本文根据 Flink Forward 全球在线会议 · 中文精华版整理而成,由阿里巴巴计算平台事业部资深算法专家杨旭(品数)分享。本文主要介绍了 Alink 从宣布开源到现在,最近半年来的进展情况,重点分享了 Alink 的一些特性、原理、使用技巧等,为大家使用 Alink 进行开发提供了参考。
Alink进展总览
Alink 到目前已经发布了四个 Release 版本:
- Alink version 1.0:2019年11月在Flink Forword Asia大会上宣布开源。
- Alink version 1.0.1:于2019年12月发布,主要解决一些场景下PyAlink的安装问题。在此期间也出了一系列的开发文章,包括Alink环境搭建,入门示例等,为大家使用Alink第一步提供了指导。
- Alink version 1.1.0:于2020年02月发布,在Flink发布1.10版本后,Alink 第一时间做了兼容,目前Alink支持Flink 1.10和Flink 1.9,PyAlink也兼容PyFlink。此外,从这个版本开始,Alink已经发布到Maven中央仓库和PyPI。这样,Maven工程中使用Alink,只需要在POM文件中引入Alink的相关依赖就可以了,无需自己手动编译,打包安装。Python环境则可以借助PyPI仓库,进行Alink的安装。
- Alink version 1.1.1 :于2020年04月发布,主要是提升了使用体验,提升了性能。
Alink 发展之路
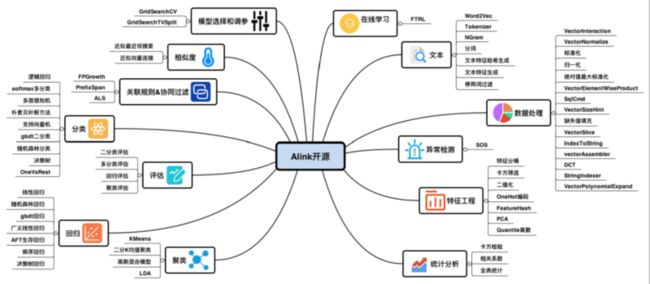
上图是Alink在发布1.0版本的时候,所有的算法以及功能,简单来说,Alink的批式功能是和SparkML对应的,SparkML有的功能,Alink基本都提供了。相较于SparkML,除了批式的功能,Alink还提供了流式的功能。
Alink在近半年,功能上整体没有大的变化,下面列举一些正在研发测试,即将开源的一些功能:
- 提供更多数据处理,特征工程相关功能,在小版本就会陆续推出。
- 经典的分类和回归问题上,主要为两个方面:一是对已有模型,我们将会披露更多模型内部信息,让大家对模型有更多的了解,而不仅仅只是拿模型来进行预测,二是FM系列算法的推出。
- 关联规则&协同过滤,在协同过滤推荐问题上,SparkML主要提供的是ALS,它可以解决一些推荐的问题,但是实际运用过程中,仅仅使用ALS是不够的,后续Alink将推出更多推荐类的算法。
- 在线学习,在1.0发布的时候,已经提供了在线学习的功能,但在实际应用场景中,用户希望在线学习能够变得更加灵活,后续的版本中将会对这部分进行加强。
重要特性介绍
在本章,将按照版本的发布顺序,逐步介绍Alink的特性,设计原理,以及使用技巧等内容。
1.Alink version 1.1.0
■ 程序构建
从Alink 1.1.0开始,使用Maven中央仓库即可构建Alink项目,下面是POM文件示例。Flink 1.10版本依赖:
com.alibaba.alink
alink_core_flink-1.10_2.11
1.1.0
org.apache.flink
flink-streaming-scala_2.11
1.10.0
org.apache.flink
flink-table-planner_2.11
1.10.0
Flink 1.9版本依赖:
com.alibaba.alink
alink_core_flink-1.9_2.11
1.1.0
org.apache.flink
flink-streaming-scala_2.11
1.9.0
org.apache.flink
flink-table-planner_2.11
1.9.0
■ 环境安装实践
- 准备环节
主要是Python环境搭建,以及JAVA 8的安装,Python环境的搭建我们推荐安装Anaconda3,可以对Python的版本进行灵活的控制。不同操作系统的环境准备,请参考下面的教程:
MacOS: https://zhuanlan.zhihu.com/p/...
Linux环境: https://zhuanlan.zhihu.com/p/...
Windows:https://zhuanlan.zhihu.com/p/...
- PyAlink安装
从1.1.0开始,Alink已经发布到了PyPI,安装更加方便了,请参考如下链接:
如何安装最新版本PyAlink?
https://zhuanlan.zhihu.com/p/...
- PyAlink卸载
如果之前安装过PyAlink,因为之前版本我们是手动安装的,在升级到新版本时,可能会遇到一些问题,因此需要将其卸载,可以参考下面的文章:
PyAlink的版本查询、卸载旧版本:
https://zhuanlan.zhihu.com/p/...
■ Notebook开发实践
在讲 Notebook 示例之前,我们先来了解一下 PyAlink 的设计背景:
- 在机器学习应用开发过程中,我们经常会先在批式环境进行模型训练,然后在流式的环境应用模型,从批式环境转换到流式环境,往往需要重写代码,无法做到代码的复用。Alink设计之初,就希望尽量将批和流之间的差异变得最小,比如,批上做完后,只需要将Batch字样改成Stream字样就可以运行。
- 机器学习开发的过程,我们一般是希望越快越好,越敏捷越好。其实在本机上开发,体验是最好的,一般做法是,在本机小数据规模上进行验证,然后上到集群上进行效果的评估。但是本机环境往集群环境迁移,并不容易,我们希望这个过程有一个好的体验,不用去编写大量的代码。
基于这样的设计背景,我们来看下一现在Notebook上进行Alink开发的实践。
- PyAlink 批式任务在 Notebook 上运行
本地运行代码示例:
from pyalink.alink import *
## 一个 Batch 作业的例子
useLocalEnv(2)
## prepare data
import numpy as np
import pandas as pd
data = np.array([
[0, 0.0, 0.0, 0.0],
[1, 0.1, 0.1, 0.1],
[2, 0.2, 0.2, 0.2],
[3, 9, 9, 9],
[4, 9.1, 9.1, 9.1],
[5, 9.2, 9.2, 9.2]
])
df = pd.DataFrame({"id": data[:, 0], "f0": data[:, 1], "f1": data[:, 2], "f2": data[:, 3]})
inOp = BatchOperator.fromDataframe(df, schemaStr='id double, f0 double, f1 double, f2 double')
FEATURE_COLS = ["f0", "f1", "f2"]
VECTOR_COL = "vec"
PRED_COL = "pred"
vectorAssembler = (
VectorAssembler()
.setSelectedCols(FEATURE_COLS)
.setOutputCol(VECTOR_COL)
)
kMeans = (
KMeans()
.setVectorCol(VECTOR_COL)
.setK(2)
.setPredictionCol(PRED_COL)
)
pipeline = Pipeline().add(vectorAssembler).add(kMeans)
pipeline.fit(inOp).transform(inOp).firstN(9).collectToDataframe()集群运行代码示例:
from pyalink.alink import *
## 一个 Batch 作业的例子
useRemoteEnv("10.101.**.**", 31805, 2, shipAlinkAlgoJar=False)
## prepare data
import numpy as np
import pandas as pd
data = np.array([
[0, 0.0, 0.0, 0.0],
[1, 0.1, 0.1, 0.1],
[2, 0.2, 0.2, 0.2],
[3, 9, 9, 9],
[4, 9.1, 9.1, 9.1],
[5, 9.2, 9.2, 9.2]
])
df = pd.DataFrame({"id": data[:, 0], "f0": data[:, 1], "f1": data[:, 2], "f2": data[:, 3]})
inOp = BatchOperator.fromDataframe(df, schemaStr='id double, f0 double, f1 double, f2 double')
FEATURE_COLS = ["f0", "f1", "f2"]
VECTOR_COL = "vec"
PRED_COL = "pred"
vectorAssembler = (
VectorAssembler()
.setSelectedCols(FEATURE_COLS)
.setOutputCol(VECTOR_COL)
)
kMeans = (
KMeans()
.setVectorCol(VECTOR_COL)
.setK(2)
.setPredictionCol(PRED_COL)
)
pipeline = Pipeline().add(vectorAssembler).add(kMeans)
pipeline.fit(inOp).transform(inOp).firstN(9).collectToDataframe()我们可以看到本地和远程代码上的差别,就只有第4行代码不一样,本地使用的是useLocalEnv(2),远程使用的是useRemoteEnv("10.101..", 31805, 2, shipAlinkAlgoJar=False)。相较于本地环境,集群环境需要指定Flink集群的ip地址和端口。
- PyAlink 流式任务在 Notebook 上运行
本地运行示例:
from pyalink.alink import *
## 一个 Stream 作业的例子
## 唯一参数表示并行度
useLocalEnv(2)
source = CsvSourceStreamOp() \
.setSchemaStr(
"sepal_length double, sepal_width double, petal_length double, petal_width double, category string") \
.setFilePath("http://alink-dataset.cn-hangzhou.oss.aliyun-inc.com/csv/iris.csv")
source.print()
StreamOperator.execute()集群运行示例:
from pyalink.alink import *
## 一个 Stream 作业的例子
useRemoteEnv("10.101.**.**", 31805, 2, shipAlinkAlgoJar=False, localIp="30.39.**.**")
source = CsvSourceStreamOp() \
.setSchemaStr(
"sepal_length double, sepal_width double, petal_length double, petal_width double, category string") \
.setFilePath("http://alink-dataset.cn-hangzhou.oss.aliyun-inc.com/csv/iris.csv")
source.print()
StreamOperator.execute()我们可以看到,流式任务的运行,本地和集群上的代码也只有设置运行环境这一行(第4行)代码有差别,其他的代码都是一样的。
集群运行模式中,流式任务和批式任务的设置有点差别,流式的任务需要指定本地的IP地址(localIp),我们使用Notebook进行交互式开发时,一般需要看到运行结果,批式任务使用Flink现有的机制,是可以直接看到运行结果的。但是流式任务数据流是无边界的,为了将流任务的运行结果返回回来,让用户可以实时看到,我们单独建立了一个通路进行数据传输,因此我们需要设置这个本地的IP地址,和集群进行交互。当然,这个本地IP地址的参数,在4月份的版本(Alink 1.1.1版本)中,已经可以自动检测到了,可以省略掉了。
■ PyAlink 基于 PyFlink 整合
本节中,重点介绍两点PyAlink和PyFlink的兼容特性。
- 数据的连通性:Alink 算子的输入输出,本质上是Flink的Table格式,PyFlink其实也是Flink Table,这样Alink Operator与PyFlink两个就可以相互转化,而且转换的代价非常小,并不涉及到数据的重写。有了这种转换,Alink和PyFlink两边的功能就可以混用,方便串联 Flink 和 Alink 的工作流。
下面是一段Alink和PyFlink代码混用的示例:
### get_mlenv.py
from pyalink.alink import *
env, btenv, senv, stenv = getMLEnv()
### 使用 PyFlink 接口,与 Table 进行互转
table = stenv.from_elements([(1, 2), (2, 5), (3, 1)], ['a', 'b'])
source = TableSourceStreamOp(table)
source.print()
StreamOperator.execute()我们可以看到,使用PyFlink 构建Table(第5行),可以直接转化为PyAlink的数据源算子(第6行)。
- 新提供了 getMLEnv 接口,能直接使用 flink run -py *.py 往集群提交作业。除了Notebook交互式运行Alink任务这种方式,对于定时调度的任务,我们需要一次性提交任务,PyFlink在这方面支持非常好,PyAlink和PyFlink兼容后,我们可以达到和PyFlink提交任务一样的使用体验。只是有一点不同,在获取运行环境的时候,需要改为调用getMLEnv()方法,这个方法会返回env, btenv, senv, stenv四个运行环境,这样PyAlink的任务可以交给PyFlink,执行PyFlink 相关操作。
下面是提交任务的示例:
### 直接运行脚本
python kmeans.py
### 向集群提交作业
PYFLINK_PATH=`python -c "import pyflink;print(pyflink.__path__[0])"`
${PYFLINK_PATH}/bin/flink run -m 10.101.**.**:31805 -py kmeans.py -p 4■ 读写Kafka
我们在Flink Kafka Connector基础上,为Kafka的输入输出包装了Source和Sink组件,让大家读写Kafka数据更加方便。下面是一个从数据读入,数据解析,对数据进行逻辑回归预测,将结果写入Kafka的任务的代码示例:
### 读取数据
data = KafkaSourceStreamOp()\
.setBootstrapServers("localhost:9092")\
.setTopic("iris")\
.setStartupMode("EARLIEST")\
.setGroupId("alink_group")
### 解析JSON数据
json_parser = JsonValueStreamOp()
.setSelectedCol("message")
.setOutputCols(["sepal_length", "sepal_width", "petal_length", "petal_width", "category"])
.setJsonPath(["$.sepal_length", "$.sepal_width", "$.petal_length", "$.petal_width", "$.category"])
data = data.link(json_parser)
### 数据类型转换
data = data.select( \
"CAST(sepal_length AS DOUBLE) AS sepal_length, "
+ "CAST(sepal_width AS DOUBLE) AS sepal_width, "
+ "CAST(petal_length AS DOUBLE) AS petal_length, "
+ "CAST(petal_width AS DOUBLE) AS petal_width, category")
### 读取本地模型文件
model = CsvSourceBatchOp().setFilePath("/path/to/model.csv") \
.setSchemaStr("model_id bigint, model_info string, label_type string")
### 构建逻辑回归预测模型
lr_predictor = LogisticRegressionPredictStreamOp(model) \
.setPredictionCol("pred").setPredictionDetailCol("pred_detail")
### 对数据进行预测
result = data.link(lr_predictor)
### 结果输出到Kafka
sink = KafkaSinkStreamOp() \
.setBootstrapServers("localhost:9092") \
.setDataFormat("json").setTopic("lr_pred")
data.link(sink)
StreamOperator.execute()从代码中可以看出,数据通过KafkaSourceStreamOp组件读入,通过JSON Path解析数据,解析出的值,是String类型,再根据数据的实际类型,使用CAST函数进行类型转换,然后通过加载本地训练好的模型,构建逻辑回归预测组件,对数据进行预测,最后将结果通过KafkaSinkStreamOp组件输出到Kafka。
我们也可以看到,在Alink 1.1.0这个版本中,数据的解析还是有一点麻烦,在本文后面的部分还会介绍对数据解析部分的简化,让整个流程更简洁。
2.Alink version 1.1.1
本章开始,我们将详细介绍Alink 1.1.1版本的一些优化的点,以及重要特性等。
■ 优化枚举类型参数提示
在我们使用算法组件的时候,经常会遇到有些属性是枚举类型的,在Python中,一般是通过字符串输入枚举值,实际在使用的过程中,这些枚举值很难全部记住,经常需要去查询Alink的文档。为了我们编写代码更加顺畅,在新版本中,我们优化了代码的提示信息,我们可以尝试填写一个替代值,虽然会抛异常,但在运行结果中,可以看到枚举值的明确提示。
以卡方筛选算子为例,卡方筛选算子的SelectorType可以填写NumTopFeatures, Percentil,FPR等,是枚举类型变量,我们如果使用'aaa'值代替,看下会有什么效果,代码如下:
### Python代码
selector = ChiSqSelectorBatchOp()\
.setSelectorType("aaa")\
.setSelectedCols(["f_string", "f_long", "f_int", "f_double"])\
.setLabelCol("f_boolean")\
.setNumTopFeatures(2)在Alink 1.1.1之前的版本,会返回下图:
![]()
异常信息中打出SelectorType输出错误的值AAA,但异常信息不明显,也没有指出是哪个参数写错了。
Alink 1.1.1中,则会出现下图的结果:

异常信息中会有哪个参数填写错误,以及会提示可能的值是什么,这样我们使用Alink算子的时候更加便捷。
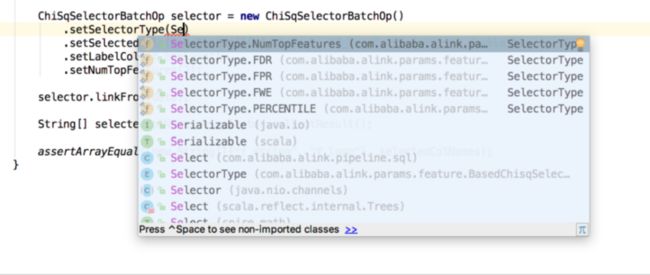
上面是Python代码的枚举类型的错误提示,对于JAVA来说,有代码自动提示,编写时会非常方便:
■ 优化列名参数提示
我们进行机器学习开发,算法中往往会有很多列名参数,列名输错情况很常见,如下图所示:
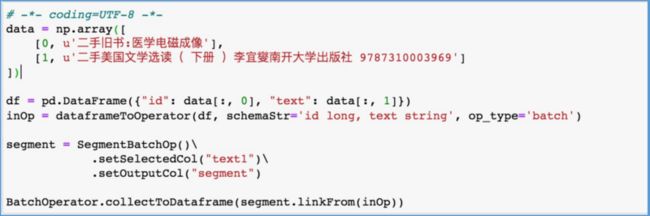
我们可能将text字段错误的写成了text1,在1.1.1版本里,不仅会指出哪列不存在,也会提示最可能的列名,帮助用户做修正,见下图所示。

这样,用户可以更快的定位错误,排查问题。JAVA的行为也相同:

输出提示如下:

■ PyAlink1.1.1改进
- 优化了 DataFrame 和 BatchOperator 互转的性能
我们在使用Python时,更多是用DataFrame来操作数据,在使用PyAlink时,有一个DataFrame向Alink Table转换的过程,转换的速度会直接影响整个任务的执行时长,为了给用户一个比较好的用户体验,我们在转化上面,做了比较大的性能优化。
以下面的示例代码为例:
n = 50000
users = []
for col in range(n):users.append([col] * 2)
df = pd.DataFrame(users)
source = BatchOperator.fromDataframe(df, schemaStr='id int, label int')
source.link(CsvSinkBatchOp().setOverwriteSink(True).setFilePath('temp.csv'))
BatchOperator.execute()之前5W行数据需要约55s,现在只需要 5s,现在100w行数据约 20s就可以转换完成。您可能注意到从5W到100W,这种提升好像不是成程线性关系,这是因为转化的过程中,还包含了一些系统开销。总之,我们在数据转化中,已经尽量的压缩了处理时间,让整个任务运行更快。
- 改进流式组件的print功能,将不会因为数据中有NaN导致作业失败,提高了程序的稳定性。
- Python UDF运行中将自动检测 python3 命令,如果环境中同时有 Python 2和3,将可能因为 python 命令指向 Python 2而导致运行不成功,在Alink 1.1.1版本中,将优先使用python3 来执行 Python UDF。
- useRemoteEnv 将自动检测本机外网 IP,在一般网络配置下,使用 StreamOperator(流式任务) 组件的功能,无需设置 localIp 了。
- 新增组件,将CSV、JSON和KV格式的字符串解析为多列。
下面是一组JOSN格式的测试数据。
{"sepal_width":3.4,"petal_width":0.2,"sepal_length":4.8,"category":"Iris-setosa","petal_length":1.6}
{"sepal_width":4.1,"petal_width":0.1,"sepal_length":5.2,"category":"Iris-setosa","petal_length":1.5}
{"sepal_width":2.8,"petal_width":1.5,"sepal_length":6.5,"category":"Iris-versicolor","petal_length":4.6}
{"sepal_width":3.0,"petal_width":1.8,"sepal_length":6.1,"category":"Iris-virginica","petal_length":4.9}
{"sepal_width":2.9,"petal_width":1.8,"sepal_length":7.3,"category":"Iris-virginica","petal_length":6.3}我们需要将其解析为下图这样的结构化数据。

Alink 1.1.1之前,我们可能需要编写下面这样的代码:
json_parser = JsonValueStreamOp()
.setSelectedCol("message")
.setOutputCols(["sepal_length", "sepal_width", "petal_length", "petal_width", "category"])
.setJsonPath(["$.sepal_length", "$.sepal_width", data = data.link(\
JsonToColumnsStreamOp().setSelectedCol("message").setSchemaStr("sepal_length double, sepal_width double, petal_length double, " + "petal_width double, category string").setReservedCols([]))
"$.petal_length", "$.petal_width", "$.category"])
data = data.link(json_parser)
data = data.select( \
"CAST(sepal_length AS DOUBLE) AS sepal_length, "
+ "CAST(sepal_width AS DOUBLE) AS sepal_width, "
+ "CAST(petal_length AS DOUBLE) AS petal_length, "
+ "CAST(petal_width AS DOUBLE) AS petal_width, category")在Alink 1.1.1版本中,我们添加了JsonToColumnsStreamOp组件,代码变成这样:
data = data.link(\
JsonToColumnsStreamOp().setSelectedCol("message").setSchemaStr("sepal_length double, sepal_width double, petal_length double, " + "petal_width double, category string").setReservedCols([]))我们可以看到,代码精简了很多。
最后,介绍一个日志解析的例子,我们知道,日志的格式没有一个完整的规律,不是一个JSON格式,也不是KV格式,这就需要用现有工具进行组合来解决。
下面是一段日志记录的内容:
66.249.79.35 - - [14/Jun/2018:06:45:24 +0000] "GET /img/20180504/702434-20180302101540805-554506523.jpg HTTP/1.1" 200 10013 "-" "Googlebot-Image/1.0”
66.249.79.35 - - [14/Jun/2018:06:45:25 +0000] "GET /img/20180504/702434-20180302161346635-1714710787.jpg HTTP/1.1" 200 45157 "-" "Googlebot-Image/1.0”
66.249.79.35 - - [14/Jun/2018:06:45:56 +0000] "GET /img/2018/05/21/60662344.jpg HTTP/1.1" 200 14133 "-" "Googlebot-Image/1.0"
54.36.148.129 - - [14/Jun/2018:06:46:01 +0000] "GET /archives/91007 HTTP/1.1" 200 8332 "-" "Mozilla/5.0 (compatible; AhrefsBot/5.2; +http://ahrefs.com/robot/)”
54.36.148.201 - - [14/Jun/2018:06:46:03 +0000] "GET /archives/88741/feed HTTP/1.1" 200 983 "-" "Mozilla/5.0 (compatible; AhrefsBot/5.2; +http://ahrefs.com/robot/)”
5.255.250.200 - - [14/Jun/2018:06:46:03 +0000] "GET /archives/87084 HTTP/1.1" 200 9951 "-" "Mozilla/5.0 (compatible; YandexBot/3.0; +http://yandex.com/bots)”下面是具体解析的代码:
source.select("SUBSTRING(text FROM 1 For POSITION('[' in text)-2) AS part1,"
+"REGEXT_EXTRACT(text,'(\\[)(.*?)(\\])',2) AS log_time,"
+"SUBSTRING(text FROM 2+POSION(']' IN text)) AS part2"
)
.link(
new CsvToColumnBatchOp()
.setSelectCol("part1")
.setFieldDelimiter(" ")
.setSchemaStr("ip string,col1 string,col2 string")
)
.link(
new CsvToColumnBatchOp()
.setSelectCol("part2")
.setFieldDelimiter(" ")
.setSchemaStr("cmd string,response int,bytesize int,col3 string,col4 string")
)
.link(
new CsvToColumnBatchOp()
.setSelectCol("cmd")
.setFieldDelimiter(" ")
.setSchemaStr("req_method string,url String,protocol string")
)
.select("ip,col1,col2,log_time,req_method,url,protocol,response,bytesize,col3,col4")上面的代码思路如下:
- 首先我们将日志根据“[]”将日志划分为三部分,可以使用Flink的SUBSTRING函数,结合正则表达式REGEXT_EXTRACT进行拆分。
- 分别使用CsvToColumnBatchOp按照空格分隔对两边的文本(part1,part2两部分)进行解析,并指定列名。
对cmd这个特殊字段做进一步的解析。 - 最后,选出所有解析出来的列,完成。
Alink相关材料汇总:
- Alink GitHub地址:
https://github.com/alibaba/Alink - Alink系列教程:
https://www.zhihu.com/people/...
以上。Alink 是基于 Flink 的机器学习算法平台,欢迎访问 Alink 的 GitHub 链接获取更多信息。也欢迎加入 Alink 开源用户群进行交流~
▼ 钉钉扫码加入 Alink 技术交流群 ▼
