -ls /user/atguigu/input/
[atguigu@hadoop100 hadoop-2.7.2]$ bin/hdfs dfs -cat /user/atguigu/ input/wc.input
(d)运行MapReduce程序
[atguigu@hadoop100 hadoop-2.7.2]$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount /user/atguigu/input/ /user/atguigu/output
(e)查看输出结果
命令行查看:
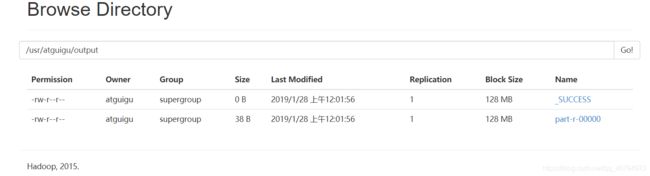
[atguigu@hadoop100 hadoop-2.7.2]$ bin/hdfs dfs -cat /user/atguigu/output/*
浏览器查看output文件,如图2-34所示

(f)将测试文件内容下载到本地
[atguigu@hadoop100 hadoop-2.7.2]$hdfs dfs -get /user/atguigu/output/part-r-00000 ./wcoutput/
(g)删除输出结果
[atguigu@hadoop100 hadoop-2.7.2]$ hdfs dfs -rm -r /user/atguigu/output
2.2、启动YARN并运行MapReduce程序
a)分析
(1)配置集群在YARN上运行MR
(2)启动、测试集群增、删、查
(3)在YARN上执行WordCount案例
b) 执行步骤
(1)配置集群
(a)配置 yarn-env.sh vi etc/hadoop/yarn-env.sh 配置一下JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_144

(b)配置 yarn-site.xml vi etc/hadoop/yarn-site.xml
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.resourcemanager.hostname
hadoop100
(c)配置:mapred-env.sh vi etc/hadoop/mapred-env.sh 配置一下JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_144

(d)配置: (对mapred-site.xml.template重新命名为) mapred-site.xml
[atguigu@hadoop100 hadoop-2.7.2]$ cd etc/hadoop
[atguigu@hadoop100 hadoop]$ mv mapred-site.xml.template mapred-site.xml
[atguigu@hadoop100 hadoop]$ vi mapred-site.xml
mapreduce.framework.name
yarn

注:默认是本地运行。
(2)启动集群
(a)启动前必须保证 NameNode 和 DataNode 已经启动
[atguigu@hadoop100 hadoop-2.7.2]$ jps
3269 DataNode
3205 NameNode
5948 Jps
(b)启动ResourceManager
[atguigu@hadoop100 hadoop-2.7.2]$ sbin/yarn-daemon.sh start resourcemanager
(c)启动NodeManager
[atguigu@hadoop100 hadoop-2.7.2]$ sbin/yarn-daemon.sh start nodemanager
[atguigu@hadoop100 hadoop-2.7.2]$ jps
3269 DataNode
3205 NameNode
5991 ResourceManager
6348 Jps
6271 NodeManager
(3)集群操作
(a)YARN的浏览器页面查看,如下图所示 http://hadoop100:8088/cluster

(b)删除文件系统上的output文件
[atguigu@hadoop100 hadoop-2.7.2]$ bin/hdfs dfs -rm -r /user/atguigu/output
(c)执行MapReduce程序
[atguigu@hadoop100 hadoop-2.7.2]$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount /user/atguigu/input /user/atguigu/output
(d)查看运行结果
[atguigu@hadoop100 hadoop-2.7.2]$ bin/hdfs dfs -cat /user/atguigu/output/*

2.3、配置历史服务器
为了查看程序的历史运行情况,需要配置一下历史服务器。具体配置步骤如下:
(1)、配置 mapred-site.xml
[atguigu@hadoop100 hadoop-2.7.2]$ cd etc/hadoop/
[atguigu@hadoop100 hadoop]$ vi mapred-site.xml
在该文件里面增加如下配置:
mapreduce.jobhistory.address
hadoop100:10020
mapreduce.jobhistory.webapp.address
hadoop100:19888
(2)、 启动历史服务器
[atguigu@hadoop100 hadoop]$ cd ../..
[atguigu@hadoop100 hadoop-2.7.2]$ sbin/mr-jobhistory-daemon.sh start historyserver
(3)、 查看历史服务器是否启动
[atguigu@hadoop100 hadoop-2.7.2]$ jps
7076 Jps
3269 DataNode
3205 NameNode
5991 ResourceManager
7033 JobHistoryServer
6271 NodeManager
(4)、查看JobHistory http://hadoop100:19888/jobhistory
2.4、配置日志的聚集
日志聚集概念:应用运行完成以后,将程序运行日志信息上传到HDFS系统上。
日志聚集功能好处:可以方便的查看到程序运行详情,方便开发调试。
注意:开启日志聚集功能,需要重新启动NodeManager 、ResourceManager和HistoryManager。
开启日志聚集功能具体步骤如下:
(1)、配置 yarn-site.xml
[atguigu@hadoop100 hadoop-2.7.2]$ cd etc/hadoop/
[atguigu@hadoop100 hadoop]$ vi yarn-site.xml
在该文件里面增加如下配置:
yarn.log-aggregation-enable
true
yarn.log-aggregation.retain-seconds
604800

(2)、关闭NodeManager 、ResourceManager和HistoryManager
[atguigu@hadoop100 hadoop]$ cd ../..
[atguigu@hadoop100 hadoop-2.7.2]$ sbin/yarn-daemon.sh stop resourcemanager
[atguigu@hadoop100 hadoop-2.7.2]$ sbin/yarn-daemon.sh stop nodemanager
[atguigu@hadoop100 hadoop-2.7.2]$ sbin/mr-jobhistory-daemon.sh stop historyserver


(3)、启动NodeManager 、ResourceManager和HistoryManager
[atguigu@hadoop100 hadoop-2.7.2]$ sbin/yarn-daemon.sh start resourcemanager
[atguigu@hadoop100 hadoop-2.7.2]$ sbin/yarn-daemon.sh start nodemanager
[atguigu@hadoop100 hadoop-2.7.2]$ sbin/mr-jobhistory-daemon.sh start historyserver
[atguigu@hadoop100 hadoop-2.7.2]$ jps
8389 Jps
3269 DataNode
3205 NameNode
7401 ResourceManager
7801 JobHistoryServer
7674 NodeManager
(4)、删除HDFS上已经存在的输出文件
[atguigu@hadoop101 hadoop-2.7.2]$ bin/hdfs dfs -rm -r /user/atguigu/output
(5)、执行WordCount程序
[atguigu@hadoop101 hadoop-2.7.2]$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount /user/atguigu/input /user/atguigu/output
(6)、查看日志 http://hadoop100:19888/jobhistory



2.5、配置文件说明
Hadoop配置文件分两类:默认配置文件和自定义配置文件,只有用户想修改某一默认配置值时,才需要修改自定义配置文件,更改相应属性值。
(1)默认配置文件:
| 要获取的默认文件 |
文件存放在Hadoop的jar包中的位置 |
| [core-default.xml] |
hadoop-common-2.7.2.jar/ core-default.xml |
| [hdfs-default.xml] |
hadoop-hdfs-2.7.2.jar/ hdfs-default.xml |
| [yarn-default.xml] |
hadoop-yarn-common-2.7.2.jar/ yarn-default.xml |
| [mapred-default.xml] |
hadoop-mapreduce-client-core-2.7.2.jar/ mapred-default.xml |
(2)自定义配置文件:
core-site.xml、hdfs-site.xml、yarn-site.xml、mapred-site.xml四个配置文件存放在$HADOOP_HOME/etc/hadoop这个路径上,用户可以根据项目需求重新进行修改配置。