模拟登录
学爬虫,总能听到模拟登录这四个字,究竟什么是模拟登录?通俗一点讲,模拟登录就是程序用账号和密码自动登录一个网站。然后,拿到只有登录后,才能下载的网站数据。
比如,我们只有登录淘宝账号之后,才能看到购物车里有哪些东西。本文,就以模拟登录淘宝为例进行讲解,并帮他/她清空购物车。
很多人学习python,不知道从何学起。
很多人学习python,掌握了基本语法过后,不知道在哪里寻找案例上手。
很多已经做案例的人,却不知道如何去学习更加高深的知识。
那么针对这三类人,我给大家提供一个好的学习平台,免费领取视频教程,电子书籍,以及课程的源代码!
QQ群:101677771
你只需要知道他/她的淘宝账号和密码,并且有个充足的钱包,就可以运行程序,扫码支付一气呵成。
体验自动结算,钱包秒空的快感!
Selenium
模拟登录无非两种方法:请求包分析模拟登录、自动化测试工具模拟登录。
前者,需要抓包分析请求,解析各种参数,还可能涉及一些加密算法。
后者,可以绕过一些繁琐的分析过程,直接定位元素进行操作,但也会遇到一些反爬策略。
两者,都有各自的操作技巧。
本文讲解一个新思路,使用自动化测试工具 Selenium 模拟登录。
Selenium 基本的使用方法,以及如何破解淘宝对于 Selenium 的反爬策略,尽在下文。
Selenium 安装
Selenium 是一个自动化测试工具,支持各种主流浏览器,例如 Chrome、Safari、Firefox 等。
不知道什么是自动化测试工具没关系,我会通过实战操作,慢慢讲解。
不管怎样,先安装 Selenium 再说。
pip install selenium
使用 pip 直接安装 selenium。
除了安装 Python 的 Selenium 第三方库,还需要根据浏览器配置相应的浏览器驱动。
以 Chrome 为例,下载浏览器驱动。
https://sites.google.com/a/chromium.org/chromedriver/downloads
需要根据浏览器的版本,选择驱动下载。
小试牛刀
使用 Selenium 登录百度看一下。
from selenium import webdriver
if __name__ == "__main__":
browser = webdriver.Chrome()
browser.get('https://www.baidu.com/')
结果如下图所示:![]()
程序会自动打开 Chrome 浏览器,并打开 www.baidu.com。
再来个复杂一些的例子。
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
if __name__ == "__main__":
driver = webdriver.Chrome()
driver.get("https://www.python.org")
assert "Python" in driver.title
elem = driver.find_element_by_name("q")
elem.send_keys("pycon")
elem.send_keys(Keys.RETURN)
print(driver.page_source)
打开 www.python.org 官网,并根据 name 属性为 q 找到搜索框,并输入 pycon 并点击搜索。
写好程序,浏览器自动操作,是不是很简单,很酷炫?
这就是自动化测试工具,程序写好,浏览器自动执行你的写的操作。
find_element_by_* 是一种定位网页元素的方法,有很多方式:
find_element_by_id
find_element_by_name
find_element_by_xpath
find_element_by_link_text
find_element_by_partial_link_text
find_element_by_tag_name
find_element_by_class_name
find_element_by_css_selector
可以通过,标签的 id 属性、name 属性、class_name 属性查找元素,也可以通过 xpath 等。
这里面,其实用到最多的就是 xpath,因为好用。
不用动脑思考怎么写xpath,就能操作,方便好用。举个例子,比如我想找到 baidu.com 的搜索框的元素:
在搜索框位置,点击右键,选择 copy 下的 copy xpath,直接复制 xpath 。
粘贴出来你会看到如下内容:
//*[@id="kw"]
其实意思就是从根目录开始找,找到 id 属性为 kw 的标签。
详细的,关于 Selenium 的 API 文档,可以看官方手册。
官方手册:
https://selenium-python.readthedocs.io/index.html
好了,基础知识准备完毕。
只要你会使用 copy xpath,基本的 Selenium 操作,就可以开始跟我一起「模拟登录」淘宝。
登陆淘宝,掏空钱包
这场为了爱情的清空购物车大作战,需要分两步完成:
-
模拟登录淘宝
-
购物车结算
模拟登录淘宝
用 Selenium 模拟登录,就边看边写,按照人的操作步骤写代码即可。
打开淘宝,上来第一步肯定是点击登录按钮,不会写 XPath,那就复制这个标签的 XPath。
因此点击登录的代码就是:
browser.find_element_by_xpath('//*[@id="J_SiteNavLogin"]/div[1]/div[1]/a[1]').click()
找到登录元素位置,然后 click() 点击。
点击登录后,进入登陆页面,找到账号框和密码框位置,并输入账号和密码。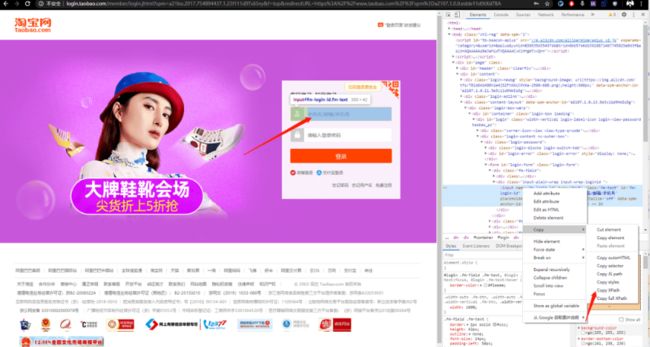
![]() 还是简单粗暴的复制粘贴 XPath 即可。
还是简单粗暴的复制粘贴 XPath 即可。
browser.find_element_by_xpath('//*[@id="fm-login-id"]').send_keys(username)
browser.find_element_by_xpath('//*[@id="fm-login-password"]').send_keys(password)
username 和 password 就是你要输入的账号和密码。
输入完密码之后,可能会出现一个验证码滑动窗口。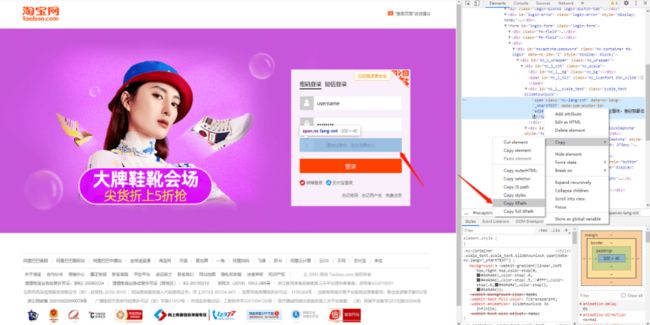
![]()
这种滑动窗口也好解决,还是复制 XPath 匹配元素,然后使用 Selenium 的 ActionChains 方法,拖动滑块。
最后点击登陆按钮。
登陆后,再读取下用户名,看下是否登陆成功即可。
分析完毕,直接上代码。
from selenium import webdriver
import logging
import time
from selenium.common.exceptions import NoSuchElementException, WebDriverException
from retrying import retry
from selenium.webdriver import ActionChains
logging.basicConfig(level = logging.INFO,format = '%(asctime)s - %(name)s - %(levelname)s - %(message)s')
logger = logging.getLogger(__name__)
class taobao():
def __init__(self):
self.browser = webdriver.Chrome("path\to\your\chromedriver.exe")
# 最大化窗口
self.browser.maximize_window()
self.browser.implicitly_wait(5)
self.domain = 'http://www.taobao.com'
self.action_chains = ActionChains(self.browser)
def login(self, username, password):
while True:
self.browser.get(self.domain)
time.sleep(1)
#会xpath可以简化这几步
#self.browser.find_element_by_class_name('h').click()
#self.browser.find_element_by_id('fm-login-id').send_keys(username)
#self.browser.find_element_by_id('fm-login-password').send_keys(password)
self.browser.find_element_by_xpath('//*[@id="J_SiteNavLogin"]/div[1]/div[1]/a[1]').click()
self.browser.find_element_by_xpath('//*[@id="fm-login-id"]').send_keys(username)
self.browser.find_element_by_xpath('//*[@id="fm-login-password"]').send_keys(password)
time.sleep(1)
try:
# 出现验证码,滑动验证
slider = self.browser.find_element_by_xpath("//span[contains(@class, 'btn_slide')]")
if slider.is_displayed():
# 拖拽滑块
self.action_chains.drag_and_drop_by_offset(slider, 258, 0).perform()
time.sleep(0.5)
# 释放滑块,相当于点击拖拽之后的释放鼠标
self.action_chains.release().perform()
except (NoSuchElementException, WebDriverException):
logger.info('未出现登录验证码')
#会xpath可以简化点击登陆按钮
#self.browser.find_element_by_class_name('password-login').click()
self.browser.find_element_by_xpath('//*[@id="login-form"]/div[4]/button').click()
nickname = self.get_nickname()
if nickname:
logger.info('登录成功,呢称为:' + nickname)
break
logger.debug('登录出错,5s后继续登录')
time.sleep(5)
def get_nickname(self):
self.browser.get(self.domain)
time.sleep(0.5)
try:
return self.browser.find_element_by_class_name('site-nav-user').text
except NoSuchElementException:
return ''
if __name__ == '__main__':
# 填入自己的用户名,密码
username = 'username'
password = 'password'
tb = taobao()
tb.login(username, password)
代码加了一些异常处理,以及 log 信息的打印。这里需要注意的是,滑块不是每次都出,所以要加个判断。
输入你的账号和密码,指定 Chrome 驱动路径,运行代码,看看能否如我们所愿的登陆成功。
通过验证,可以看到,账号密码,都输入了,验证码也通过。
但是,就是登陆不上!这是为什么呢?
淘宝反 Selenium 登陆破解
很简单,淘宝有反爬虫,而且是专门针对 Selenium 的。
这么操作,永远登陆不进去。
遇到这种反爬的时候,不要慌,慢慢思考。
通常,遇到这种反爬虫,第一反应就是:验证码滑块滑地太快了。
被检测出来了。
我刚开始也是这么想,所以我自己写了一个滑动方法。
匀速、加速、减速,甚至颤颤巍巍滑动,都不行!
显然,跟验证码滑块无关。
这时候,就得学会测试,分析出它的放爬虫策略。
分步测试,你就会发现,账号密码程序输入,滑块程序滑动,然后暂停程序,我们手动鼠标点击登录,就能登陆成功。
神奇吧?
这是为啥?
我猜测,应该是淘宝,有针对 Selenium 的 find_element_by_* 方法的 click 事件监听。
只要是使用 Selenium 完成的点击事件,淘宝就不让你登录。
具体怎么实现的我不清楚,但是我知道怎么破解。
很简单,Selenium 这个点击方法不行,那就换个第三方库呗!
Python 最不缺的就是各种各样的第三方库。
pyautogui 了解一下。
pyautogui 功能强大,可以操控电脑的鼠标,有类似「按键精灵」的功能。
pyautogui 的有些方法,甚至比「按键精灵」更强大。
安装方法也很简单,使用 pip 即可。
python -m pip install pyautogui
用法很简单,截取登录按钮那里的图片,像这样:![]()
![]()
然后 pyautogui 就可以根据这张图片,找到按钮的坐标,然后操控电脑的鼠标进行点击。
需要注意的是,截图工具一定要使用电脑自带,不要使用第三方截图工具!
coords = pyautogui.locateOnScreen('1.png')
x, y = pyautogui.center(coords)
pyautogui.leftClick(x, y)
就问你强大不?
直接修改代码,开搞!
from selenium import webdriver
import logging
import time
from selenium.common.exceptions import NoSuchElementException, WebDriverException
from retrying import retry
from selenium.webdriver import ActionChains
import pyautogui
pyautogui.PAUSE = 0.5
logging.basicConfig(level = logging.INFO,format = '%(asctime)s - %(name)s - %(levelname)s - %(message)s')
logger = logging.getLogger(__name__)
class taobao():
def __init__(self):
self.browser = webdriver.Chrome("path\to\your\chromedriver.exe")
# 最大化窗口
self.browser.maximize_window()
self.browser.implicitly_wait(5)
self.domain = 'http://www.taobao.com'
self.action_chains = ActionChains(self.browser)
def login(self, username, password):
while True:
self.browser.get(self.domain)
time.sleep(1)
#会xpath可以简化这几步
#self.browser.find_element_by_class_name('h').click()
#self.browser.find_element_by_id('fm-login-id').send_keys(username)
#self.browser.find_element_by_id('fm-login-password').send_keys(password)
self.browser.find_element_by_xpath('//*[@id="J_SiteNavLogin"]/div[1]/div[1]/a[1]').click()
self.browser.find_element_by_xpath('//*[@id="fm-login-id"]').send_keys(username)
self.browser.find_element_by_xpath('//*[@id="fm-login-password"]').send_keys(password)
time.sleep(1)
try:
# 出现验证码,滑动验证
slider = self.browser.find_element_by_xpath("//span[contains(@class, 'btn_slide')]")
if slider.is_displayed():
# 拖拽滑块
self.action_chains.drag_and_drop_by_offset(slider, 258, 0).perform()
time.sleep(0.5)
# 释放滑块,相当于点击拖拽之后的释放鼠标
self.action_chains.release().perform()
except (NoSuchElementException, WebDriverException):
logger.info('未出现登录验证码')
# 会xpath可以简化点击登陆按钮,但都无法登录,需要使用 pyautogui 完成点击事件
#self.browser.find_element_by_class_name('password-login').click()
#self.browser.find_element_by_xpath('//*[@id="login-form"]/div[4]/button').click()
# 图片地址
coords = pyautogui.locateOnScreen('1.png')
x, y = pyautogui.center(coords)
pyautogui.leftClick(x, y)
nickname = self.get_nickname()
if nickname:
logger.info('登录成功,呢称为:' + nickname)
break
logger.debug('登录出错,5s后继续登录')
time.sleep(5)
def get_nickname(self):
self.browser.get(self.domain)
time.sleep(0.5)
try:
return self.browser.find_element_by_class_name('site-nav-user').text
except NoSuchElementException:
return ''
if __name__ == '__main__':
# 填入自己的用户名,密码
username = 'username'
password = 'password'
tb = taobao()
tb.login(username, password)
淘宝针对 Selenium 的反爬,就这样解决了!
清空购物车
已经登陆进来了,清空购物车就小菜一碟了!
还是按照之前的步骤,自行分析吧。
这里很简单,我就直接贴代码了。
from selenium import webdriver
import logging
import time
from selenium.common.exceptions import NoSuchElementException, WebDriverException
from retrying import retry
from selenium.webdriver import ActionChains
import pyautogui
pyautogui.PAUSE = 0.5
logging.basicConfig(level = logging.INFO,format = '%(asctime)s - %(name)s - %(levelname)s - %(message)s')
logger = logging.getLogger(__name__)
class taobao():
def __init__(self):
self.browser = webdriver.Chrome("path\to\your\chromedriver.exe")
# 最大化窗口
self.browser.maximize_window()
self.browser.implicitly_wait(5)
self.domain = 'http://www.taobao.com'
self.action_chains = ActionChains(self.browser)
def login(self, username, password):
while True:
self.browser.get(self.domain)
time.sleep(1)
#会xpath可以简化这几步
#self.browser.find_element_by_class_name('h').click()
#self.browser.find_element_by_id('fm-login-id').send_keys(username)
#self.browser.find_element_by_id('fm-login-password').send_keys(password)
self.browser.find_element_by_xpath('//*[@id="J_SiteNavLogin"]/div[1]/div[1]/a[1]').click()
self.browser.find_element_by_xpath('//*[@id="fm-login-id"]').send_keys(username)
self.browser.find_element_by_xpath('//*[@id="fm-login-password"]').send_keys(password)
time.sleep(1)
try:
# 出现验证码,滑动验证
slider = self.browser.find_element_by_xpath("//span[contains(@class, 'btn_slide')]")
if slider.is_displayed():
# 拖拽滑块
self.action_chains.drag_and_drop_by_offset(slider, 258, 0).perform()
time.sleep(0.5)
# 释放滑块,相当于点击拖拽之后的释放鼠标
self.action_chains.release().perform()
except (NoSuchElementException, WebDriverException):
logger.info('未出现登录验证码')
# 会xpath可以简化点击登陆按钮,但都无法登录,需要使用 pyautogui 完成点击事件
#self.browser.find_element_by_class_name('password-login').click()
#self.browser.find_element_by_xpath('//*[@id="login-form"]/div[4]/button').click()
# 图片地址
coords = pyautogui.locateOnScreen('1.png')
x, y = pyautogui.center(coords)
pyautogui.leftClick(x, y)
nickname = self.get_nickname()
if nickname:
logger.info('登录成功,呢称为:' + nickname)
break
logger.debug('登录出错,5s后继续登录')
time.sleep(5)
def get_nickname(self):
self.browser.get(self.domain)
time.sleep(0.5)
try:
return self.browser.find_element_by_class_name('site-nav-user').text
except NoSuchElementException:
return ''
def clear_cart(self):
cart = self.browser.find_element_by_xpath('//*[@id="J_MiniCart"]')
if cart.is_displayed():
cart.click()
select = self.browser.find_element_by_xpath('//*[@id="J_SelectAll1"]/div/label')
if select.is_displayed():
select.click()
time.sleep(0.5)
go = self.browser.find_element_by_xpath('//*[@id="J_Go"]')
if go.is_displayed():
go.click()
submit = self.browser.find_element_by_xpath('//*[@id="submitOrderPC_1"]/div/a[2]')
if submit.is_displayed():
submit.click()
if __name__ == '__main__':
# 填入自己的用户名,密码
username = 'username'
password = 'password'
tb = taobao()
tb.login(username, password)
tb.clear_cart()
剩下的就是掏钱了。