暑期实习面经(19年3月 至 19年4月)
2019.4.1 蘑菇街+东方财富
项目中是否用到多线程
秒杀系统内部如何实现redis与mysql的同步
对于分布式的了解:
讲讲Java中的长短连接(可以实现以下)
-
长连接、短链接(Socket实现) http长短连接适合的
长:客户端服务端只用一个socket,长期保持
适合于:适合点对点通信,点对点通信;数据库的连接就是长连接;
长连接通过心跳包来实现保活、断线 -
短:每次请求,都新建一个socket
web网站的服务器都是短链接,因为上万个请求要处理,同时都是长连接的话,并发量大。
(已解决)
线程join方法:

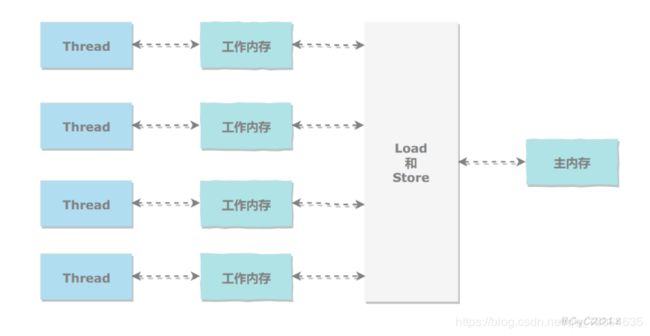
Java内存模型(JMM):
- 作用:定义程序中各个变量的访问规则,在JVM中将变量存储到内存中和从内存中取出变量这样的底层细节。
- 分布:所有的变量都存储在主内存(Main Memory)中;每个线程有自己的工作内存(Working Memory),
工作内存(高速缓存、寄存器) 中保存了该线程使用的变量的主内存的副本拷贝,线程对变量的所有操作都是在工作内存中进行,而不是直接读写主内存的(volatile任然有工作内存,但是内部机制像是主存读取)。不同的线程之间也无法直接访问对方工作内存中的变量,线程之间的传递都需要通过主内存。
建立围绕着“原子性”(操作要么全部执行要么全部不执行)、“可见性”(线程对共享变量修改,其他立马可以看到)、“有序性”
秒杀系统(如何处理高并发问题)
稳:保证秒杀活动顺利完成,即秒杀商品顺利地卖出去
准:数据的一致性
快:说系统的性能要足够高,否则你怎么支撑这么大的流量呢?不光是服务端要做极致的性能优化,而且在整个请求链路上都要做协同的优化,每个地方快一点,整个系统就完美了。
- 业务:卖家查询、买家下订单
- 前端浏览器秒杀页面=》中间代理服务=》后端服务层=》数据库层
- 前端:
1、静态资源缓存
页面静态化
CDN页面缓存,也可以用redis缓存渲染的页面
2、限流方法
使用验证码,防止机器人、爬虫以及分散用户请求
禁止重复提交 :用户提交之后按钮置灰,禁止重复提交
- 服务层:
1.业务分离:将秒杀业务系统和其他业务分离,单独放在高配服务器上,可以集中资源对访问请求抗压。
2.采用消息队列缓存请求:将大流量请求写到消息队列缓存,利用服务器根据自己的处理能力主动到消息缓存队列中抓取任务处理请求,数据库层订阅消息减库存,减库存成功的请求返回秒杀成功,失败的返回秒杀结束。
3.利用缓存应对读请求:对于读多写少业务,大部分请求是查询请求,所以可以读写分离,利用缓存分担数据库压力。
4.利用缓存应对写请求:缓存也是可以应对写请求的,可把数据库中的库存数据转移到Redis缓存中,所有减库存操作都在Redis中进行,然后再通过后台进程把Redis中的用户秒杀请求同步到数据库中。
hashmap 中 key相等怎么办
考察理解hashmap的取值的流程,先通过hashcode找,再由equals去找
重写equals hashcode
Maven的基本命令
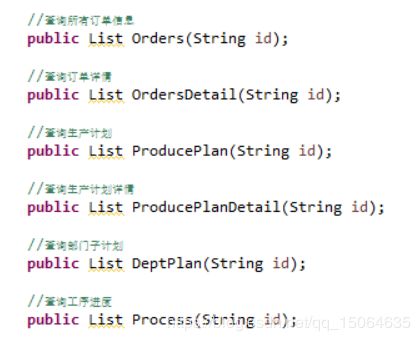
第一个项目搞懂:
-
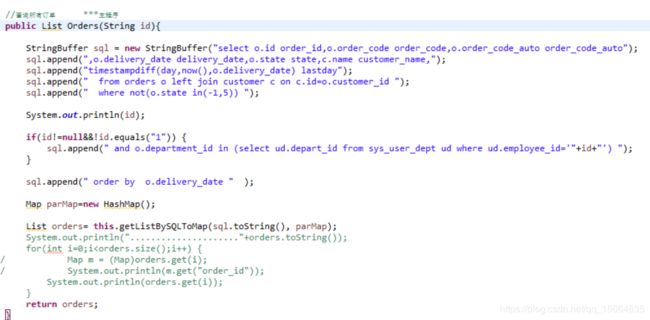
srevice(生产计划,派工单,设备,原材料) 写各种服务接口,包括各种方法
-
ServiceImpl 写各种服务的实现类
-
sql语言写好后通过——getListBySQLToMap来解决
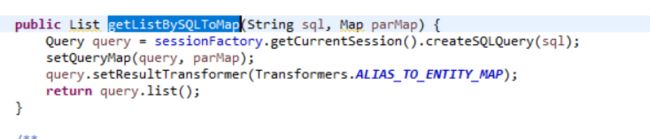
sessionFactory 属于Hibernate对JDBC进行了非常轻量级的对象封装,
session表示应用程序和数据库的一次交互;包含了一般的持久化方法(CRUD);
createSQLQuery 获取 Query对象 query.list获得查找结果 -
——rest文件
注解实现(SpringMVC)
-
@RestController 是@controller和@responsebody的结合,返回的是一个JSON对象 。@controller是返回视图,
-
@Resource
-
@RequestMapping 调用该方法的路径,以及请求方法get、post
分页的实现
写一个 PageQEntity 实体类。

jdbc,mybatis,hibernate各自优缺点及区别:
-
JDBC:
我们平时使用jdbc进行编程,大致需要下面几个步骤:
1,使用jdbc编程需要连接数据库,注册驱动和数据库信息
2,操作Connection,打开Statement对象
3,通过Statement对象执行SQL,返回结果到ResultSet对象
4,使用ResultSet读取数据,然后通过代码转化为具体的POJO对象
5,关闭数据库相关的资源
jdbc的缺点:
一:工作量比较大,需要连接,然后处理jdbc底层事务,处理数据类型,还需要操作Connection,Statement对象和ResultSet对象去拿数据并关闭他们。
二:我们对jdbc编程可能产生的异常进行捕捉处理并正确关闭资源 -
Hibernate:
Hibernate是建立在若干POJO通过xml映射文件(或注解)提供的规则映射到数据库表上的。我们可以通过POJO直接操作数据库的数据,他提供的是一种全表映射的模型。相对而言,Hibernate对JDBC的封装程度还是比较高的,我们已经不需要写SQL,只要使用HQL语言就可以了。
使用Hibernate进行编程有以下好处:
1,消除了代码的映射规则,它全部分离到了xml或者注解里面去配置。
2,无需在管理数据库连接,它也配置到xml里面了。
3,一个会话中不需要操作多个对象,只需要操作Session对象。
4,关闭资源只需要关闭一个Session便可。
这就是Hibernate的优势,在配置了映射文件和数据库连接文件后,Hibernate就可以通过Session操作,非常容易,消除了jdbc带来的大量代码,大大提高了编程的简易性和可读性。Hibernate还提供了级联,缓存,映射,一对多等功能。Hibernate是全表映射,通过HQL去操作pojo进而操作数据库的数据。Hibernate的缺点:
1,全表映射带来的不便,比如更新时需要发送所有的字段。
2,无法根据不同的条件组装不同的SQL。
3,对多表关联和复杂的sql查询支持较差,需要自己写sql,返回后,需要自己将数据封装为pojo。
4,不能有效的支持存储过程。
5,虽然有HQL,但是性能较差,大型互联网系统往往需要优化sql,而hibernate做不到。 -
Mybatis:
为了解决Hibernate的不足,Mybatis出现了,Mybatis是半自动的框架。之所以称它为半自动,是因为它需要手工匹配提供POJO,sql和映射关系,而全表映射的Hibernate只需要提供pojo和映射关系即可。
Mybatis需要提供的映射文件包含了一下三个部分:sql,映射规则,pojo。在Mybatis里面你需要自己编写sql,虽然比Hibernate配置多,但是Mybatis可以配置动态sql,解决了hibernate表名根据时间变化,不同条件下列不一样的问题,同时你也可以对sql进行优化,通过配置决定你的sql映射规则,也能支持存储过程,所以对于一些复杂和需要优化性能的sql查询它就更加方便。Mybatis几乎可以做到jdbc所有能做到的事情。 -
区别
1)从层次上看,JDBC是较底层的持久层操作方式,而Hibernate和MyBatis都是在JDBC的基础上进行了封装使其更加方便程序员对持久层的操作。
2)从功能上看,JDBC就是简单的建立数据库连接,然后创建statement,将sql语句传给statement去执行,如果是有返回结果的查询语句,会将查询结果放到ResultSet对象中,通过对ResultSet对象的遍历操作来获取数据;Hibernate是将数据库中的数据表映射为持久层的Java对象,对sql语句进行修改和优化比较困难;MyBatis是将sql语句中的输入参数和输出参数映射为java对象,sql修改和优化比较方便.
3)从使用上看,如果进行底层编程,而且对性能要求极高的话,应该采用JDBC的方式;如果要对数据库进行完整性控制的话建议使用Hibernate;如果要灵活使用sql语句的话建议采用MyBatis框架。
AJAX请求:
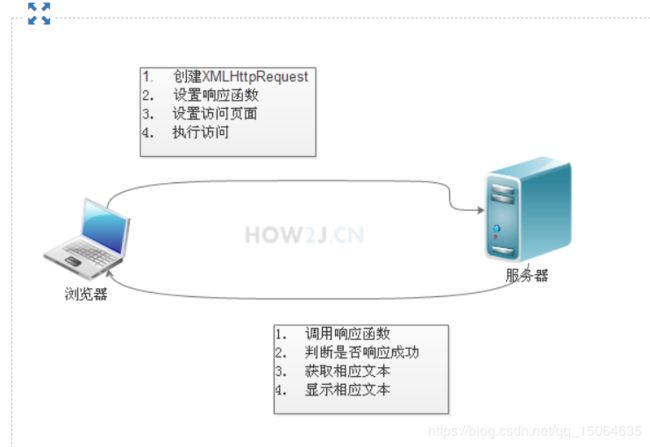
4.2 深圳小公司
框架的认识 :
-
Dao层:数据持久层,负责与数据库连接的任务封装在此。DAO层的设计首先是设计DAO的接口,然后在Spring的配置文件中定义此接口的实现类,然后就可在模块中调用此接口来进行数据业务的处理,而不用关心此接口的具体实现类是哪个类,显得结构非常清晰,DAO层的数据源配置,以及有关数据库连接的参数都在Spring的配置文件中进行配置。 (数据库访问层)
-
Service层:Service层主要负责业务模块的逻辑应用设计。(业务层)
-
Controller层:Controller层负责具体的业务模块流程的控制,在此层里面要调用Serice层的接口来控制业务流程,控制的配置也同样是在Spring的配置文件里面进行(轻业务逻辑——参数检验,可以轻易更换接口类型)
接口属于哪一层:
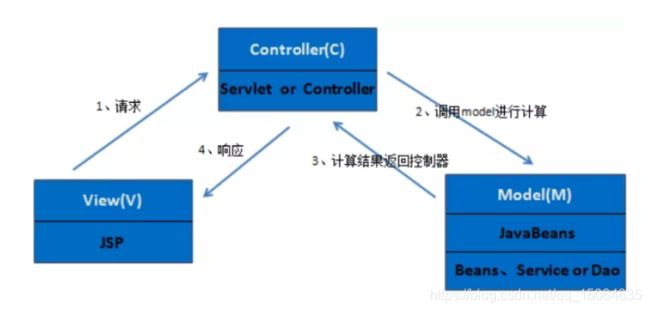
MVC
Model:模型承载数据,并对用户提交请求进行计算。一类:数据承载Bean;一类:业务处理Bean(service、Dao);
View:视图,实现用户交互。(JSP)
Controller:控制器,用于将用户请求转发给相应的Model进行处理,处理model结果向用户响应
SSM(SpringMVC+Spring+MyBatis)与SSH(Struts2+Hibernate+Spring)
SSM下的开发流程:
1.先写实体类entity,定义对象的属性,(可以参照数据库中表的字段来设置,数据库的设计应该在所有编码开始之前)。
2.写Mapper.xml(Mybatis),其中定义你的功能,对应要对数据库进行的那些操作,比如 insert、selectAll、selectByKey、delete、update等。
3.写Mapper.java,将Mapper.xml中的操作按照id映射成Java函数。
4.写Service.java,为控制层提供服务,接受控制层的参数,完成相应的功能,并返回给控制层。
5.写Controller.java,连接页面请求和服务层,获取页面请求的参数,通过自动装配,映射不同的URL到相应的处理函数,并获取参数,对参数进行处理,之后传给服务层。
6.写JSP页面调用,请求哪些参数,需要获取什么数据。
DataBase ===> Entity ===> Mapper.xml ===> Mapper.Java ===> Service.java ===> Controller.java ===> Jsp.
https://juejin.im/post/5a715f4ef265da3e5a57935f
https://blog.csdn.net/qq_34771403/article/details/63694813
- SpringMVC作为view层的实现者,完成用户的请求,其中controller作为整个应用的控制器完成请求及相应。
- Mybatis:作为Dao层的实现者,完成对数据的CRUD
- Spring:以整个应用的大管家,所有的Bean生命周期行为,均由Spring管理,完成对象的创建、初始化、销毁、及对象间关联。
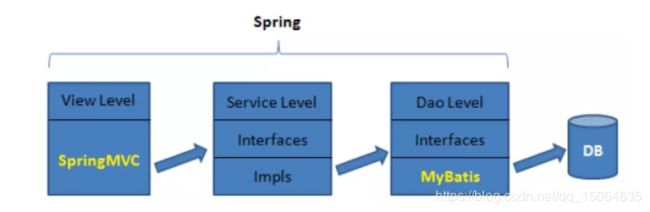
工作流程:
- 用户通过view页面向服务端,提出请求。(表单请求,Ajax请求,超链接请求等待)
- 服务端Controller受到请求后进行解析,找到相应的Model对请求处理
- Model处理完成后,再将结果交给Controller;
- Controller接到处理后,根据结果找到要返回的view页面。页面渲染后
SpringMVC:
1.客户端发送请求到DispacherServlet(分发器)
2.由DispacherServlet控制器查询HanderMapping,找到处理请求的Controller
3.Controller调用业务逻辑处理后,返回ModelAndView
4.DispacherSerclet查询视图解析器,找到ModelAndView指定的视图
5.视图负责将结果显示到客户端
15:struts2和springmvc的区别
答:(1)核心控制器不同。Struts2是filter过滤器,而springmvc是servlet。
(2)控制器实例不同。Springmvc相比strus2要快一些。(理论上)Struts2是基于对象,所以它是多实例的,而springmvc是基于方法的,所以它是单例的,但是应该避免全局变量的修改,这样会导致线程安全问题。
(3)管理方式不同。大部分企业都使用Spring,而Springmvc是spring的一个模块,所以集成更加简单容易,而且提高了全注解的开发形式。而strus2需要采用XML的形式进行配置来进行管理(虽然也可以采用注解,但是公司一般都不会使用)。
(4)参数传递不同。Struts2是通过值栈(ValueStack)进行传递和接受,而Springmvc是通过方法的参数来接受,这样Springmvc更加高效。
(5)学习程度不同。Struts2存在很多技术点,比如拦截器,值栈,以及OGML表达式,学习成本高,而Springmvc比较简单,上手快。
(6)Interrcpter的实现机制不同。Strus2有自己的拦截器的机制,而Springmvc是通过AOP的形式,这样导致strus2的配置文件比springmvc更加庞大。
(7)对于Ajax请求不同。Springmvc可以根据注解@responseBody 来对ajax请求执行返回json格式数据,而strus2需要根据插件进行封装返回数据。
这样设计的好处(Mark)
什么是servlet
是一个接口。运行在 Web 服务器或应用服务器上的程序,它是作为来自 Web 浏览器或其他 HTTP 客户端的请求和 HTTP 服务器上的数据库或应用程序之间的中间层。收集来自网页表单的用户输入,呈现来自数据库或者其他源的记录,还可以动态创建网页。
生命周期:init(初始化);service();destroy()
2019.4.8 蘑菇街二面:
CAS机制除了乐观锁还有什么地方用到,ConcurrentHashMap中CAS怎么用的
ConcurrentHashMap,1.8,内部大量采用CAS机制以及Synchronized,抛弃了Segment,采用Node,volatile属性实现可见性。锁的粒度也变小了,对每一个Node加锁。
CAS举例:在put操作里面,
(1)判断key,value是否为null,是的话抛异常。
(2)table长度为0的话,重新建表。
(3)用CAS机制,判断当前索引的是否为空,空的话直接赋予新的当前值
(4)否则的话,如果当前正在扩容表帮助扩容
(5)否则的话,此时说明有hash冲突,且不需要帮助扩容操作。我们锁住代码块,进行插入操作,可能会遇到,相等的那就覆盖,没有就插到最后;如果是红黑树另一种操作方法。最后如果插入后大于阈值,再变为树结构。
进程线程
- 进程:资源分配的基本单位;线程:独立调度的基本单位
- 拥有资源:进程是资源分配单位,线程可以访问隶属进程
- 调度:同一进程,线程切换不会导致进程切换,不同进程的线程切换会导致进程切换,资料消耗大。
- 系统开销:进程创建销毁,系统为之分配回收资源,线程切换只需保存,设置寄存器内容。
- 进程通信:
管道:适用于具有亲缘关系的父子进程,命名管道也允许没有亲缘关系的
信号:
消息队列:
共享内存:多个进程访问同一快内存,不同进程可以及时看到对方进程中对数据的更新。
信号量:进程间,以及同一进程不同线程的同步手段
套接字:socket - 线程通信:
互斥量:synchronized,lock
信号量:semphare:允许同一时刻多个线程访问同一资源
事件:wait/notify
死锁详细了解
-
死锁:指的两个或多个并发的进程,如果两个进程持有某种资源而又等待着其他进程释放他或他们现在保持着的资源,在未改变这种状态之前都不能向前前进。无限期的阻塞、相互等待的状态。
-
产生的四个必要条件,有一个条件得不到满足就不可能发生死锁:
- 互斥:至少一个资源是非共享模式,一次只允许一个进程访问
- 占有并等待:一个进程本身就占有一个资源,同时还需要其他资源,等待其他进程释放这个资源。
- 非抢占:别人已经有了某个资源,不能因为需要就去抢夺别人的资源
- 循环等待:存在一个进程链,每个进程都占有下一个进程所需的至少一种资源。
死锁的解决策略
-
忽略该问题(鸵鸟算法)
-
检测死锁并恢复
检测方法:
1.每个类型一个资源:深度优先搜索
2.每个类型多个资源:矩阵C+A=E
恢复方法:
1.利用抢占恢复
2.回滚恢复
3.杀死进程恢复 -
破坏四个条件之一,预防死锁:
-
破坏占有且等待:所有进程运行前,必须申请整个过程中所有的资源,申请到了才可以运行;允许只获得初期需要的资源,便开始运行,过程中逐渐释放使用完成的资源,然后再去请求。
-
破坏不可抢占:当一个进程持有了一些资源,请求新资源无法满足,他必须释放已经保持的所有资源。这种方法实现困难,代价很大。
-
破坏循环等待:对资源进行编号,当一个进程占有编号i的资源,下一次只能占有比她大的资源。
- 仔细对资源动态分配,从而避免死锁(比死锁预防的限制要少)银行家算法:
- 有序资源分配法(通过破坏环路条件来实现):将所有资源编号,申请时必须上升的次序。
- 银行家算法:可利用资源向量Available、最大需求矩阵Max、分配矩阵(当前已分配)Allocation、需求矩阵Need=Max-Allocation。request代表进程的一次请求资源量。Finish表示某个进程的状态
安全状态检测算法:(1)不断扫面所有进程,如果finish=false,need 资源请求算法:(1)如果需求request>Need,拒绝(2)如果request>Available,拒绝;(3)以上都不满足分配资源:Available-=request;Need-=request;Allocation+=request。 死锁检测:就是相当于安全状态检测算法 死锁解除:撤销或者挂起一些进程,以便回收一些资源,再将资源分配给处于阻塞状态的线程。进程回退发、 Java中的死锁检测: 无法保证原子性,可在一定程度保证有序,实现了可见性。 物理内存就是实际的内存,在cpu中指的是实际的寻址空间大小,32位就是4G 小程序特点,数据发生变化,前端页面也会直接发生变化 长段文字(TEXT LONGTEXT) 后端解决方案:前端传数据包括(当前页数page,以及每页的个数pagesize),后端(page-1)pagesize到pagepagesize的数据,同时判断总共数据个数,考虑最后一页的情况。 offset(代表需要跳过的个数) = (page-1)*pagesize 具体也有三种方法: 数据缺失:第一次取了20-11数据;期间有人删除了第17条数据,此时再去取第二页会导致第10个数据缺失,只会取1-9的数据。 数据重复:第一次取20-11,此时又增加了一条数据,变为21条,第二次取就会重复取到第11条数据。 时间分片式缓存 游标式分页 一次性下发ID(适用于id列表不会很大的业务场景) 客户端排除 答案见上面 大数相乘思路:第i位*第j位 等于 新的数组的第i+j位的数,先对两个数进行遍历, 最后对res的每一位判断,大于10的话,要进位。进位的要进给前边的。 MD5加密算法 对称加密算法:DES算法,3DES算法,TDEA算法,Blowfish算法,RC5算法,IDEA算法,AES算法。 MD5不可逆,生成信息摘要后,不能通过解析获得原来的内容 currentHashmap: size操作 总结:就是分而治之+hashmap+堆 m位的位数组,k个哈希函数,把temp求k个哈希,同时将结果中的位置值为1 分治+Trie树/hash+小顶堆: 建立最小堆,如果大于最小的,就替代最小的,同时保持最小堆 应用: 海量数据排序:大量数据1000,000,000中的900,000,000个不重复的正整数排序, 海量数据去重:在2.5亿个整数中找出不重复的整数,00表示没有出现,01表示出现一次,10表示出现多次,232∗2=1 GB(这里没有限定整数的范围,所有把所有32位整数都考虑进去) 应用1:某文件中包含一些8位的电话号码,统计出现的号码的个数?(判断有谁出现) 应用2:某文件中包含一些8位的电话号码,统计只出现一次的号码?(判断有谁出现并且指出现1次) 应用3:有两个文件,文件1中有1亿个10位的qq号码,文件2中有5千万个10位qq号码,判断两个文件中重复出现的qq号。 应用4:有两个文件,文件1中有1亿个15位的qq号码,文件2中有5千万个15位的qq号码,判断两个文件中重复出现的qq号。 可读性差 进程资源分配的基本单位;线程独立调度的基本单位 管道(一个进程和一个有共同祖先的进程) socket volatile 死锁的四个必要条件: new :Thread.start Blocked、 Terminated: 终止 wait—— object,线程释放对象锁,notify唤醒,唤醒后获得锁后才能进入就绪队列 线程顺序执行: Runnable接口:重写run方法 run那就是调用了一个普通方法,没有创建新的线程,只有当前一个线程,程序会按照顺序执行; 当多个线程访问同一个对象时,如果不用考虑这些线程在运行时环境下的调度和交替运行,也不需要进行额外的同步,或者在调用方进行任何其他的协调操作,调用这个对象的行为都可以获取正确的结果,那这个对象是线程安全的。 TCP如何实现重传: 重传——
然后用安全状态检测算法,检测这次请求后系统是否安全,安全就生效,不安全就推迟。
Jconsole: (JAVA_HOME/bin目录下)可以连接本地或远程的JVM,查看内存、线程、类、JVM概要。在线程菜单可以检测死锁,查看死锁原因。
Jstack:JDK自带的命令行工具,用于线程Dump分析(Dump文件是进程的内存镜像。保存的是进程的执行状态信息)
1、jps查看进程信息
2、找到要调试的进程号,jstack -l pid 可以得到死锁位置vector 和 arraylist
volatile 到底实现了哪些特性:
物理内存、虚拟内存区别:
虚拟内存:进程运行时4.10 阿里一面:
Spring 底层实现,怎么去做的,怎么去实现的。
如何学习多线程知识
要系统的学习Java知识
基础系统的学习
4.11作业帮一面
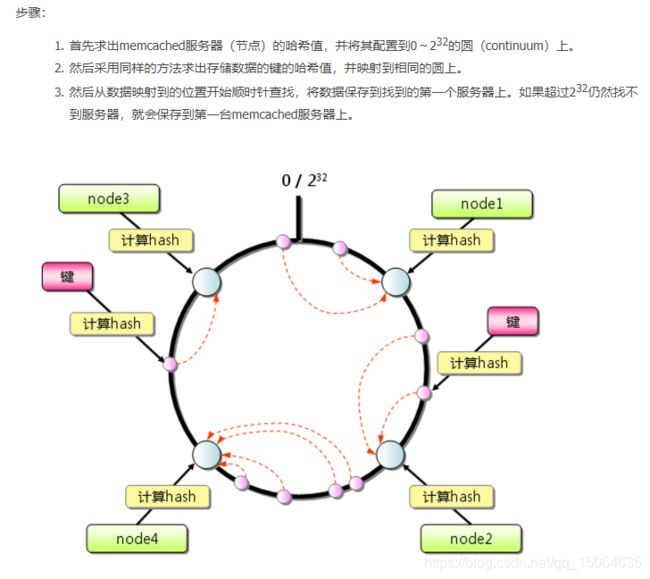
哈希一致性,高并发,redis应用场景
4.12招银网络一面
tomcat服务器怎么跟小程序通信
小程序ajax访问的权限
小程序访问限制,黑客进入
两个人同时改到相同代码,如何解决
数据库的设计有什么感触,范式
博客里面有图片,文字,如何存储
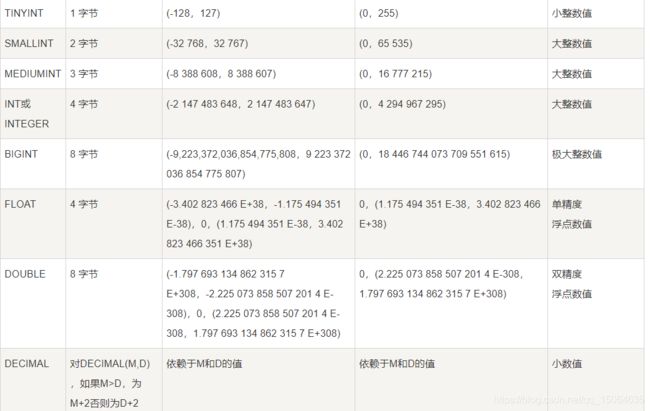
数值类型:
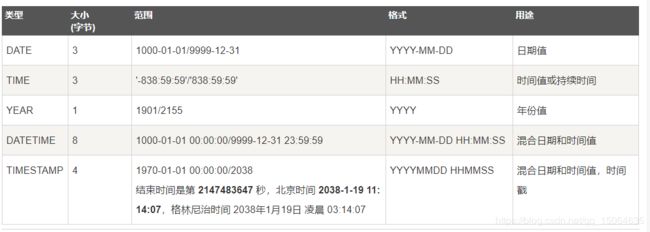
日期和时间类型:
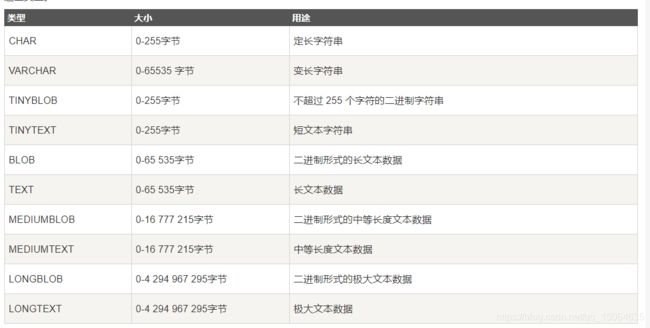
字符串类型:
4.13作业帮二面
数据分页问题
Limit 5; 从第一个数0开始,到4的5个数
Limit 5,5;从5开始的5个数 代替为 Limit 4 offset 3 从行3开始的4行
若果要求返回的行数大于剩下的行数,就返回剩下的行数
Limit优化方案
skip(offset).limit(pagesize)
(1)通过数组进行分页,第一次把所有的数据都取过来,然后每次对数组取索引范围内的值。
(2) sql语句里面实现:select * from student limit #{page},#{pagesize}问题与优化:
解决:
使用缓存,(按时间分片式缓存)。
前端传的数据增加时间戳(timestamp),请求第一页数据时,timestamp =0 。接下来每次将第一步返回的timestamp输出。
后端:对于timestamp为0的话,生成当前时间对应的缓存,并返回前端所需;若timestamp不为0,且缓存不存在,则提示“刷新数据”。若存在,则直接返回。
客户端记录,分页的最后一个数据ID,请求下一页时候告诉上次请求的ID。
优点:避免重复遗漏,不需要计算offset
缺点:只适合按照时间追加的方式简单排序。
第一次请求把所有的ID以及第一页的数据给前端
之后再请求,前端只需要自己去加id,告诉后台需要那些数据
客户端中保存已经加载的id,每次请求玩先去重无限下拉的方法(用户下滑时更新页面)
4.17 小米一面
问道了分页时候,如果有别人操作数据库,导致数据重复或消失
sql问题:1.查找表得到年龄大于20的男性、女性数量 2. group by,查班级年龄,及每个数量的个数,年龄大于5
stringBuffer 、 Stringbuilder 、string 区别
分布式锁,redis 如何实现
SprngBoot了解吗
大数相加和大数相减,大数相乘
for (int i = 0; i < a.length; i++) {
for (int j = 0; j < b.length; j++) {
result[i + j] += (int) (a[i] - '0') * (int) (b[j] - '0');
}
}
4.17 阿里二面
小程序登陆接口设置(Session),如何加密(MD5)
非对称加密算法:RSA、Elgamal、背包算法、Rabin、D-H、ECC。
经典的哈希算法:MD2、MD4、MD5 和 SHA-1(目的是将任意长输入通过算法变为固定长输出,且保证输入变化一点输出都不同,且不能反向解密)CopyOnWrite
hashtable 和 ConcurrentHahsMap
1.volatile 对Node类的属性,保证可见性
2.如果没有hash冲突那么通过CAS机制去添加,如果有的话,再去通过synchronized 更小粒度的锁代码块4.24 OPPO(看看海量数据面试题)
1.海量数据,选出出现次数最多的一个:先分而治之分成1000个,再放入hashmap进行统计,再对所有map中的最大值进行比较。
2.一千万数据,多个重复的,最后只有300万数据,直接全部放入内存一个hashmap中+堆排序
3.1G大小的文件,每一行是一个词
二、多层划分:
bitmap:就是每个bit当作一种情况,1B=8bit,节省大量空间;如果要统计多次出现的可以两2bit,00没有,10多次出现,01出现一次海量数据查找
缺点:误算率;不可删除,删除的也许另一个值也是1
海量数据TOPk
先按哈希方法分成多个小数据集位图法(适用于数据比较密集的):
把每个数据存在一个位上面,方法是数temp,存储在bit[temp/32] 其中第temp%32位设为1。
#define BITSPERWORD 32
#define SHIFT 5
#define MASK 0x1F
#define N 10000000
void set(int i) { //将指定的bit赋1
a[i>>SHIFT] |= (1<<(i & MASK));
} //将i右移动,就是除32,然后求32的余数
void clr(int i) { //将指定的bit清0
a[i>>SHIFT] &= ~(1<<(i & MASK));
}
int test(int i){//取一下存入的值 每5 bit是一组。
return a[i>>SHIFT] & (1<<(i & MASK));
}
1000000000/(8* 1024*1024)=119.2MB空间
先找到最大值,最小值。然后位图法的范围就是最大值减最小值。对于每个数的存储就是该数减去最小值。
8为最大是99 999 999,大约是99M的bit,12.5MB的内存,就可以统计出来出现的号码。
需要扩展一下,可以用两个bit表示一个号码,0代表没有出现过,1代表只出现过1次,2代表至少出现2次。
首先建立10的10次方个大小的位数组(占用内存大约是1.25G),全部初始化为0,读取第一个文件,对应的qq号存放到对应的未知,数值改为1,如果重复出现仍是1.读取完毕第一个文件后,读取第二个文件,对应的位置为1则表示重复出现。
应用4中,qq号码上升为15位的时候,显然内存是不够用了,这个时候怎么办?使用Bloom Filter(布隆过滤器)
位图存储的元素个数虽然比一般做法多,但是存储的元素大小受限于存储空间的大小。位图存储性质:存储的元素个数等于元素的最大值。比如, 1K 字节内存,能存储 8K 个值大小上限为 8K 的元素。(元素值上限为 8K ,这个局限性很大!)比如,要存储值为 65535 的数,就必须要 65535/8=8K 字节的内存。要就导致了位图法根本不适合存 unsigned int 类型的数(大约需要 2^32/8=5 亿字节的内存)。
位图对有符号类型数据的存储,需要 2 位来表示一个有符号元素。这会让位图能存储的元素个数,元素值大小上限减半。 比如 8K 字节内存空间存储 short 类型数据只能存 8K*4=32K 个,元素值大小范围为 -32K~32K 。Trie树(字典树)
4.29 腾讯运营开发
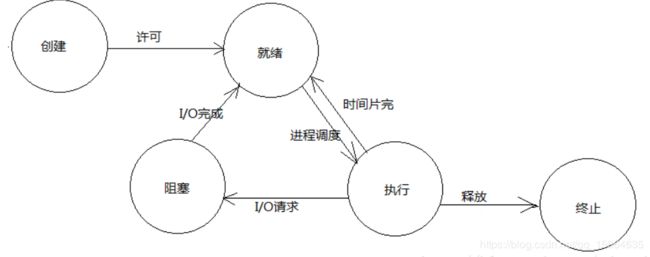
1. 线程和进程的区别
1、拥有资源
2、调度:线程切换创建小于进程
3、线程之间的通信方便,进程之间的通信需要通过IPC
4、多进程程序更加健壮,多线程中一个线程错误,整个进程就错误。
协程:比线程更轻量级,有程序控制2.进程间的通信方式,用过什么样的进程通信方法
命名管道(无亲缘关系的进程通信)
信号:
信号量:进程间,同一进程的线程通信
共享内存:3.线程锁有哪几种方式,如何保证线程安全
sychronized
lock4.防止死锁
占有且申请、资源不可掠夺、资源是互斥的、循环等待条件。5. 线程有哪些状态:(进程)
Runnable :
WAITING、
Time_WAITING
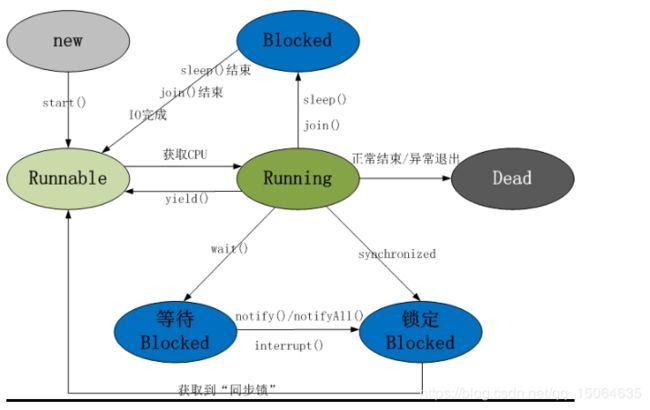
进程
6、wait和sleep,让线程按顺序执行
sleep ——Thread,线程不释放对象锁,唤醒直接进入就绪队列
1、线程池
Executor.newSingleThreadExecutor(),单线程池
2、join方法
里面判断要join的是否还在运行,如果运行的话,其他线程wait,直到他运行完A.start();
A.join();
B.start();
B.join();
C.start();
C.join();
while (isAlive()) {
wait(0);
}
7、实现多线程有什么方法
Callable接口:重写call方法
继承Thread类:重写run方法8、start方法和run方法的区别:
start(不能重复调用):run方法是由java虚拟机调用的,这是会创建一个新的线程,线程如果获得cpu就会运行public static void main(String[] args){
Thread t1 = new Thread(){
@Override
public void run() {
peng();
}
};
//t1.start();
t1.run();
System.out.println("main方法");
}
输出
peng
main方法
//peng
线程安全
9、线程池
10、集合部分,hashtable、hashmap
11 Java反射机制
12 spring mvc 重定向 转发
13 springboot熟悉一下
14、算法:快排
15、mysql 主从配置、怎么保证主机、备机的数据是一致的;mysql里边怎么进行事务提交。实践能力太差。怎么去定位一个查询很慢的问题
5.8 腾讯csig
http相关知识:状态码都是什么。https:对称加密和非对称加密;密钥都是怎么来的;
Mysql了解
TCP、UDP;UDP如何提高可靠性,他的缺点是什么
TCP如何实现重传——tcp可靠传输的贡献力量
快速重传:接收到的比期望的大,就会连续放松期望的ACK,如果连续收到三次相同ACK,直接进行重传。
为什么三次,因为发送过程中可能会乱序,所以两次ack可能是顺序乱了而已,三次的话大概率是丢包,。
+
超时重传(设置时间,超过时间自动进行重传)web安全方面的