PyTorch和Numpy之间的关联
PyTorch介绍
A Tensor library like Numpy, unlike Numpy it has strong GPU support. Lua is a wrapper for Torch (Yes! you need to have a good understanding of Lua), and for that you will need LuaRocks package manager.
由此可见,PyTorch和Numpy有着千丝万缕的关系。为了提高学习效率,特意把两者之间的关联总结出来。
如何获取数据的基本属性
数据的基本属性包括数据的维度、元素个数、每一维的大小。
- Numpy
| 基本属性 | Numpy类别 | API |
|---|---|---|
| 维度 | 属性 | ndim |
| 元素个数 | 属性 | size |
| 每一维的大小 | 属性 | shape |
import numpy as np
n = np.random.rand(5, 3)
print(n.ndim)
print(n.size)
print(n.shape)
下图为Google Colab的结果:

- PyTorch
| 基本属性 | Numpy类别 | API |
|---|---|---|
| 维度 | 方法 | dim() |
| 元素个数 | 方法 | numel() |
| 每一维的大小 | 属性 | shape |
| 每一维的大小 | 方法 | size() |
import torch
t = torch.rand(5, 3)
print(t.dim())
print(t.numel())
print(t.shape)
print(t.size())
下图为Google Colab的结果:

特殊的零维数据
之所以特别提出来,是因为PyTorch 0.4版本也支持了零维数据(标量)。具体代码如下所示:
import numpy as np
import torch
n = np.array(1)
t = torch.tensor(1)
同样,PyTorch和Numpy中的其余初始化函数,是无法生成标量的。如后续用到的torch.full((), 7)。
注意点
- 传参的类型,部分API传入的是元组,而部分传入的是逗号隔开的参数。其中Numpy中shape一般传入为元组,而Torch中shape一般传入为逗号隔开的参数。根据实践发现,如果不指认数据元素是什么,直接使用逗号隔开的参数即可。如果是需要指认数据元素,如full,第一个参数为shape,用元组表示,第二个参数是数据。
- 部分API生成的元素默认为Int类型,而另外一部分为Float类型。
构建数据
等差数列
| 库 | API |
|---|---|
| Numpy | np.arange() |
| PyTorch | torch.arange() |
随机初始化
[0, 1)初始化
| 库 | API |
|---|---|
| Numpy | np.random.rand() |
| PyTorch | torch.rand() |
API中的参数均为每一维的大小,如torch.rand(5, 3),数据维度为5行3列。
标准正态分布初始化
| 库 | API |
|---|---|
| Numpy | np.random.randn() |
| PyTorch | torch.randn() |
API中的参数均为每一维的大小,如torch.randn(5, 3),数据维度为5行3列。
正态分布初始化
| 库 | API | 参数说明 |
|---|---|---|
| Numpy | np.random.normal() | para1为均值,para2为方差,para3为shape |
| PyTorch | torch.normal() | para1为均值,para2为方差,但两者都必须为FloatTensor类型 |
错误代码如下所示:
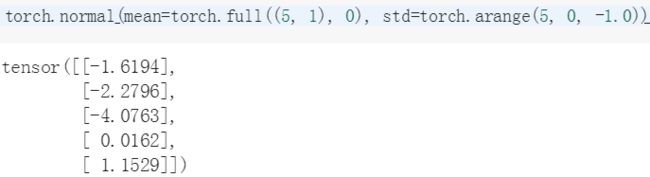
torch.normal(mean=torch.full((5, 1), 0), std=torch.arange(5, 0, -1))

正确代码如下所示:
torch.normal(mean=torch.full((5, 1), 0), std=torch.arange(5, 0, -1.0))
打乱元素顺序
| 库 | API | 差异点 |
|---|---|---|
| Numpy | np.random.shuffle() | 参数类型为np.array类型 |
| PyTorch | torch.randperm() | 参数类型为整型 |
所以Pytorch打乱顺序需要两步操作,第一步通过randperm函数得到索引,第二步通过索引得到最终打乱顺序的元素。
full张量
| 库 | API | 差异点 |
|---|---|---|
| Numpy | np.full() | 不改变传入参数类型 |
| PyTorch | torch.full() | 传入参数若为整型,返回结果则为浮点型 |
ones/zeros张量
| 张量 | Numpy | PyTorch |
|---|---|---|
| ones | np.ones() | torch.ones() |
| zeros | np.zeros() | torch.zeros() |
返回结果默认为浮点类型。其中Numpy中shape传入为元组,而Torch中shape传入为逗号隔开的参数。
eye张量(单位向量)
| 库 | API | 相同点 |
|---|---|---|
| Numpy | np.eye() | 参数逗号隔开 |
| PyTorch | torch.eye() | 参数逗号隔开 |
para1决定张量的形状,比如3,就是三行三列,para2决定张量输出的列数,比如2,输出列数则为2。
PyTorch张量操作
Fancy Indexing
其中大部分操作和python的切片操作相同,就不一一进行介绍了。下文主要介绍一些新的特性:
select by mask
x = torch.rand(3, 5)
#方法一
mask = x.ge(0.5)
torch.masked_select(x, mask)
#方法二
x[torch.ge(x, 0.5)]
#方法三
x[x > 0.5]
select by flatten index
torch.take函数是把数据先展开为一维,然后根据索引进行选取。具体使用代码如下所示:
t = torch.tensor([[1, 2, 3], [4, 5, 6]])
torch.take(t, torch.tensor([0, 3]))
结果为tensor([1, 4])
维度变换
维度转换
采用view()函数。
升维和降维
| 库 | API | 说明 |
|---|---|---|
| 升维 | unsqueeze() | 在指定位置(输入参数)上增加维度,并指定维度为1 |
| 降维 | squeeze() | 删除指定维度,如果该维度为1,则删除成功,否则数据保持不变 |
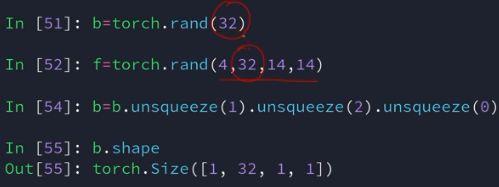

扩展
| API | 说明 | 调用方式 |
|---|---|---|
| extand | 推荐,必要之时复制内存,速度快 | 若某一维度不改变,则用-1表示 |
| repeat | 复制内存 | 调用方式如上所示 |
转置
| API | 说明 |
|---|---|
| t.() | 只适合二维张量 |
| transpose(d1, d2) | 输入的两个参数表示的是要交换的某两个维度 |
需要注意的是,转置之后内存并没有发生改变,如果需要进行维度变换如view,就需要先使用contiguous()函数。可参考一下链接: https://discuss.pytorch.org/t/what-ops-make-a-tensor-non-contiguous/3676/2
https://docs.scipy.org/doc/numpy/reference/arrays.ndarray.html#internal-memory-layout-of-an-ndarray
比较两个张量
torch.all(torch.eq(a, b))
多维转置
当前维度转变为原有维度的维数。
a = torch.rand(32, 3, 18, 28)
a.permute(0, 2, 3, 1)
a.shape
结果为torch.Size([32, 18, 28, 3])
如permute(0, 2, 3, 1)中的2指的是原来的第二维变为现在的第一维。由于第0维不变,则执行完前两个结果即为torch.Size([32, 18])。
广播(broadcast)
从低维向高维扩展,并且是每一维扩展都必须满足以下规则:
- 如果维度为1,则扩展到相同维度。
- 如果维度不存在,则增加一维,然后扩展到相同维度。
- 如果前两条规则不满足,则无法进行广播操作。
合并
- cat
para1是一个元组,即合并的数据。para2指的是合并的维度。其中除了要合并的维度以外,其他的维度必须相同。
x = torch.randn(2, 3)
torch.cat((x, x, x), 0)
- stack
创建一个新的维度。可以理解为创建了一个组。但它的要求是所有的维度都必须相同。
a = torch.rand(20, 5)
b = torch.rand(20, 5)
c = torch.stack((a, b))
print(c.shape)
结果为torch.Size([2, 20, 5]

分割
- split(按照长度进行划分)
a = torch.rand(20, 5)
b = torch.rand(20, 5)
c = torch.rand(20, 5)
s = torch.stack((a, b, c))
s1, s2 = s.split([2,1], dim=0)
print(s1.shape)
print(s2.shape)
结果为:
torch.Size([2, 20, 5])
torch.Size([1, 20, 5])
- chunk(按照划分后的数据块个数进行拆分)
均匀分布为若干个数据块。
a = torch.rand(20, 5)
b = torch.rand(20, 5)
c = torch.rand(20, 5)
s = torch.stack((a, b, c))
s1, s2, s3 = s.chunk(3, dim=0)
print(s1.shape)
print(s2.shape)
print(s3.shape)
结果为:
torch.Size([1, 20, 5])
torch.Size([1, 20, 5])
torch.Size([1, 20, 5])