【深度学习】卷积神经网络
本文为深度学习的学习总结,讲解卷积神经网络。欢迎交流
计算机视觉
如果我们想要输入的图片像素为 1000×1000×3,则此时神经网络特征维度为 3 百万, W [ 1 ] W^{[1]} W[1] 采用全连接时,维度更夸张。我们使用卷积运算来解决这个问题。
边缘检测 I
卷积运算是卷积神经网络最基本的组成部分。我们使用边缘检测作为入门样例。
为了让电脑搞清楚下面这张图片的内容,我们可能需要先检测图片中的垂直边缘,右上角的图为垂直边缘检测器的输出,右下角为水平边缘检测器的输出:
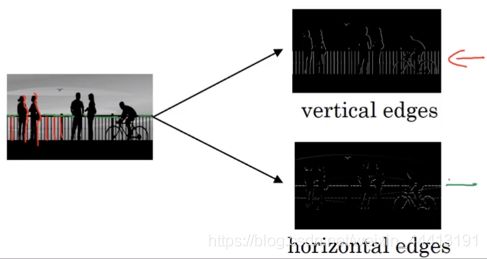
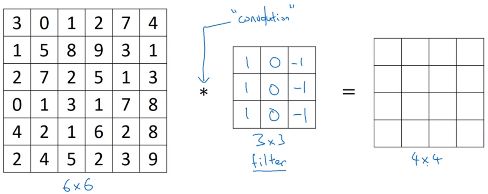
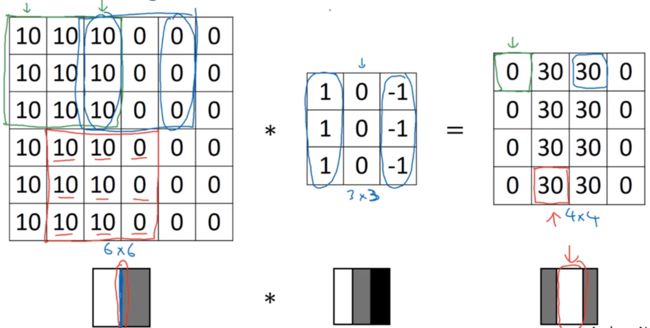
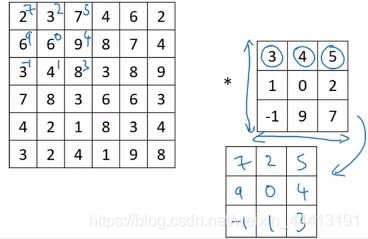
接下来我们讲解如何检测出这些边缘。下图中,左边为一个 6×6 的灰度图像,即 6×6×1 的矩阵,没有 RGB 三通道。我们可以构造图中中间的 3×3 矩阵,成为过滤器(或核), ∗ * ∗ 运算符为卷积运算。而矩阵运算的结果是一个 4×4 的矩阵,因为过滤器在图中左边的矩阵中有 4×4 个可能的位置,可将其看作 4×4 的图像:
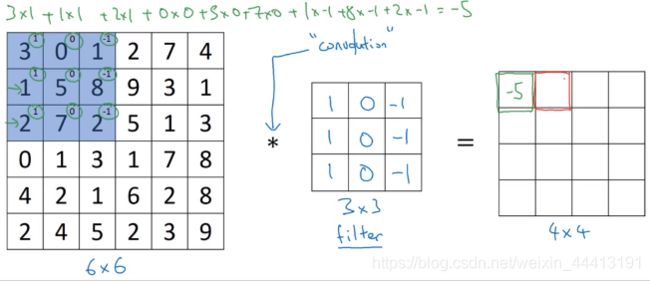
我们计算右边矩阵中的第一个元素的值。将 3×3 的过滤器覆盖在输入图像的蓝色区域,并在每个元素上标记过滤器的值,将对应元素相乘后求和 1 × 3 + 0 × 0 + . . . + 2 × − 1 = − 5 1\times3+0\times0+...+2\times-1=-5 1×3+0×0+...+2×−1=−5 得到第一个元素的值:
计算第二个元素的值将过滤器覆盖在这里:
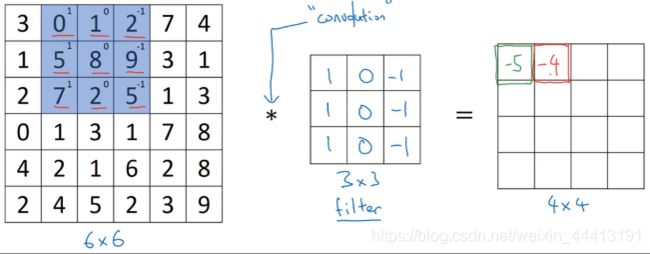
同理,可以计算出矩阵中所有元素的值。上图中间的矩阵为垂直边缘检测器。接下来对其进行解释。
下图左边图像中,左下角为其代表的图像,0 表示灰色,图像中间有一个明显的边缘。下图中间的过滤器可以可视化为其下面的图像。最右边为得到的矩阵,其对应的图像在右下角,中间的亮段对应到最左边的图像,就是检测到的边缘。
因为图像维度太小,因此检测到的边缘很粗,图像维度很大时可以很好的检测到边缘。
边缘检测 II
检测正负边
我们还可以检测图像中的正边和负边,即从亮到暗和从暗到亮,也就是边缘的过渡。
当我们将前文中的矩阵进行翻转时,用相同的过滤器进行卷积,得到的结果为右下角的矩阵:
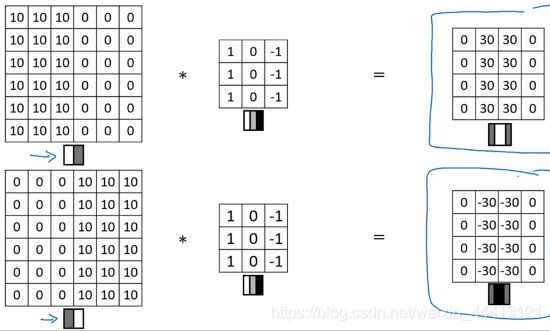
矩阵中的值为 -30,代表从暗到亮的过渡。因此这个过滤器可以区分两种明暗变化的区别。
同理,下图中右边的过滤器可以进行水平边缘的检测:

下图是一个更复杂的例子,最右边的检测结果中第 2 行第 1 列的 30 代表了最左边图像中的绿色区域,上边较亮下边较暗,是从亮到暗的过渡,检测到了一条正边缘。
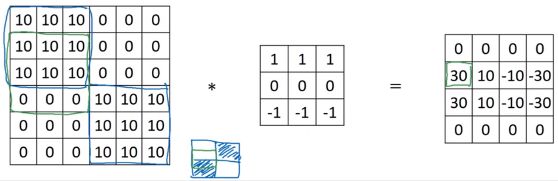
同理,右边矩阵第二行第四列的 -30 表示了左图中的紫色区域,检测到了负边缘:
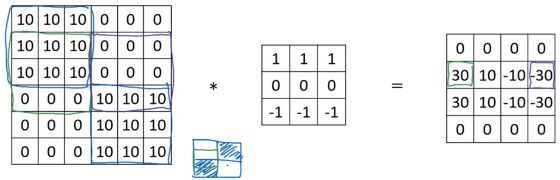
而第二行第二列的 10 表示了左图中的黄色区域,区域中左边两列是正边,右边一列是负边,求和后得到了中间值。
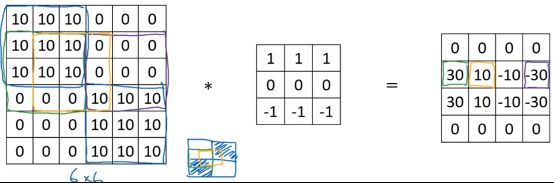
当图像很大时,则不会出现这样的过渡带。
选择过滤器
实际上,过滤器还有很多种选择,我们以垂直边缘过滤器为例进行介绍:
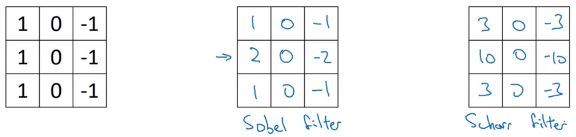
上图中间的过滤器称为 Sobel 过滤器,其增加了中间行的权重,就是图像中央的像素点,鲁棒性更高。右边的称为 Scharr 过滤器。
为了检测复杂图像的边缘,我们可以将过滤器中的 9 个值当作参数,使用反向传播算法学习过滤器。这种方式获取的特征可以胜过手动选择的过滤器,并可以检测到任何角度的边缘。我们会后面详细讲解这部分内容。
扩充图像—Padding
我们在前面的例子中已经看到,图像在进行卷积运算后会被缩小。如果我们有 n × n n\times n n×n 的图像和 f × f f\times f f×f 的过滤器做卷积,输出结果的维度是 ( n − f + 1 ) × ( n − f + 1 ) (n-f+1)\times(n-f+1) (n−f+1)×(n−f+1)。
注意角落边的像素,如左上角的像素只被一个输出使用,但是中间的像素会被多次使用,这意味着我们丢掉了图像边缘位置的许多信息。
为了解决以上两个问题,我们需要在进行卷积之前对图像进行扩充(padding)。例如,我们可以对下面的图像扩充一层像素,变成 8×8 的图像,卷积后得到 6×6 的输出,和原始图像大小相同。
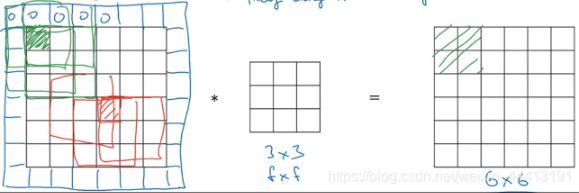
通常我们会用 0 填充。设扩充层数为 p p p,则输出变为 ( n + 2 p − f + 1 ) × ( n + 2 p − f + 1 ) (n+2p-f+1)\times(n+2p-f+1) (n+2p−f+1)×(n+2p−f+1) 的图像。并且此时图中左边图像中左上角的像素影响了图中右边图像的绿色格子,更多的信息被我们利用了。
关于 p p p 的选择,通常有 2 种:
- Valid 卷积:不填充,即 p = 0 p=0 p=0
- Same 卷积:填充后输出大小与输入相同,即 n + 2 p − f + 1 = n + f − 1 n+2p-f+1=n+f-1 n+2p−f+1=n+f−1,解得 p = f − 1 2 p=\frac{f-1}{2} p=2f−1。习惯上 f f f 通常为奇数,因为偶数会出现不对称的填充,且过滤器只有一个中心,方便在输入图像中选择位置。
卷积步长
卷积中的步幅是另一个构建卷积神经网络的基本操作。我们还是用之前的例子进行说明。
在前面的例子中,我们的步幅为 1,即每次选择过滤器的位置时,向右或向下移动 1 个单位。当步幅为 2 时,我们就会移动 2 个单位。如下图中的例子,我们移动 2 个单位,最终得到了 3×3 的输出。
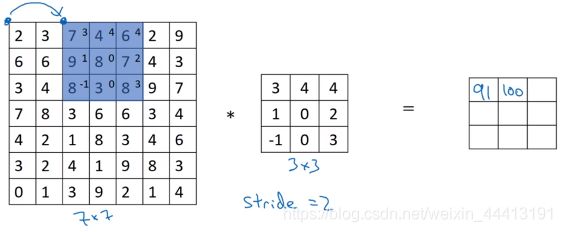
我们设步幅为 s s s,在蓝色图像不超出输入范围时,输出图像的大小为 ( n + 2 p − f s + 1 ) × ( n + 2 p − f s + 1 ) (\frac{n+2p-f}{s}+1)\times(\frac{n+2p-f}{s}+1) (sn+2p−f+1)×(sn+2p−f+1),为了解决商不是整数的问题,我们还需要对尺寸进行向下取整 ⌊ n + 2 p − f s + 1 ⌋ × ⌊ n + 2 p − f s + 1 ⌋ \lfloor\frac{n+2p-f}{s}+1\rfloor\times\lfloor\frac{n+2p-f}{s}+1\rfloor ⌊sn+2p−f+1⌋×⌊sn+2p−f+1⌋。
在数学中,我们前面所说的卷积运算其实为互相关,真正的卷积还需要对过滤器在横轴和纵轴进行翻转,见下图:
在信号处理或某些数学分支中会使用翻转,因为反转可以使卷积运算符有用结合律,这对信号处理的运用有好处。
( A ∗ B ) ∗ C = A ∗ ( B ∗ C ) (A*B)*C=A*(B*C) (A∗B)∗C=A∗(B∗C)
而在计算机视觉中,因为这次翻转并不会带来什么效果,因此我们忽略它,将互相关称为卷积。这样可以简化代码,并且神经网络也可以正常工作。
立体卷积
前面都是对二维图像做卷积,接下来我们介绍在三维立体上做卷积。
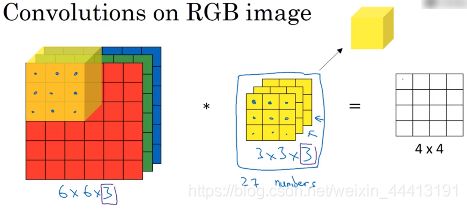
如果我们想检测 6×6×3 RGB 图像的特征,其中 3 指 3 个颜色通道,相当于 3 个 6×6 图像的叠加。我们将其与 3×3×3 的过滤器进行卷积,过滤器的 3 层也对应 3 个颜色通道。
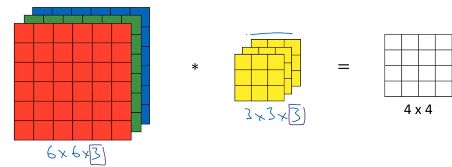
维度可以表示为:高度×宽度×通道数(或深度),输入和过滤器的通道数必须匹配,输出为 4×4×1.
为简化过滤器图像,我们将上图中的过滤器画成立体方块。卷积操作就是将过滤器方块放到左上角位置,共有 3×3×3=27 个数字,分别与输入中的 27 个数相乘后求和,得到左上角的输出值。
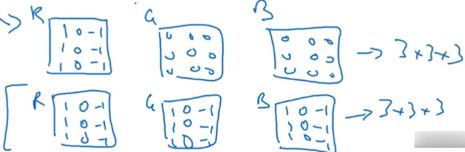
如果我们想检测红色通道的边缘,只需要将过滤器设置为下图中的第一行,红色检测边缘,绿色和蓝色都置 0;如果想检测任意颜色通道的边缘,则将过滤器设置为第二行的样子。
如果我们想要同时检测垂直和水平边缘,即同时使用多个过滤器。下图是垂直边缘过滤器和水平边缘过滤器的结合使用:
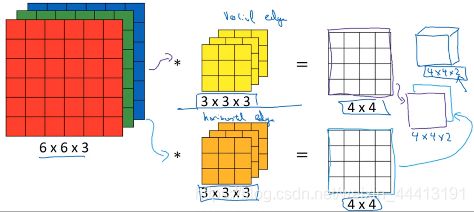
分别将过滤器与输入进行卷积,将得到的第一个输出放在前面,第二个输出放在后面,叠加得到 4×4×2 的输出立方体。
总结一下维度,我们将 n × n × n c n\times n\times n_c n×n×nc 的输入与 f × f × n c f\times f\times n_c f×f×nc 做卷积,假设步幅为 1 且没有使用 padding,得到输出的维数为 ( n − f + 1 ) × ( n − f + 1 ) × n c ′ (n-f+1)\times(n-f+1)\times n_c' (n−f+1)×(n−f+1)×nc′,其中 n c ′ n_c' nc′ 为使用的过滤器个数。
这样一来,我们就可以检测多个特征了。
单层卷积网络
继续使用上面的例子,我们使用 2 个过滤器最终生成了 2 个 4×4 的卷积神经网络层。
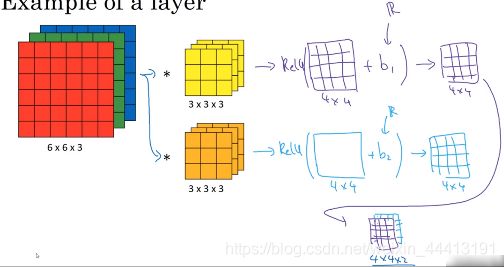
分别给 2 个输出的每个元素增加偏差 b 1 , b 2 b_1,b_2 b1,b2,然后应用非线性激励函数 ReLU,分别输出 1 个 4×4 的矩阵。将 2 个矩阵叠加得到一个 4×4×2 的矩阵。以上是卷积神经网络的一层。
将其映射到标准神经网络中 4 个卷积层的某一层或非卷积神经网络中,前向传播表示为:
z [ 1 ] = W [ 1 ] a [ 0 ] + b [ 1 ] , a [ 0 ] = x z^{[1]}=W^{[1]}a^{[0]}+b^{[1]}, \quad a^{[0]}=x z[1]=W[1]a[0]+b[1],a[0]=x
a [ 1 ] = g ( z [ 1 ] ) a^{[1]}=g(z^{[1]}) a[1]=g(z[1])
对应输入为 a [ 0 ] = x a^{[0]}=x a[0]=x,过滤器用 W [ 1 ] W^{[1]} W[1] 表示,卷积操作相当于 W [ 1 ] a [ 0 ] W^{[1]}a^{[0]} W[1]a[0],然后加上偏差,再使用非线性激励函数,得到的 4×4×2 矩阵为神经网络的下一层,即激活层。以上是 a [ 0 ] a^{[0]} a[0] 到 a [ 1 ] a^{[1]} a[1] 的演变过程,将一个 6×6×3 维度的 a [ 0 ] a^{[0]} a[0] 演化为 4×4×2 维度的 a [ 1 ] a^{[1]} a[1]。
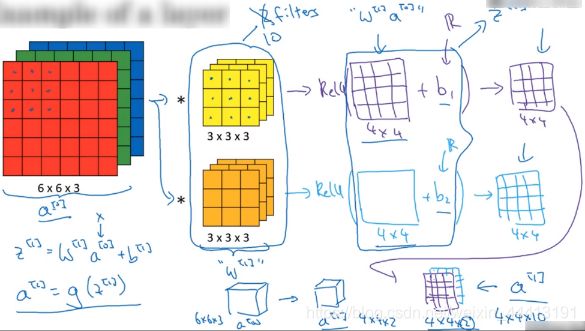
在这里例子中,如果我们使用 10 个过滤器,则会得到 4×4×10 的输出图像。再举一个例子。如果我们有 10 个过滤器,神经网络的一层是 3×3×3,我们来计算一下这一层的参数个数。
每层过滤器有 3 × 3 × 3 = 27 3\times3\times3=27 3×3×3=27 个参数,再加一个偏差为 27 + 1 = 28 27+1=28 27+1=28,因此 10 个过滤器的参数个数为 28 × 10 = 280 28\times10=280 28×10=280。
注意上面的计算,无论输入图像有多大,参数始终为 280 个,即使我们使用了 10 个过滤器对 10 个特征进行检测。这就是卷积神经网络的一个重要特征——“避免过拟合”。
在这里我们总结一下用于描述卷积神经网络的一层(即卷积层)的各种标记:
-
f [ l ] f^{[l]} f[l] 表示第 l l l 层的过滤器大小, p [ l ] p^{[l]} p[l] 为 padding 的数量, s [ l ] s^{[l]} s[l] 为步幅。
-
输入为 n H [ l − 1 ] × n W [ l − 1 ] × n c [ l − 1 ] n_H^{[l-1]}\times n_W^{[l-1]}\times n_c^{[l-1]} nH[l−1]×nW[l−1]×nc[l−1] 来自上一层
-
输出为 n H [ l ] × n W [ l ] × n c [ l ] n_H^{[l]}\times n_W^{[l]}\times n_c^{[l]} nH[l]×nW[l]×nc[l],其中 n H [ l ] = ⌊ n H [ l − 1 ] + 2 p [ l ] − f [ l ] s [ l ] + 1 ⌋ , n W [ l ] = ⌊ n W [ l − 1 ] + 2 p [ l ] − f [ l ] s [ l ] + 1 ⌋ n_H^{[l]}=\lfloor\frac{n_H^{[l-1]}+2p^{[l]}-f^{[l]}}{s^{[l]}}+1\rfloor,n_W^{[l]}=\lfloor\frac{n_W^{[l-1]}+2p^{[l]}-f^{[l]}}{s^{[l]}}+1\rfloor nH[l]=⌊s[l]nH[l−1]+2p[l]−f[l]+1⌋,nW[l]=⌊s[l]nW[l−1]+2p[l]−f[l]+1⌋,输出图像的通道 n c [ l ] n_c^{[l]} nc[l] 为过滤器的数量。
-
每个过滤器的维度为 f [ l ] × f [ l ] × n c [ l − 1 ] f^{[l]}\times f^{[l]}\times n_c^{[l-1]} f[l]×f[l]×nc[l−1],其通道数与输入通道数相等。
-
应用偏差和激活函数后,这一层的输出等于其激活值 a [ l ] a^{[l]} a[l],维度为这一层的输出维度 n H [ l ] × n W [ l ] × n c [ l ] n_H^{[l]}\times n_W^{[l]}\times n_c^{[l]} nH[l]×nW[l]×nc[l]。
-
当执行梯度下降时,如果有 m m m 个样本,就有 m m m 个激活值的集合,则输出 A [ l ] = m × n H [ l ] × n W [ l ] × n c [ l ] A^{[l]}=m\times n_H^{[l]}\times n_W^{[l]}\times n_c^{[l]} A[l]=m×nH[l]×nW[l]×nc[l]
-
权重参数的维度为过滤器维度×过滤器数量: f [ l ] × f [ l ] × n c [ l − 1 ] × n c [ l ] f^{[l]}\times f^{[l]}\times n_c^{[l-1]}\times n_c^{[l]} f[l]×f[l]×nc[l−1]×nc[l],损失数量就是 l l l 层中过滤器的个数
-
偏差的维度为 n c [ l ] n_c^{[l]} nc[l],在代码中表示为 1 × 1 × 1 × n c [ l ] 1\times1\times1\times n_c^{[l]} 1×1×1×nc[l] 的四维向量或张量
因为深度学习相关文献未统一记法,因此这只是一部分标记法。本系列将使用这种标记法。
简单卷积网络示例
我们来看一个深度卷积神经网络的具体示例。
现在我们有一张图像想做图像分类或图像识别,将图片输入定义为 x x x。我们来构建适用于这项任务的卷积网络,构建过程如下:
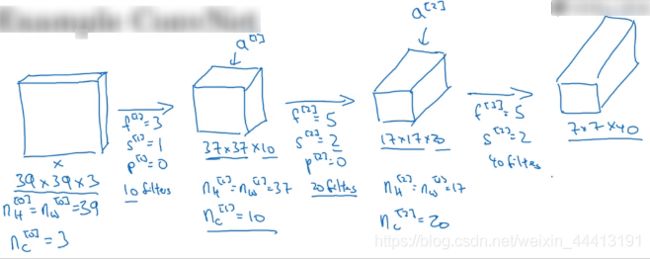
最终为图片提取了 7 × 7 × 40 = 1960 7×7×40=1960 7×7×40=1960 个特征。然后将卷积层平滑或展开成 1960 个单元,将所有的单元平滑处理后输出一个长向量,填充到 logistic 回归单元还是 softmax 回归单元取决于我们的任务类型是识别还是分类 k k k 种对象。最终 y ^ \hat y y^ 表示最终神经网络的预测输出。
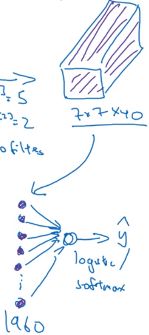
对于超参数选择的问题,将会在后面的文章中详细讲解。
随着神经网络计算深度不断加深,图像的深度开始会保持,然后随着网络深度的加深而减小,而信道数量在增加。这种趋势经常会在神经网络中见到。
一个典型的卷积网络通常有三层,分别为卷积层(CONV)、池化层(POOL)、全连接层(FC)。虽然仅用卷积层也能构建出很好的神经网络,但大部分神经网络依然会添加池化层和全连接层,其设计比卷积层简单。
池化层
在神经网络中,我们使用池化层来所见模型的大小,提高计算速度,同时提高所提取特征的鲁棒性。
接下来我们介绍池化层的定义。假设下图中左边为 4×4 的输入,执行最大池化的输出是一个 2×2 的矩阵。
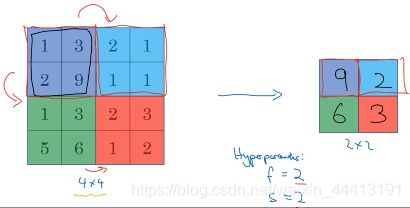
将 4×4 的输入拆分成不同区域,用 4 种不同颜色标记。对于 2×2 的输出,其每个元素都是对应颜色区域中的最大元素值。类似于应用了维度为 2×2,步幅为 2 的过滤器,即最大池化的超参数。计算卷积层输出维度的公式同样适用于最大池化
可以将输入看作某些特征的集合,即神经网络某层中的反激活集合,数字大意味着可能提取了某些特定特征。如左上角的 9,可能是一个垂直边缘,然而右上角不存在这个特征。最大化操作的功能就是只要在任何一个象限内提取到某个特征,都会保留在最大化池的输出里,如果没有这个特征(例如右上角),其最大值还是很小。
虽然最大池化有 2 个超参数,但是这是手动设置或者通过交叉验证得到的,无需学习。
对于下面这个三维的例子,计算方法与卷积层相同:
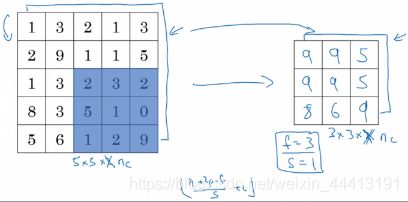
还有另外一种类型的池化,称为平均池化,即计算每个区域的平均值作为输出,不是很常用,仅在深度很深的神经网络可以使用平均池化分解网络的表示层,在整个空间求平均值。
最大池化的超参数通常使用 f = 2 , s = 2 f=2,s=2 f=2,s=2,效果相当于高度和宽度缩减一半,或 f = 3 , s = 2 f=3,s=2 f=3,s=2。并且通常不会使用 padding,但也有例外,我们后面会讲到。
因为最大池化没有参数可以学习,因此反向传播没有参数适用于最大池化,最大池化只是计算神经网络某一层的静态属性。
卷积神经网络示例
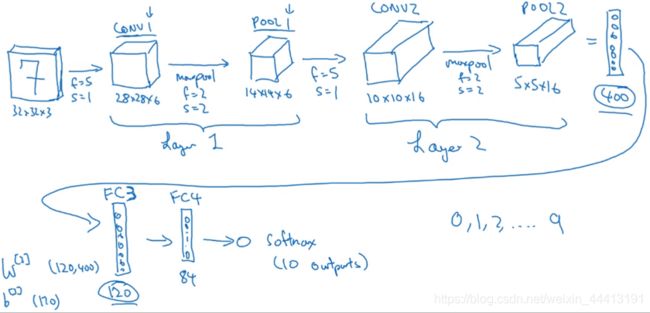
卷积神经网络的模块介绍的差不多了,我们接下来看一个例子。假设有一个大小为 32×32×3 的 RGB 输入图片,我们想做手写体数字识别(神经网络中的经典例子)。我们用的网络模型和典型的 LeNet-5 相似,许多参数与之相似。构造过程见下图,使用的参数都标记在旁边:
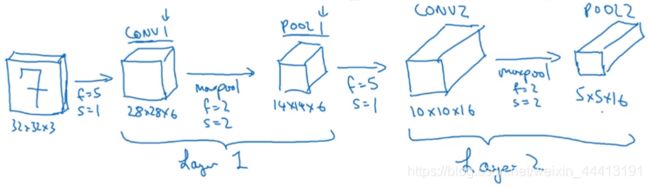
我们通常计算神经网络层数时只是统计具有权重和参数的层,因为池化层没有参数,所以将 CONV 1 和 POOL 1 称为 Layer 1。也可以将两者独立为两层。5×5×16 矩阵包含 400 个元素,将 POOL 2 平整化为一个大小为 400 的一维向量。然后构造下一层的全连接层,标记位 FC 3。全连接层类似我们前面介绍的【单神经网络层】,具有 400×120 的权重矩阵 W [ 3 ] W^{[3]} W[3],及 120 维的偏差参数。再用 FC 4 层连接后,将这 84 个输出单元填充一个 softmax 单元,有 10 个输出。
上面的例子中有很多超参数,尽量不要自己设置,而是查看文献中别人使用了哪些超参数,选一个在别人任务中效果很好的架构,很有可能也适用于自己的程序。这部分内容后面会详细讲解。
神经网络中一种常见模式是一个或多个卷积层后跟着一个池化层,再经过一次同样的处理,然后是几个 FC 层,随后是一个 softmax。
神经网络的激活值维度及参数个数如下:
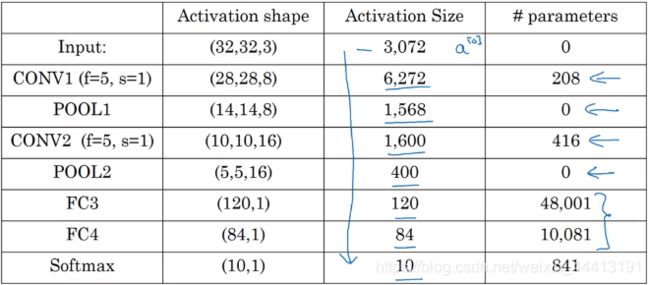
可以从表格中看出,池化层没有参数,卷积层参数相对较少,大多数参数都存在于 FC 层。随着神经网络的加深,激活值会逐渐变小,但如果激活值下降太快也会影响网络性能。
目前许多计算机视觉研究正在探索如何将这些模块整合起来构造高效的神经网络,这需要深入的理解和感觉。其最好的方法就是大量阅读别人的案例。
为什么使用卷积
和只用全连接层相比,卷积层有 2 个主要的优势,从而能够大量减少参数。
-
参数共享
特征检测(如垂直边缘检测)如果适用于图片的某个区域,也可能适用于其他区域。例如我们使用同一个过滤器对整个图像进行检测。这不仅适用于边缘特征这样的低阶特征,同样也适用于高阶特征,例如提取脸上的眼睛。
-
稀疏连接
图中右边矩阵左上角的 0 只依赖于左边输入中阴影部分的 3×3 单元格,仅与 36 个输入特征中的 9 个相连接,其他像素值不会对输出产生任何影响
通过这两种机制,我们可以减少参数以便于使用更小的训练集,从而预防过拟合。
卷积神经网络还善于捕捉平移不变,即使输入移动几个像素,图片依然具有十分相似的特征,属于同一个输出标记。实际上,我们用同一个过滤器生成各层中图片的所有像素值,希望网络通过自动学习变得更加健壮,以便更好地取得平移不变属性。
最后,我们将这些层整合,对神经网络进行训练。例如我们要构建一个猫咪检测器,有训练集 ( x ( 1 ) , y ( 1 ) ) , . . . , ( x ( m ) , y ( m ) ) (x^{(1)},y^{(1)}),...,(x^{(m)},y^{(m)}) (x(1),y(1)),...,(x(m),y(m)), x x x 表示一张图片, y y y 为二进制标记。构建步骤如下:
-
输入图片,增加卷积层和池化层,添加全连接层,最后输出 softmax,即 y ^ \hat y y^。
-
卷积层和全连接层有参数 W , b W,b W,b,我们可以用任何参数集合来定义代价函数。
-
随机初始化参数 W , b W,b W,b, C o s t J CostJ CostJ 为神经网络对整个训练集预测的损失总和:
C o s t J = 1 m L ( y ^ ( i ) , y ( i ) ) CostJ=\frac{1}{m}L(\hat{y}^{(i)},y^{(i)}) CostJ=m1L(y^(i),y(i)) -
使用梯度下降法或其他高级优化方法来优化神经网络中所有参数,以减少代价 J J J。
至此,卷积神经网络的所有基本模块就介绍完了,终于可以试着使用这些结构来解决自己的问题了!