深度学习之----循环神经网络(RNN) 基础
目录
1.RNN的背景
设计RNNs的目的,就是处理序列数据。
2.RNN的价值
3. RNN的基本结构
4. RNN的高级形式
4.1 双向RNN (Bidirectional RNN )
4.2 LSTM(Long Short-term Memory)
4.3 GRU(Gated Recurrent Unit)
5. RNN的训练
5.1 普通的RNN(simple RNN)不好训练
5.2 LSTM,让RNN的训练更简单
1.RNN的背景
设计RNNs的目的,就是处理序列数据。
在传统的神经网络模型中,是从输入层到隐含层再到输出层,层与层之间是全连接的,每层之间的节点是无连接的。但是这种普通的神经网络对于很多问题却无能无力。例如,你要预测句子的下一个单词是什么,一般需要用到前面的单词,因为一个句子中前后单词并不是独立的。RNNs之所以称为循环神经网路,即一个序列当前的输出与前面的输出也有关。具体的表现形式为网络会对前面的信息进行记忆并应用于当前输出的计算中,即隐藏层之间的节点不再无连接而是有连接的,并且隐藏层的输入不仅包括输入层的输出还包括上一时刻隐藏层的输出。理论上,RNNs能够对任何长度的序列数据进行处理。
RNN was born in 1980s!
词序其实是很重要的

中文中,这样的例子也很多。“怎么样投资白银”vs“白银投资怎么样”;“北京到上海的机票”vs“上海到北京的机票”。
2.RNN的价值
我们知道,一个三层的前馈神经网络可以学到任何的函数,而RNN则是“turing-complete”的,它可以逼近任何算法。
RNN can approximate any algorithm
a recurrent neural network RNN is Turing complete and so can compute anything that can be computed.
RNN具有强大的计算和建模能力,因而只要合理建模,它就可以模拟任何计算过程。
RNN具有记忆能力。给RNN同样的输入,得到的输出可能是不一样的。
3. RNN的基本结构
RNNs包含输入单元(Input units),输入集标记为{x0,x1,...,xt,xt+1,...},而输出单元(Output units)的输出集则被标记为{y0,y1,...,yt,yt+1.,..}。RNNs还包含隐藏单元(Hidden units),我们将其输出集标记为{h0,h1,...,ht,ht+1,...},这些隐藏单元完成了最为主要的工作。

各个变量的含义:
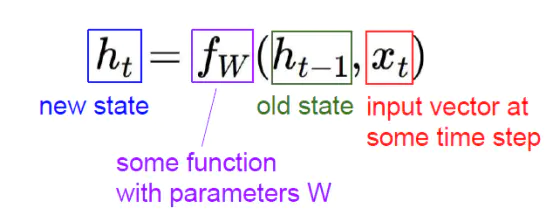
展开以后形式:

一个RNN的小例子:

把RNN做深(deep)

字符级别RNN

char-rnn的代码
Torch版本
https://github.com/karpathy/char-rnn
Tensorflow版本
https://github.com/sherjilozair/char-rnn-tensorflow
4. RNN的高级形式
4.1 双向RNN (Bidirectional RNN )
RNN既然能继承历史信息,是不是也能吸收点未来的信息呢?因为在序列信号分析中,如果我能预知未来,对识别一定也是有所帮助的。因此就有了双向RNN、双向LSTM,同时利用历史和未来的信息。

双向RNN
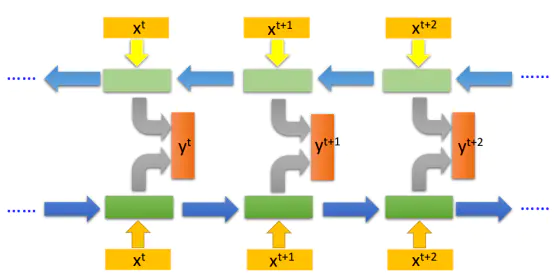
值得一提的是,但由于RNN 建模中的遗忘性,最后一个 state 中包含的信息是有损的,且序列越靠前的信息损失可能越严重。一种比较可行的解决方法是同时训练两个RNN,一个正向学习,一个反向学习,将正向的和反向的最后一个state 对应向量 concate 后得到的向量作为最终产物。

对于正向RNN最后一个向量中记录的信息量从前往后依次增强,反向的最后一个state记录的信息从后往前依次增强,两者组合正好记录了比较完整的信息
4.2 LSTM(Long Short-term Memory)
名字很有意思,又长又短的记忆?其实不是,注意“Short-term”中间有一个“—”连接。代表LSTM本质上还是短期记忆(short-term memory),只是它是比较长一点的short-term memory。
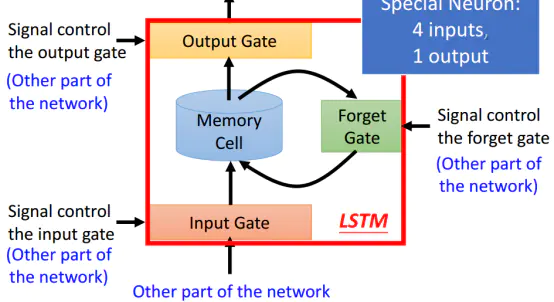
由于LSTM有四个参数做输入,LSTM需要的参数量是一般的神经网络模型的4倍。
台湾大学李宏毅讲的LSTM的小例子,非常清晰。
https://www.youtube.com/watch?v=xCGidAeyS4M
LSTM在1997年由“Hochreiter & Schmidhuber”提出,目前已经成为RNN中的标准形式。
4.3 GRU(Gated Recurrent Unit)
LSTM的一个稍微简化一点的版本。只有两个gate,据说效果和LSTM差不多,但是参数少了1/3,不容易过拟合。
如果发现LSTM训练出来的模型过拟合比较严重,可以试试GRU
LSTM vs GRU

5. RNN的训练
5.1 普通的RNN(simple RNN)不好训练
相较于CNN,RNN训练过程较不稳定,训练难度和计算量都大得多。当然,RNN用GPU加速效果会比较明显。

RNN不好训练的原因

weight被高频地使用,0.99的1000次方和1.01的1000次方有本质的区别。导致RNN的误差面(error surface)常常要么是很平坦要么是很陡峭(The error surface is either very flat or very steep)。

5.2 LSTM,让RNN的训练更简单
1997年,LSTM的提出就是为了解决RNN的梯度弥散的问题(gradient vanish)。那么LSTM比普通的RNN好在哪呢?LSTM为什么能够解决gradient vanish的问题?
LSTM如何避免梯度消失:


参考文章:
[1] https://www.jianshu.com/p/9f155515bdf0
[2] https://www.atyun.com/30234.html