Python之正则表达式与JSON(七)
一. 初识正则表达式
1.定义:是一个特殊的字符序列,可以帮助检测一个字符串是否与我们所设定的字符序列相匹配。
2.作用:可以实现快速检索文本、实现替换文本的操作。
3.场景:
1、检测一串数字是否是电话号码
2、检测一个字符串是否符合e-mail格式
3、把一个文本里指定的单词替换为另外一个单词
4.例子:
查看传入的字符串是否还有Python
(1)
a = 'C|C++|Java|Python'
print(a.index('Python') > -1)
或者
print('Python' in a)(2)
用正则表达式处理:
import re
a = 'C|C++|Java|Python'
r = re.findall('Python',a)
if len(r) > 0:
print('字符串中包含Python')
else:
print('No')5.语法
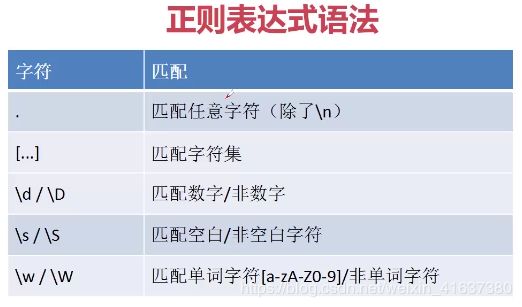


二. 元字符与普通字符
1.‘Python’普通字符,'\d'元字符。正则表达式就是由一系列普通字符和元字符组成的。
2.例子:
提取字符串中所有的数字:\d :表示所有数字
import re
a = 'C2C++4Java7Python6'
r = re.findall('\d',a)
print(r)
#结果:
['2', '4', '7', '6']
提取字符串中所有的非数字:
import re
a = 'C2C++4Java7Python6'
r = re.findall('\D',a) #\D为非数字
print(r)
三.字符集
例子:
1.中间一个字符是c或者f的单词:[ ]:字符集,或关系
普通字符定界,确定某一个小段。该例子中a[cf]c,中括号外面的a和c就是普通字符定界
import re
s = 'abc,acc,adc,aec,afc,ahc'
r = re.findall('a[cf]c',s)
print(r)
#结果:
['acc', 'afc']
2.中间一个字符不是c或者f的单词:^:取反操作
import re
s = 'abc,acc,adc,aec,afc,ahc'
r = re.findall('a[^cf]c',s)
print(r)
#结果:
['abc', 'adc', 'aec', 'ahc']
3.利用字符顺序省略字符,匹配c,d,e,f:- :省略中间字符
import re
s = 'abc,acc,adc,aec,afc,ahc'
r = re.findall('a[c-f]c',s)
print(r)
#结果:
['acc','adc','aec','afc']
四. 概括字符集
1.\d可以用[0-9]表示:
import re
a = 'python1111java678php'
r = re.findall('[0-9]',a)
print(r)
2.\w匹配所有的数字和字符:
\w只能匹配单词字符,也就是[A-Za-z0-9_]
\W只匹配非单词字符,如空格、&、\n、\r、\t等都为非单词字符
import re
a = 'python1111&java___678php'
r = re.findall('\w',a)
print(r)结果:
![]()
3.\s代表空白字符:空格、\n、\r等
\S代表非空白字符
import re
a = 'python1111&_java678 \nph\rp'
r = re.findall('\s',a)
print(r)
#[' ', ' ', '\n', '\r']
常用的概括字符集:\d \D \w \W \s \S
. :匹配除换行符\n之外的其他所有字符
五.数量词
1.匹配三个字母的单词:
import re
a = 'python1111 java678php'
r = re.findall('[a-z]{3}',a)
print(r)
#['pyt', 'hon', 'jav', 'php']
2.匹配完整的单词:
import re
a = 'python1111 java678php'
r = re.findall('[a-z]{3,6}',a)
print(r)
#['python', 'java', 'php']利用数量词{数量}多次重复
六. 贪婪与非贪婪
数量词有贪婪和非贪婪之分,一般来说Python倾向于贪婪的匹配方式。
1.{数量} ?变成非贪婪模式
2.例子:
import re
a = 'python1111 java678php'
r = re.findall('[a-z]{3,6}?',a)
print(r)
#['pyt', 'hon', 'jav', 'php']
七. 匹配0次1次或者无限多次
1.用 * 对它前面的字符匹配0次或者无限多次:
import re
a = 'pytho0python1pythonn2'
r = re.findall('python*',a)
print(r)
#['pytho', 'python', 'pythonn']
2.用+匹配一次或者无限多次:
import re
a = 'pytho0python1pythonn2'
r = re.findall('python+',a)
print(r)
#['python', 'pythonn']
3.用?匹配0次或者一次:
import re
a = 'pytho0python1pythonn2'
r = re.findall('python?',a)
print(r)
#['pytho', 'python', 'python']注意:多出来的n会被去掉,因为读到python时就满足了
用?来进行去重复的操作。
贪婪与非贪婪中的{3,6}?和 python? 时的问号用法不一样。
八. 边界匹配
1.例子:
QQ号的位数是否符合4-8位:
import re
qq = '10000004531'
r = re.findall('^\d{4,8}$',qq)
print(r)
#[]^ $ 组成边界匹配符
^从字符串开头开始匹配
$从字符串末尾开始匹配
000$:最后三位是000
^000:开始三位是000
九. 组
1.例子:
python字符串是否重复出现三次:
import re
a = 'pythonpythonpythonpythonpython'
r = re.findall('(python){3}',a)
print(r)2.
一个括号对应一组。
[]里的字符是或关系
()里的字符是且关系
十. 匹配模式参数
1.例子:
忽略大小写:
import re
a = 'pythonC#\nJavaPHP'
r = re.findall('c#.{1}',a,re.I|re.S)
print(r)
#['c#\n']2.
re.I:忽略大小写,多个模式之间用|,这里的|是且的关系
re.S:匹配包括\n在内的任意字符
十一. re.sub正则替换

0:把所有匹配的都替换,1:只有第一个匹配到的被替换
1.例子:
(1)查找并替换:
import re
a = 'PythonC#JavaPHP'
r = re.sub('C#','GO',a)
print(r)
#PythonGOJavaPHPimport re
a = 'PythonC#\nJavaPHP'
r = re.sub('C#','GO',a,0) #0:把所有的C#换成GO,1:只有第一个匹配到的被替换成GO
print(r)
#PythonGO
#JavaPHP
(2)常规替换可以使用replace函数:
import re
a = 'PythonC#\nJavaPHP'
a = a.replace('C#','GO') #是sub的简化版
print(a)(3)sub强大的地方在于其第二个参数可以是一个函数:
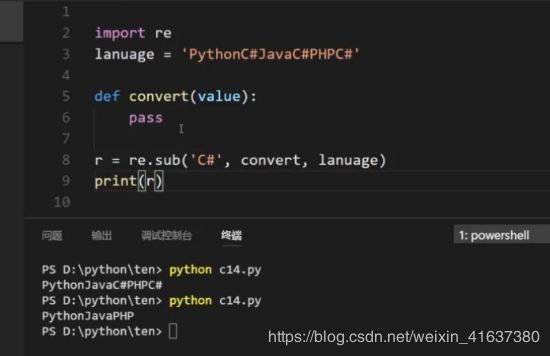
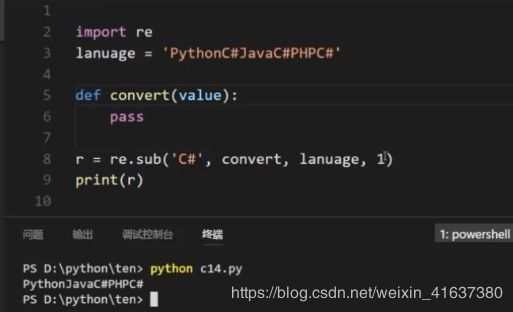
import re
def convert(value):
matched = value.group() #从对象中提取字符串
return '!!' + matched + '!!'
a = 'PythonC#JavaPHP'
r = re.sub('C#',convert,a)
print(r)
#Python!!C#!!JavaPHPsub匹配到第一个结果会传到convert函数中去,返回的结果是新的字符串用来替换匹配到的词。
十二.把函数作为参数传递
例子:
找出数字,大于等于6的替换成9,小于6的替换成0:
import re
def convert(value):
matched = value.group()
if int(matched) >= 6:
return '9'
else:
return '0'
s = 'A8C3721D86'
r = re.sub('\d',convert,s)
print(r)
#A9C0900D99
十三.search与match函数
1.
match:从字符串开始的地方开始匹配(首字母开始匹配)。
search:搜索整个字符串,直到找到第一个满足的结果并返回。
match和search返回的是对象,且只匹配一次,不会像findall一样匹配所有。
2.
import re
s = 'A8C3721D86'
r = re.match('\d',s)
print(r)
r1 = re.search('\d',s)
print(r1)
#None
#3.
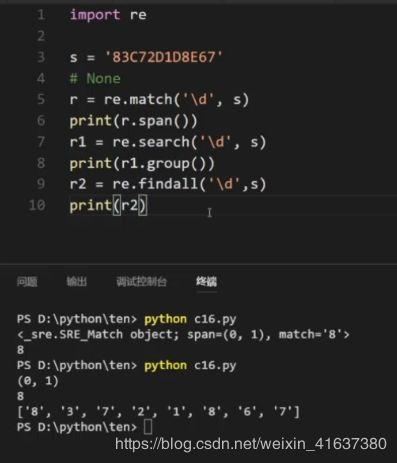
小结:
r.span()返回位置,(第一个数字表示找到的该数字的前一个位置,第二个数字表示找到的该数字的位置)
r.group()返回字符串
十四. group分组
1.提取life和python之间的字符:
(1)
import re
s = 'life is short,i use python'
r = re.search('life(.*)python',s)
print(r.group(1))
#is short,i usegroup(0)是完整匹配结果
group(1)是完整匹配结果的内部分组
(2)
用findall做:
import re
s = 'life is short,i use python'
r = re.findall('life(.*)python',s)
print(r)
#['is short,i use']
2.group(1)是第一个分组,group(2)是第二个分组:
import re
s = 'life is short,i use python,i love python'
r = re.search('life(.*)python(.*)python',s)
print(r.group(0))
print(r.group(1))
print(r.group(2))
#life is short,i use python,i love python
#is short,i use
#,i love
3.r.groups()返回除完整以外的结果:
import re
s = 'life is short,i use python,i love python'
r = re.search('life(.*)python(.*)python',s)
print(r.groups())
#(' is short,i use ', ',i love ')
总结:
一些关于学习正则的建议
python绝大多数用在爬虫上,需要用到正则表达式
搜索 '常用正则表达式' 并加以分析
一. 理解JSON
1.JavaScript Object Notation, 是一种轻量级(与XML比)的数据交换格式。
2.字符串是JSON的表现形式,符合JSON格式的字符串就是JSON字符串。
3.优势:
- 易于阅读
- 易于解析
- 网络传输效率高
适合做跨语言交换数据。
4.

二. 反序列化:字符串到语言的数据结构的过程
json内用双引号,则外部用单引号表示字符串
1.利用python内部的json解析JSON数据:
import json
json_str = '{"name":"tai","age":23}' #json内用双引号,则外部用单引号表示str
student = json.loads(json_str)
print(type(student))
print(student)
print(student['name'])
print(student['age'])
# #解析出来是字典
#{'name': 'tai', 'age': 23}
#tai
#23 同样的JSON字符串,不同的语言会装换成不同的类型。其中对应到Python中是字典类型。
2.解析JSON数组:
import json
json_str = '[{"name":"tai","age":23,"flag":false},{"name":"tai","age":23}]'
student=json.loads(json_str)
print(type(student))
print(student)
# #数组转成了列表
#[{'name': 'tai', 'age': 23, 'flag': False}, {'name': 'tai', 'age': 23}] #列表中两个元素,每个元素是一个字典
字符串->语言下某一数据结构的过程:反序列化
总结:json到Python对应的数据转换类型

三.序列化
1. 序列化:字典到字符串
import json
student = [
{"name":"tai","age":23,"flag":False},
{"name":"tai","age":23}
]
json_str = json.dumps(student)
print(type(json_str))
print(json_str)
#
#[{"name": "tai", "age": 23, "flag": false}, {"name": "tai", "age": 23}]
四.小谈JSON、JSON对象与JSON字符串
JSON某种程度上是与Javascript平级的语言。
JSON对象、JSON、JSON字符串。
A语言数据类型 —JSON(中间数据类型)—> B语言数据类型
JSON有自己的数据类型,虽然和Javascript的数据类型差不多。
REST服务的标准格式,使用JSON。
参考:https://blog.csdn.net/qq_36329973/article/details/81144881